 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
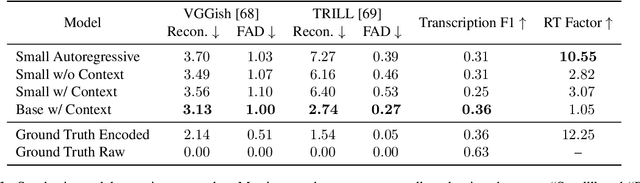
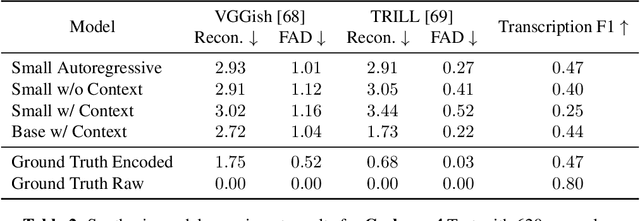
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
SingSong: Generating musical accompaniments from singing
Jan 30, 2023
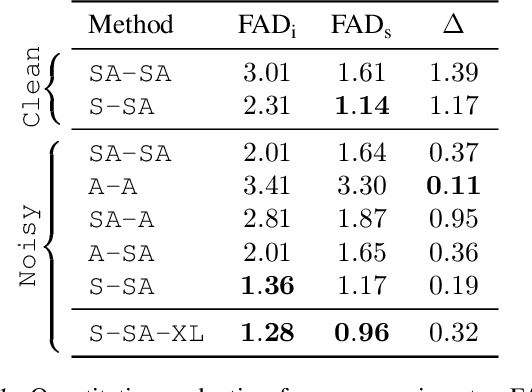
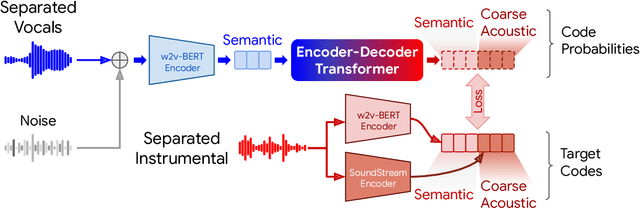
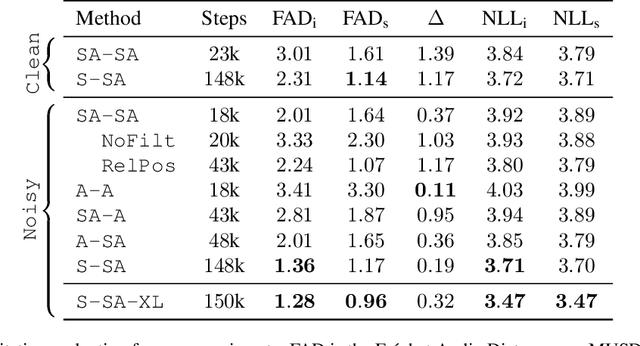
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022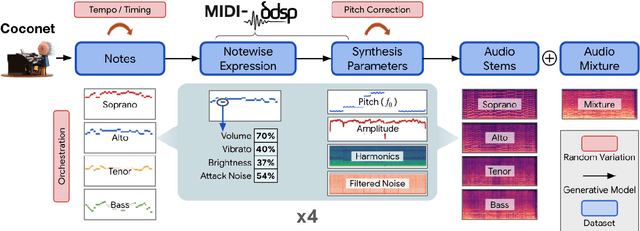
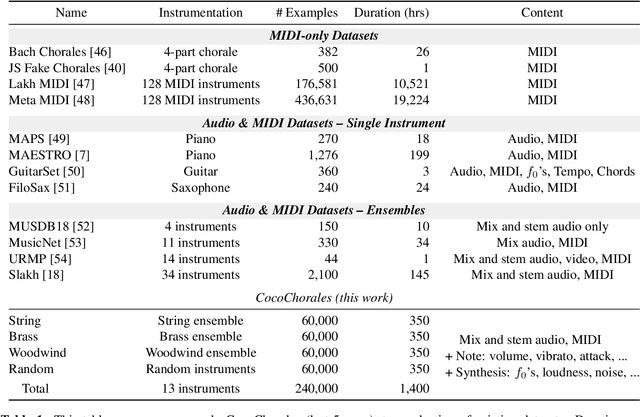
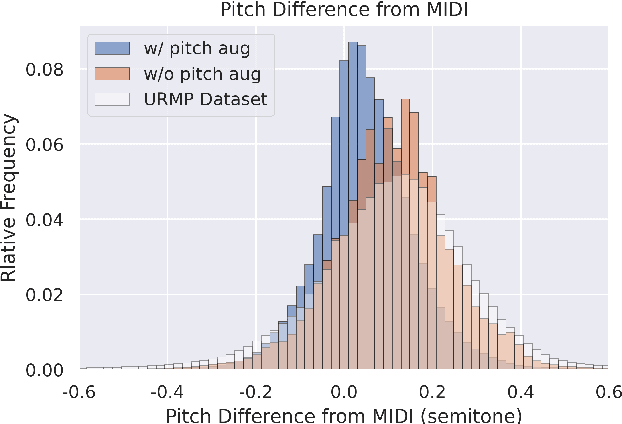
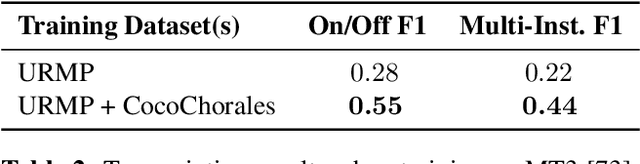
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
Music Separation Enhancement with Generative Modeling
Aug 26, 2022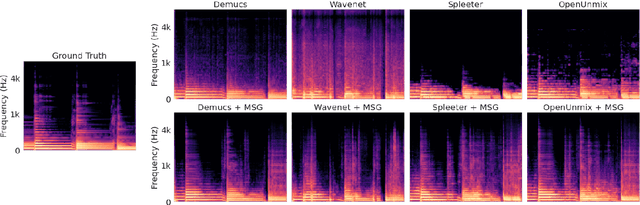
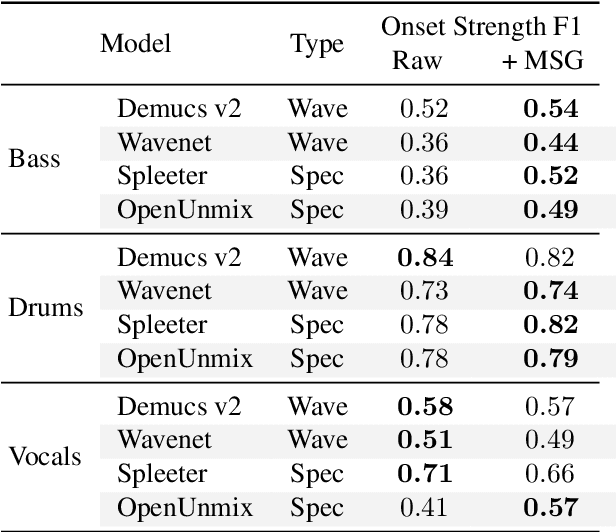
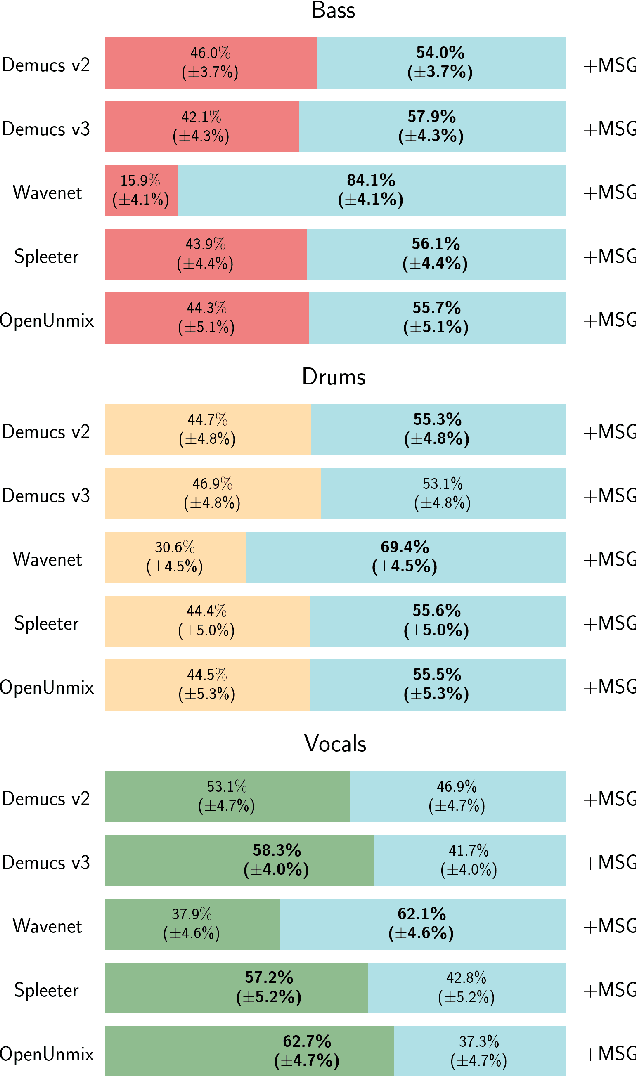
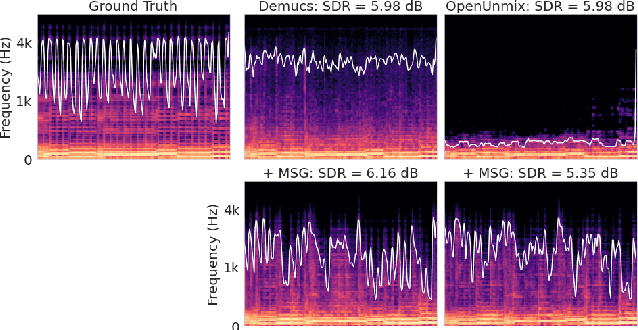
Despite phenomenal progress in recent years, state-of-the-art music separation systems produce source estimates with significant perceptual shortcomings, such as adding extraneous noise or removing harmonics. We propose