 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Temporal Dictionary Ensemble (TDE) Classifier for Time Series Classification
May 09, 2021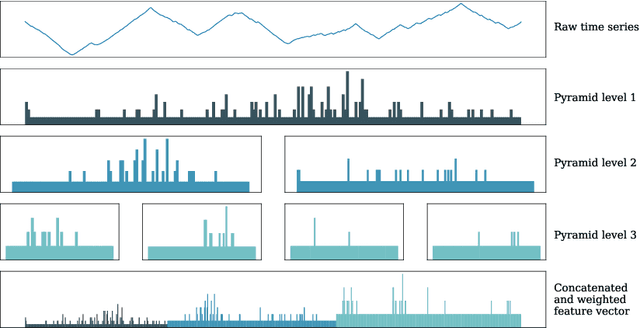


Using bag of words representations of time series is a popular approach to time series classification. These algorithms involve approximating and discretising windows over a series to form words, then forming a count of words over a given dictionary. Classifiers are constructed on the resulting histograms of word counts. A 2017 evaluation of a range of time series classifiers found the bag of symbolic-fourier approximation symbols (BOSS) ensemble the best of the dictionary based classifiers. It forms one of the components of hierarchical vote collective of transformation-based ensembles (HIVE-COTE), which represents the current state of the art. Since then, several new dictionary based algorithms have been proposed that are more accurate or more scalable (or both) than BOSS. We propose a further extension of these dictionary based classifiers that combines the best elements of the others combined with a novel approach to constructing ensemble members based on an adaptive Gaussian process model of the parameter space. We demonstrate that the temporal dictionary ensemble (TDE) is more accurate than other dictionary based approaches. Furthermore, unlike the other classifiers, if we replace BOSS in HIVE-COTE with TDE, HIVE-COTE is significantly more accurate. We also show this new version of HIVE-COTE is significantly more accurate than the current best deep learning approach, a recently proposed hybrid tree ensemble and a recently introduced competitive classifier making use of highly randomised convolutional kernels. This advance represents a new state of the art for time series classification.
* arXiv admin note: text overlap with arXiv:1911.12008
HIVE-COTE 2.0: a new meta ensemble for time series classification
Apr 15, 2021



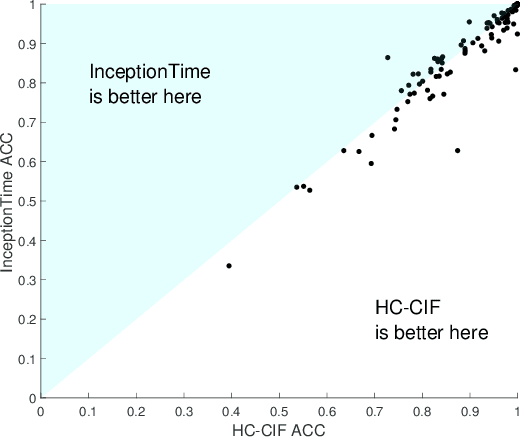
The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. HIVE-COTE forms its ensemble from classifiers of multiple domains, including phase-independent shapelets, bag-of-words based dictionaries and phase-dependent intervals. Since it was first proposed in 2016, the algorithm has remained state of the art for accuracy on the UCR time series classification archive. Over time it has been incrementally updated, culminating in its current state, HIVE-COTE 1.0. During this time a number of algorithms have been proposed which match the accuracy of HIVE-COTE. We propose comprehensive changes to the HIVE-COTE algorithm which significantly improve its accuracy and usability, presenting this upgrade as HIVE-COTE 2.0. We introduce two novel classifiers, the Temporal Dictionary Ensemble (TDE) and Diverse Representation Canonical Interval Forest (DrCIF), which replace existing ensemble members. Additionally, we introduce the Arsenal, an ensemble of ROCKET classifiers as a new HIVE-COTE 2.0 constituent. We demonstrate that HIVE-COTE 2.0 is significantly more accurate than the current state of the art on 112 univariate UCR archive datasets and 26 multivariate UEA archive datasets.
The Canonical Interval Forest (CIF) Classifier for Time Series Classification
Aug 20, 2020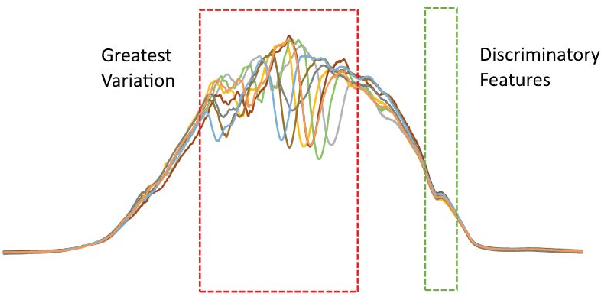

