 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposable Core-sets for Diversity Approximation on Multi-Dataset Streams
Aug 10, 2023Core-sets refer to subsets of data that maximize some function that is commonly a diversity or group requirement. These subsets are used in place of the original data to accomplish a given task with comparable or even enhanced performance if biases are removed. Composable core-sets are core-sets with the property that subsets of the core set can be unioned together to obtain an approximation for the original data; lending themselves to be used for streamed or distributed data. Recent work has focused on the use of core-sets for training machine learning models. Preceding solutions such as CRAIG have been proven to approximate gradient descent while providing a reduced training time. In this paper, we introduce a core-set construction algorithm for constructing composable core-sets to summarize streamed data for use in active learning environments. If combined with techniques such as CRAIG and heuristics to enhance construction speed, composable core-sets could be used for real time training of models when the amount of sensor data is large. We provide empirical analysis by considering extrapolated data for the runtime of such a brute force algorithm. This algorithm is then analyzed for efficiency through averaged empirical regression and key results and improvements are suggested for further research on the topic.
HIVE-COTE 2.0: a new meta ensemble for time series classification
Apr 15, 2021



The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. HIVE-COTE forms its ensemble from classifiers of multiple domains, including phase-independent shapelets, bag-of-words based dictionaries and phase-dependent intervals. Since it was first proposed in 2016, the algorithm has remained state of the art for accuracy on the UCR time series classification archive. Over time it has been incrementally updated, culminating in its current state, HIVE-COTE 1.0. During this time a number of algorithms have been proposed which match the accuracy of HIVE-COTE. We propose comprehensive changes to the HIVE-COTE algorithm which significantly improve its accuracy and usability, presenting this upgrade as HIVE-COTE 2.0. We introduce two novel classifiers, the Temporal Dictionary Ensemble (TDE) and Diverse Representation Canonical Interval Forest (DrCIF), which replace existing ensemble members. Additionally, we introduce the Arsenal, an ensemble of ROCKET classifiers as a new HIVE-COTE 2.0 constituent. We demonstrate that HIVE-COTE 2.0 is significantly more accurate than the current state of the art on 112 univariate UCR archive datasets and 26 multivariate UEA archive datasets.
Benchmarking Multivariate Time Series Classification Algorithms
Jul 26, 2020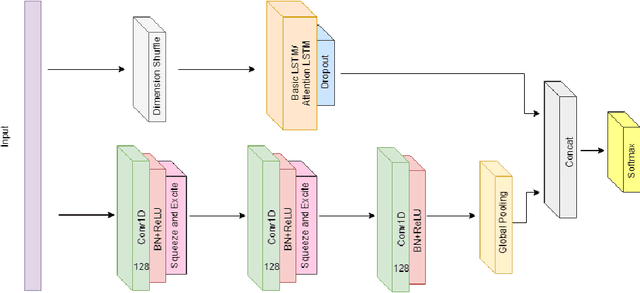
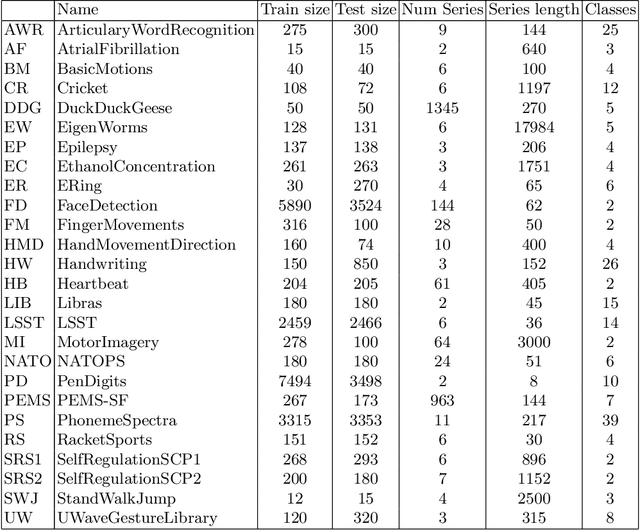

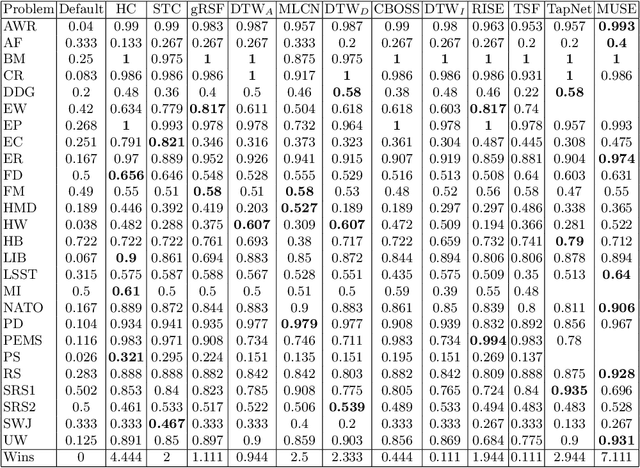
Time Series Classification (TSC) involved building predictive models for a discrete target variable from ordered, real valued, attributes. Over recent years, a new set of TSC algorithms have been developed which have made significant improvement over the previous state of the art. The main focus has been on univariate TSC, i.e. the problem where each case has a single series and a class label. In reality, it is more common to encounter multivariate TSC (MTSC) problems where multiple series are associated with a single label. Despite this, much less consideration has been given to MTSC than the univariate case. The UEA archive of 30 MTSC problems released in 2018 has made comparison of algorithms easier. We review recently proposed bespoke MTSC algorithms based on deep learning, shapelets and bag of words approaches. The simplest approach to MTSC is to ensemble univariate classifiers over the multivariate dimensions. We compare the bespoke algorithms to these dimension independent approaches on the 26 of the 30 MTSC archive problems where the data are all of equal length. We demonstrate that the independent ensemble of HIVE-COTE classifiers is the most accurate, but that, unlike with univariate classification, dynamic time warping is still competitive at MTSC.