a post-processing model (the Make it Sound Good (MSG) post-processor) to enhance the output of music source separation systems. We apply our post-processing model to state-of-the-art waveform-based and spectrogram-based music source separators, including a separator unseen by MSG during training. Our analysis of the errors produced by source separators shows that waveform models tend to introduce more high-frequency noise, while spectrogram models tend to lose transients and high frequency content. We introduce objective measures to quantify both kinds of errors and show MSG improves the source reconstruction of both kinds of errors. Crowdsourced subjective evaluations demonstrate that human listeners prefer source estimates of bass and drums that have been post-processed by MSG.
Multi-instrument Music Synthesis with Spectrogram Diffusion
Jun 11, 2022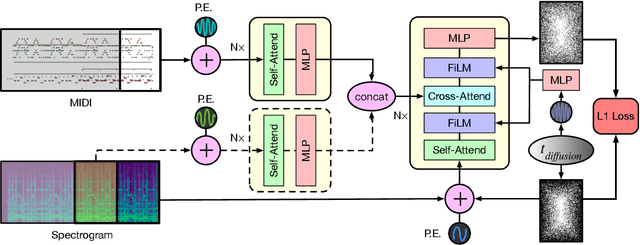

An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on all of music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fr\'echet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
Improving Source Separation by Explicitly Modeling Dependencies Between Sources
Mar 28, 2022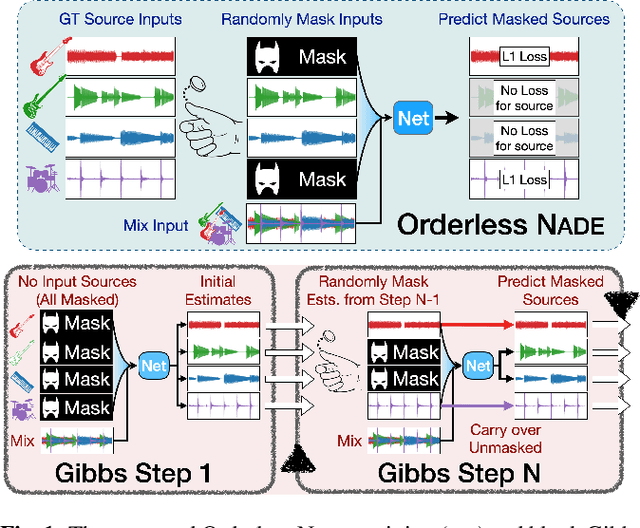
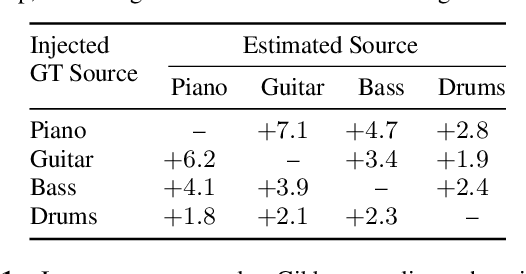
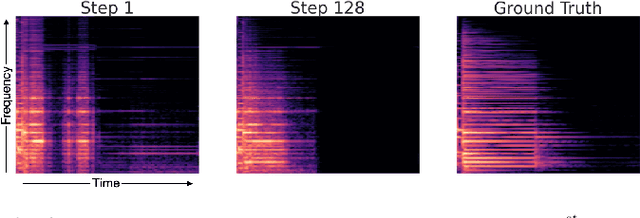
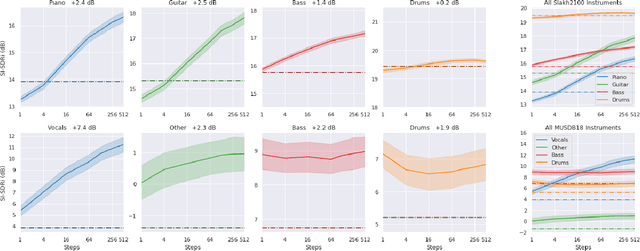
We propose a new method for training a supervised source separation system that aims to learn the interdependent relationships between all combinations of sources in a mixture. Rather than independently estimating each source from a mix, we reframe the source separation problem as an Orderless Neural Autoregressive Density Estimator (NADE), and estimate each source from both the mix and a random subset of the other sources. We adapt a standard source separation architecture, Demucs, with additional inputs for each individual source, in addition to the input mixture. We randomly mask these input sources during training so that the network learns the conditional dependencies between the sources. By pairing this training method with a block Gibbs sampling procedure at inference time, we demonstrate that the network can iteratively improve its separation