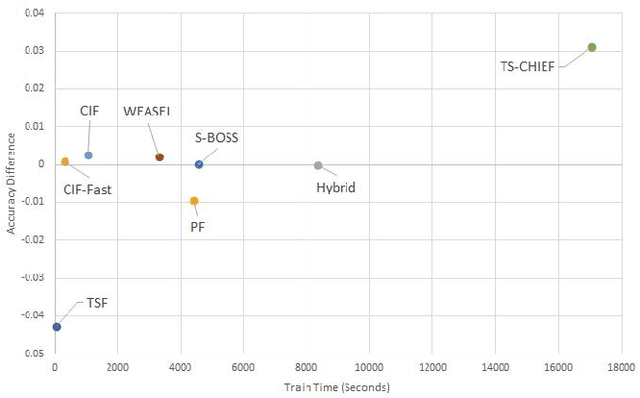
Time series classification (TSC) is home to a number of algorithm groups that utilise different kinds of discriminatory patterns. One of these groups describes classifiers that predict using phase dependant intervals. The time series forest (TSF) classifier is one of the most well known interval methods, and has demonstrated strong performance as well as relative speed in training and predictions. However, recent advances in other approaches have left TSF behind. TSF originally summarises intervals using three simple summary statistics. The `catch22' feature set of 22 time series features was recently proposed to aid time series analysis through a concise set of diverse and informative descriptive characteristics. We propose combining TSF and catch22 to form a new classifier, the Canonical Interval Forest (CIF). We outline additional enhancements to the training procedure, and extend the classifier to include multivariate classification capabilities. We demonstrate a large and significant improvement in accuracy over both TSF and catch22, and show it to be on par with top performers from other algorithmic classes. By upgrading the interval-based component from TSF to CIF, we also demonstrate a significant improvement in the hierarchical vote collective of transformation-based ensembles (HIVE-COTE) that combines different time series representations. HIVE-COTE using CIF is significantly more accurate on the UCR archive than any other classifier we are aware of and represents a new state of the art for TSC.
Detecting Electric Devices in 3D Images of Bags
Apr 25, 2020



The aviation and transport security industries face the challenge of screening high volumes of baggage for threats and contraband in the minimum time possible. Automation and semi-automation of this procedure offers the potential to increase security by detecting more threats and improve the customer experience by speeding up the process. Traditional 2D x-ray images are often extremely difficult to examine due to the fact that they are tightly packed and contain a wide variety of cluttered and occluded objects. Because of these limitations, major airports are introducing 3D x-ray Computed Tomography (CT) baggage scanning. We investigate whether we can automate the process of detecting electric devices in these 3D images of luggage. Detecting electrical devices is of particular concern as they can be used to conceal explosives. Given the massive volume of luggage that needs to be screened for this threat, the best way to automate the detection is to first filter whether a bag contains an electric device or not, and if it does, to identify the number of devices and their location. We present an algorithm, Unpack, Predict, eXtract, Repack (UXPR), which involves unpacking through segmenting the data at a range of scales using an algorithm known as the Sieve, predicting whether a segment is electrical or not based on the histogram of voxel intensities, then repacking the bag by ensembling the segments and predictions to identify the devices in bags. Through a range of experiments using data provided by ALERT (Awareness and Localization of Explosives-Related Threats) we show that this system can find a high proportion of devices with unsupervised segmentation if a similar device has been seen before, and shows promising results for detecting devices not seen at all based on the properties of its constituent parts.
A tale of two toolkits, report the third: on the usage and performance of HIVE-COTE v1.0
Apr 25, 2020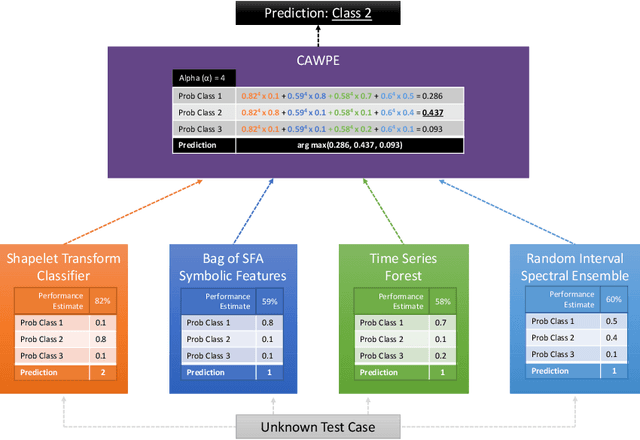
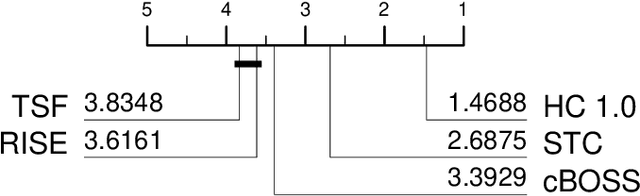
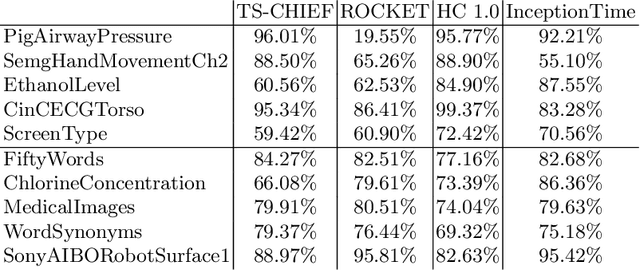