A tale of two toolkits, report the third: on the usage and performance of HIVE-COTE v1.0
Apr 25, 2020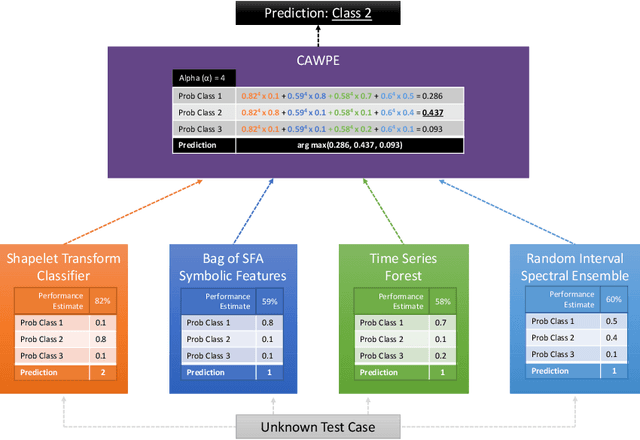
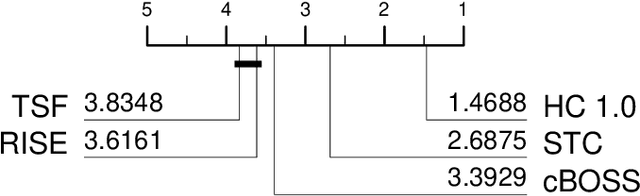
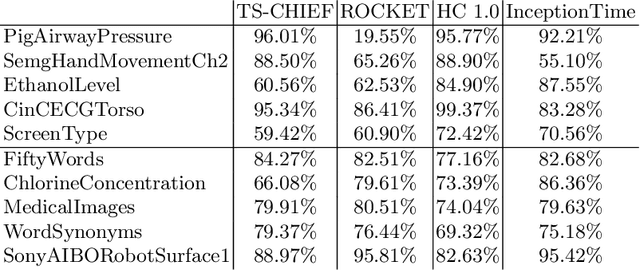

The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. Since it was first proposed in 2016, the algorithm has undergone some minor changes and there is now a configurable, scalable and easy to use version available in two open source repositories. We present an overview of the latest stable HIVE-COTE, version 1.0, and describe how it differs to the original. We provide a walkthrough guide of how to use the classifier, and conduct extensive experimental evaluation of its predictive performance and resource usage. We compare the performance of HIVE-COTE to three recently proposed algorithms.