performance by conditioning a source estimate on its earlier source estimates. Experiments on two source separation datasets show that training a Demucs model with an Orderless NADE approach and using Gibbs sampling (up to 512 steps) at inference time strongly outperforms a Demucs baseline that uses a standard regression loss and direct (one step) estimation of sources.
MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling
Dec 17, 2021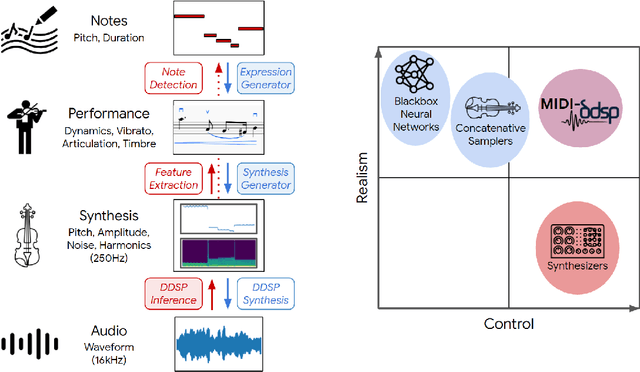
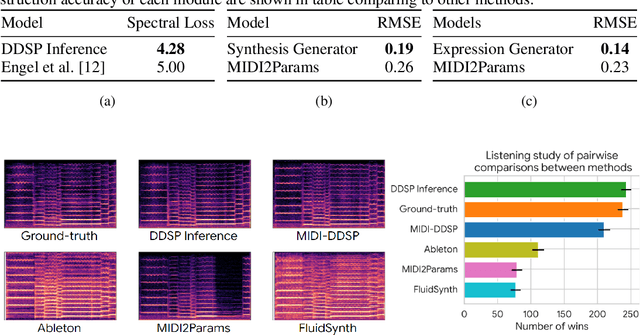
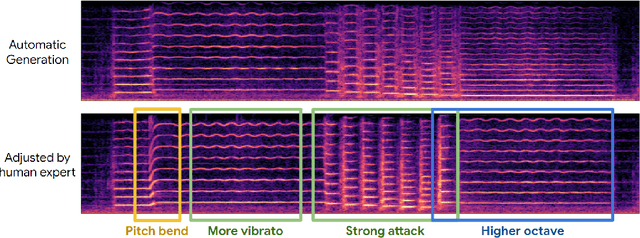
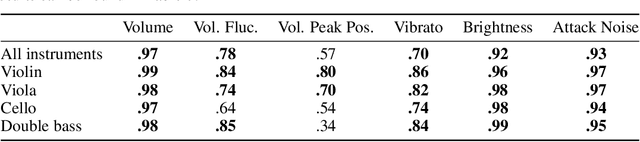
Musical expression requires control of both what notes are played, and how they are performed. Conventional audio synthesizers provide detailed expressive controls, but at the cost of realism. Black-box neural audio synthesis and concatenative samplers can produce realistic audio, but have few mechanisms for control. In this work, we introduce MIDI-DDSP a hierarchical model of musical instruments that enables both realistic neural audio synthesis and detailed user control. Starting from interpretable