The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. Since it was first proposed in 2016, the algorithm has undergone some minor changes and there is now a configurable, scalable and easy to use version available in two open source repositories. We present an overview of the latest stable HIVE-COTE, version 1.0, and describe how it differs to the original. We provide a walkthrough guide of how to use the classifier, and conduct extensive experimental evaluation of its predictive performance and resource usage. We compare the performance of HIVE-COTE to three recently proposed algorithms.
A tale of two toolkits, report the second: bake off redux. Chapter 1. dictionary based classifiers
Nov 27, 2019

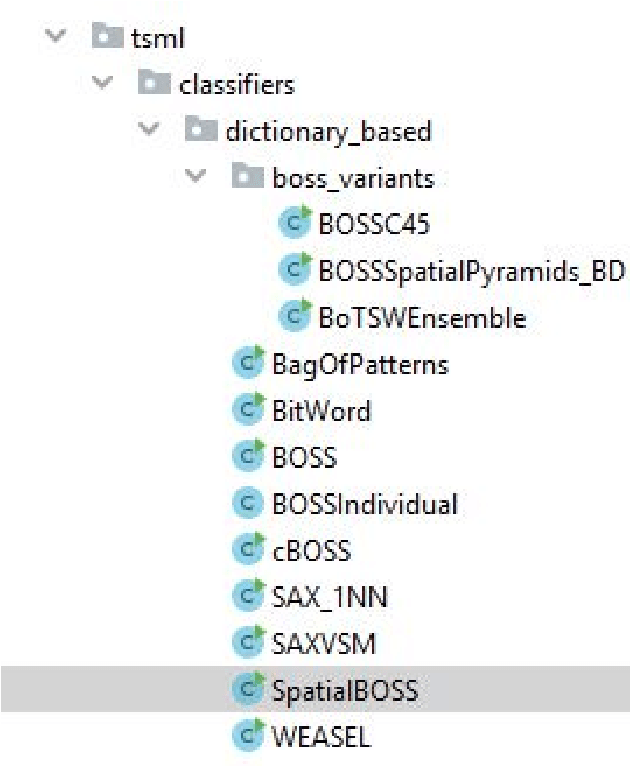

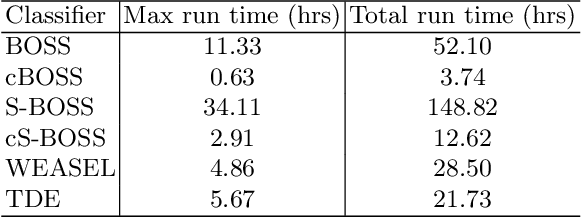
Time series classification (TSC) is the problem of learning labels from time dependent data. One class of algorithms is derived from a bag of words approach. A window is run along a series, the subseries is shortened and discretised to form a word, then features are formed from the histogram of frequency of occurrence of words. We call this type of approach to TSC dictionary based classification. We compare four dictionary based algorithms in the context of a wider project to update the great time series classification bakeoff, a comparative study published in 2017. We experimentally characterise the algorithms in terms of predictive performance, time complexity and space complexity. We find that we can improve on the previous best in terms of accuracy, but this comes at the cost of time and space. Alternatively, the same performance can be achieved with far less cost. We review the relative merits of the four algorithms before suggesting a path to possible improvement.