WHAM!: Extending Speech Separation to Noisy Environments
Jul 02, 2019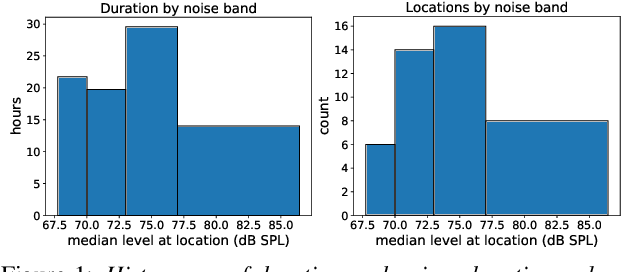
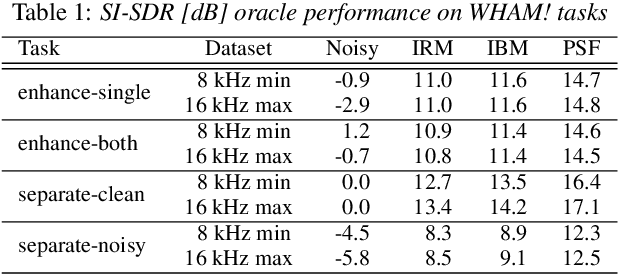
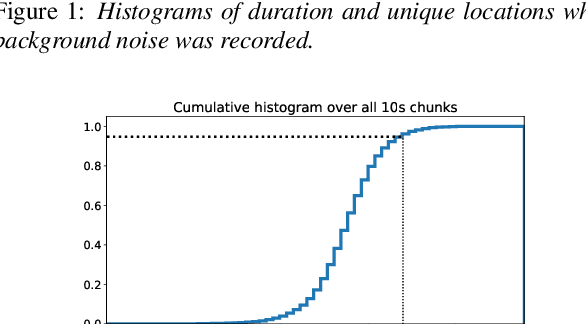
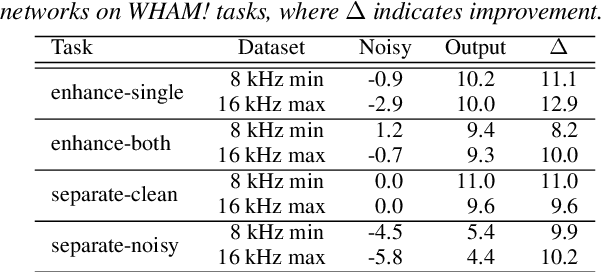
Recent progress in separating the speech signals from multiple overlapping speakers using a single audio channel has brought us closer to solving the cocktail party problem. However, most studies in this area use a constrained problem setup, comparing performance when speakers overlap almost completely, at artificially low sampling rates, and with no external background noise. In this paper, we strive to move the field towards more realistic and challenging scenarios. To that end, we created the WSJ0 Hipster Ambient Mixtures (WHAM!) dataset, consisting of two speaker mixtures from the wsj0-2mix dataset combined with real ambient noise samples. The samples were collected in coffee shops, restaurants, and bars in the San Francisco Bay Area, and are made publicly available. We benchmark various speech separation architectures and objective functions to evaluate their robustness to noise. While separation performance decreases as a result of noise, we still observe substantial gains relative to the noisy signals for most approaches.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018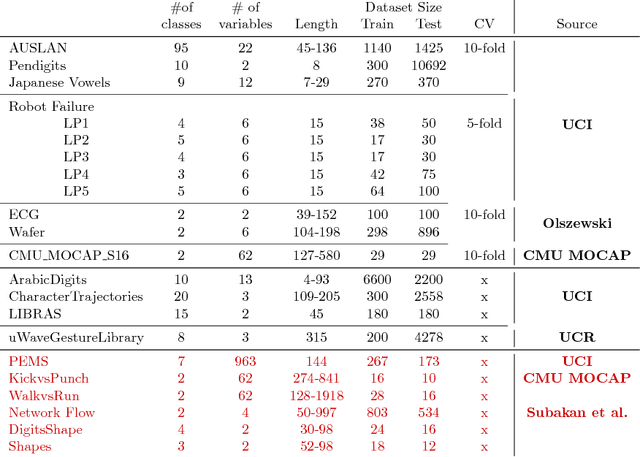
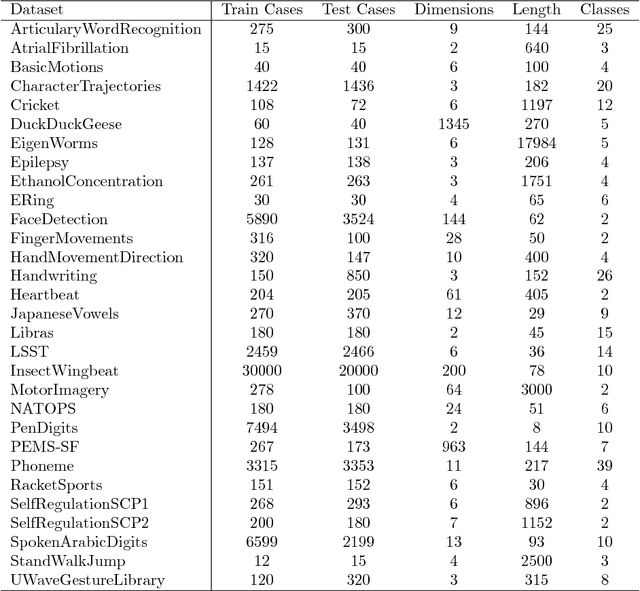
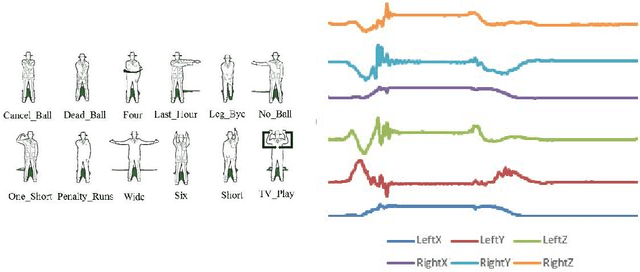
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.