Differentiable Digital Signal Processing (DDSP) synthesis parameters, we infer musical notes and high-level properties of their expressive performance (such as timbre, vibrato, dynamics, and articulation). This creates a 3-level hierarchy (notes, performance, synthesis) that affords individuals the option to intervene at each level, or utilize trained priors (performance given notes, synthesis given performance) for creative assistance. Through quantitative experiments and listening tests, we demonstrate that this hierarchy can reconstruct high-fidelity audio, accurately predict performance attributes for a note sequence, independently manipulate the attributes of a given performance, and as a complete system, generate realistic audio from a novel note sequence. By utilizing an interpretable hierarchy, with multiple levels of granularity, MIDI-DDSP opens the door to assistive tools to empower individuals across a diverse range of musical experience.
MT3: Multi-Task Multitrack Music Transcription
Nov 10, 2021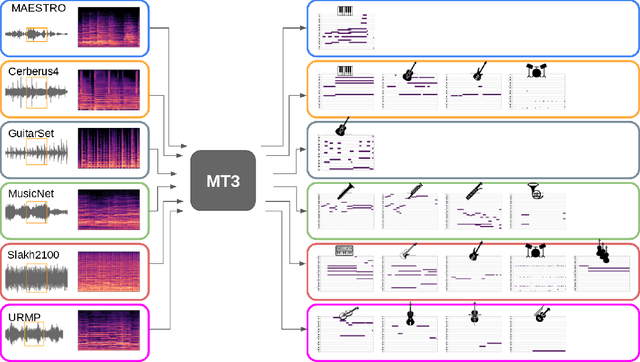

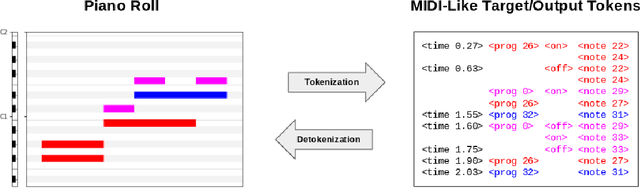