Can automated smoothing significantly improve benchmark time series classification algorithms?
Nov 01, 2018
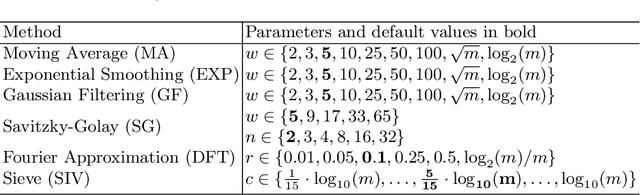
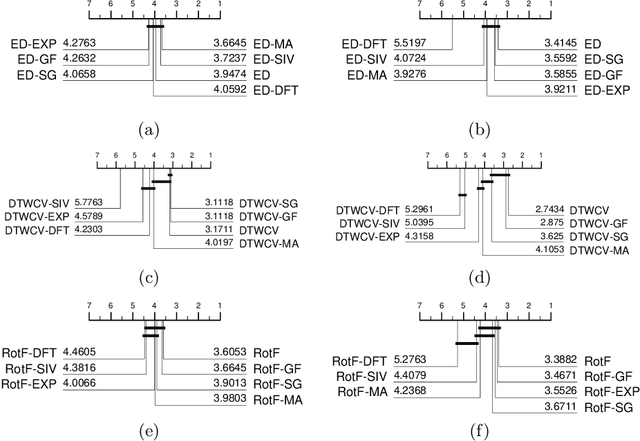

tl;dr: no, it cannot, at least not on average on the standard archive problems. We assess whether using six smoothing algorithms (moving average, exponential smoothing, Gaussian filter, Savitzky-Golay filter, Fourier approximation and a recursive median sieve) could be automatically applied to time series classification problems as a preprocessing step to improve the performance of three benchmark classifiers (1-Nearest Neighbour with Euclidean and Dynamic Time Warping distances, and Rotation Forest). We found no significant improvement over unsmoothed data even when we set the smoothing parameter through cross validation. We are not claiming smoothing has no worth. It has an important role in exploratory analysis and helps with specific classification problems where domain knowledge can be exploited. What we observe is that the automatic application does not help and that we cannot explain the improvement of other time series classification algorithms over the baseline classifiers simply as a function of the absence of smoothing.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018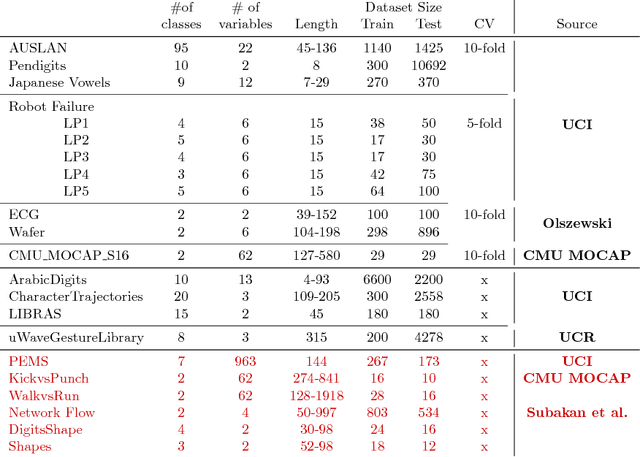
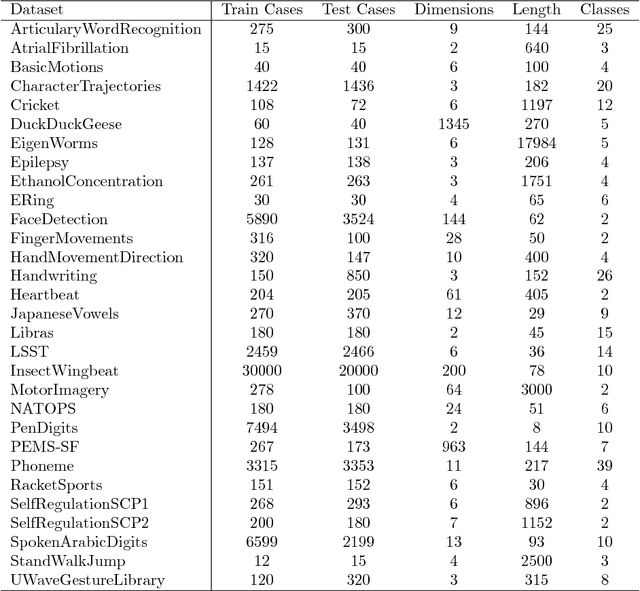
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.
From BOP to BOSS and Beyond: Time Series Classification with Dictionary Based Classifiers
Sep 18, 2018