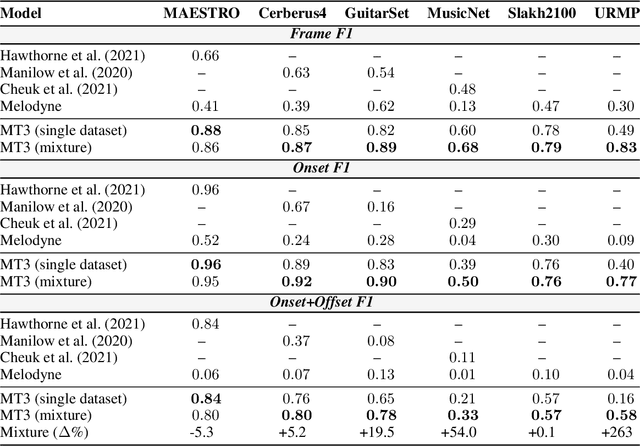
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
Deep Learning Tools for Audacity: Helping Researchers Expand the Artist's Toolkit
Oct 28, 2021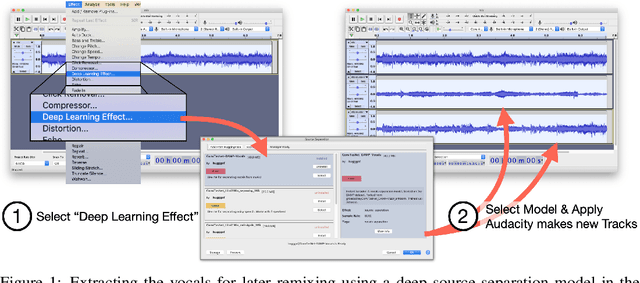
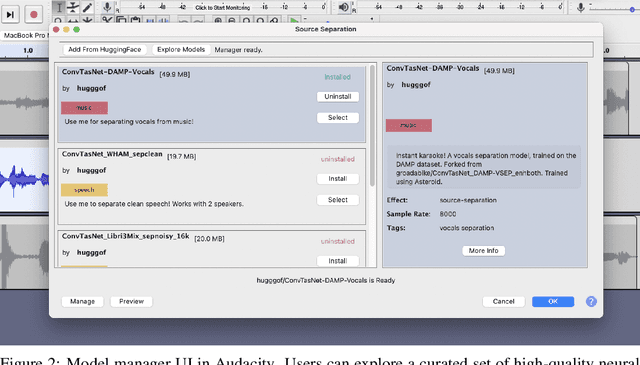
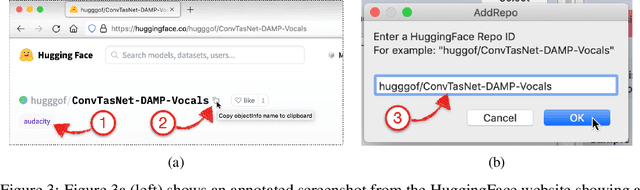
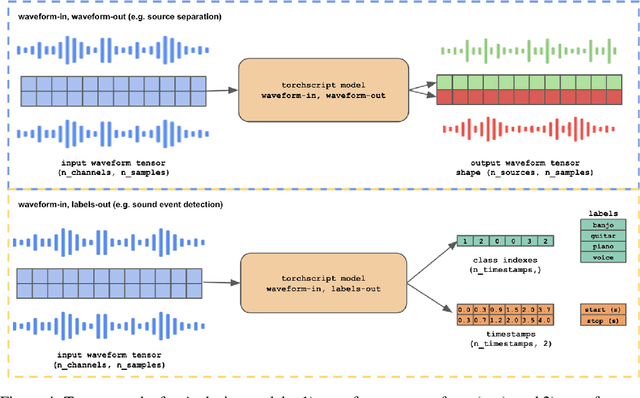
We present a software framework that integrates neural networks into the popular open-source audio editing software, Audacity, with a minimal amount of developer effort. In this paper, we showcase some example use cases for both end-users and neural network developers. We hope that this work fosters a new level of interactivity between deep learning practitioners and end-users.
Unsupervised Source Separation By Steering Pretrained Music Models
Oct 25, 2021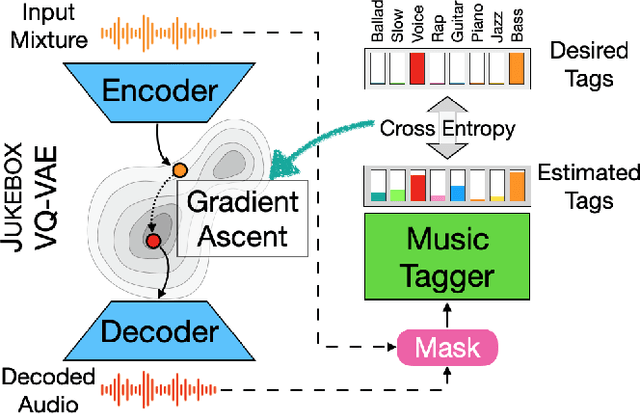
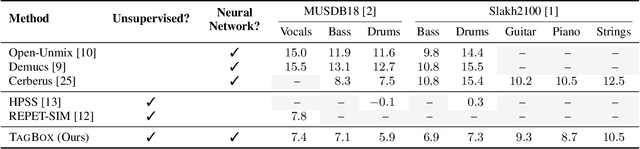
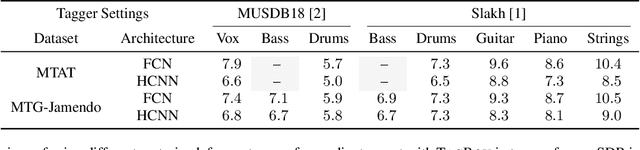
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model's latent space to produce separated sources. We use OpenAI's Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.