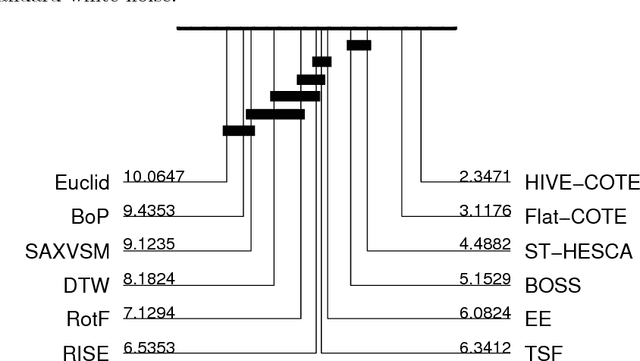
A family of algorithms for time series classification (TSC) involve running a sliding window across each series, discretising the window to form a word, forming a histogram of word counts over the dictionary, then constructing a classifier on the histograms. A recent evaluation of two of this type of algorithm, Bag of Patterns (BOP) and Bag of Symbolic Fourier Approximation Symbols (BOSS) found a significant difference in accuracy between these seemingly similar algorithms. We investigate this phenomenon by deconstructing the classifiers and measuring the relative importance of the four key components between BOP and BOSS. We find that whilst ensembling is a key component for both algorithms, the effect of the other components is mixed and more complex. We conclude that BOSS represents the state of the art for dictionary based TSC. Both BOP and BOSS can be classed as bag of words approaches. These are particularly popular in Computer Vision for tasks such as image classification. Converting approaches from vision requires careful engineering. We adapt three techniques used in Computer Vision for TSC: Scale Invariant Feature Transform; Spatial Pyramids; and Histrogram Intersection. We find that using Spatial Pyramids in conjunction with BOSS (SP) produces a significantly more accurate classifier. SP is significantly more accurate than standard benchmarks and the original BOSS algorithm. It is not significantly worse than the best shapelet based approach, and is only outperformed by HIVE-COTE, an ensemble that includes BOSS as a constituent module.
The Heterogeneous Ensembles of Standard Classification Algorithms (HESCA): the Whole is Greater than the Sum of its Parts
Oct 25, 2017
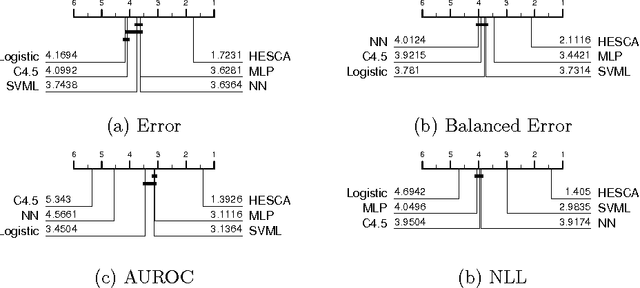


Building classification models is an intrinsically practical exercise that requires many design decisions prior to deployment. We aim to provide some guidance in this decision making process. Specifically, given a classification problem with real valued attributes, we consider which classifier or family of classifiers should one use. Strong contenders are tree based homogeneous ensembles, support vector machines or deep neural networks. All three families of model could claim to be state-of-the-art, and yet it is not clear when one is preferable to the others. Our extensive experiments with over 200 data sets from two distinct archives demonstrate that, rather than choose a single family and expend computing resources on optimising that model, it is significantly better to build simpler versions of classifiers from each family and ensemble. We show that the Heterogeneous Ensembles of Standard Classification Algorithms (HESCA), which ensembles based on error estimates formed on the train data, is significantly better (in terms of error, balanced error, negative log likelihood and area under the ROC curve) than its individual components, picking the component that is best on train data, and a support vector machine tuned over 1089 different parameter configurations. We demonstrate HESCA+, which contains a deep neural network, a support vector machine and two decision tree forests, is significantly better than its components, picking the best component, and HESCA. We analyse the results further and find that HESCA and HESCA+ are of particular value when the train set size is relatively small and the problem has multiple classes. HESCA is a fast approach that is, on average, as good as state-of-the-art classifiers, whereas HESCA+ is significantly better than average and represents a strong benchmark for future research.