 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
V2Meow: Meowing to the Visual Beat via Music Generation
May 11, 2023
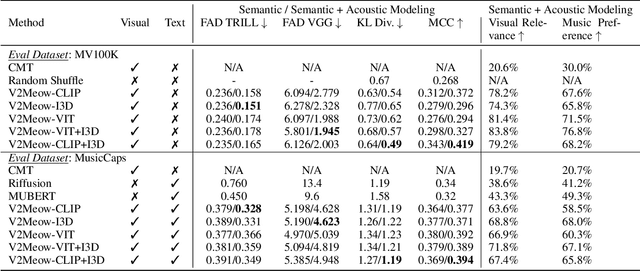

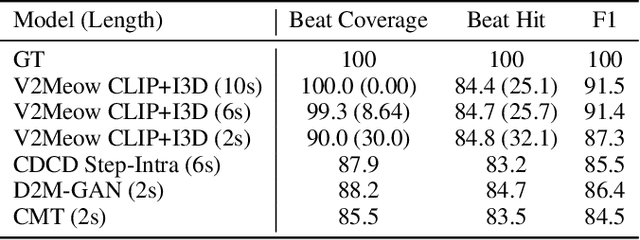
Generating high quality music that complements the visual content of a video is a challenging task. Most existing visual conditioned music generation systems generate symbolic music data, such as MIDI files, instead of raw audio waveform. Given the limited availability of symbolic music data, such methods can only generate music for a few instruments or for specific types of visual input. In this paper, we propose a novel approach called V2Meow that can generate high-quality music audio that aligns well with the visual semantics of a diverse range of video input types. Specifically, the proposed music generation system is a multi-stage autoregressive model which is trained with a number of O(100K) music audio clips paired with video frames, which are mined from in-the-wild music videos, and no parallel symbolic music data is involved. V2Meow is able to synthesize high-fidelity music audio waveform solely conditioned on pre-trained visual features extracted from an arbitrary silent video clip, and it also allows high-level control over the music style of generation examples via supporting text prompts in addition to the video frames conditioning. Through both qualitative and quantitative evaluations, we demonstrate that our model outperforms several existing music generation systems in terms of both visual-audio correspondence and audio quality.
Learning Translation Quality Evaluation on Low Resource Languages from Large Language Models
Feb 07, 2023



Learned metrics such as BLEURT have in recent years become widely employed to evaluate the quality of machine translation systems. Training such metrics requires data which can be expensive and difficult to acquire, particularly for lower-resource languages. We show how knowledge can be distilled from Large Language Models (LLMs) to improve upon such learned metrics without requiring human annotators, by creating synthetic datasets which can be mixed into existing datasets, requiring only a corpus of text in the target language. We show that the performance of a BLEURT-like model on lower resource languages can be improved in this way.
SingSong: Generating musical accompaniments from singing
Jan 30, 2023
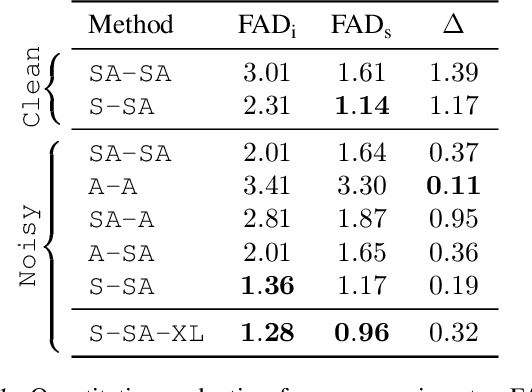
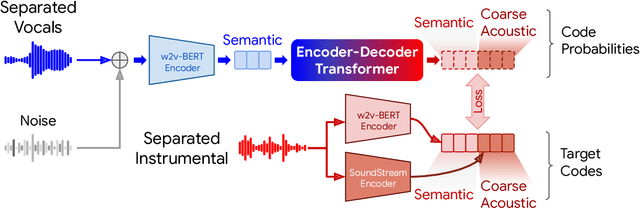
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
MusicLM: Generating Music From Text
Jan 26, 2023



We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Jet Flavour Classification Using DeepJet
Aug 24, 2020
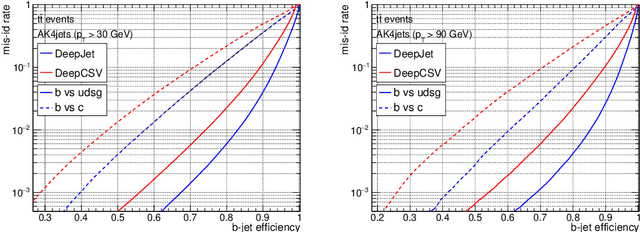
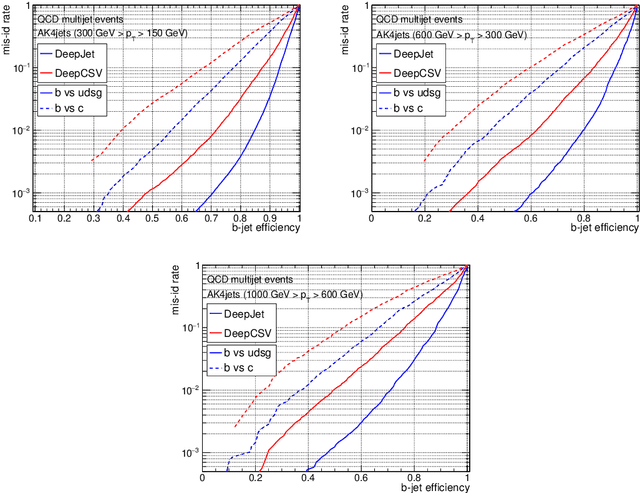
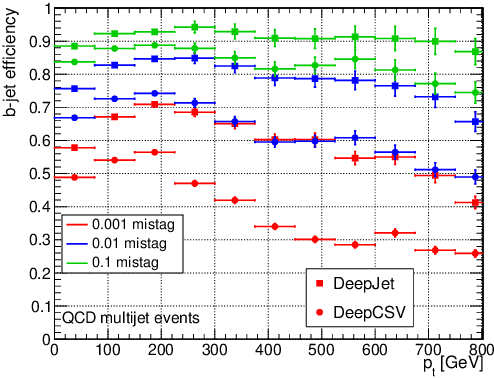
Jet flavour classification is of paramount importance for a broad range of applications in modern-day high-energy-physics experiments, particularly at the LHC. In this paper we propose a novel architecture for this task that exploits modern deep learning techniques. This new model, called DeepJet, overcomes the limitations in input size that affected previous approaches. As a result, the classification performance improves and the number of classes to be predicted can be increased. Such, DeepJet is paving the way to an all-inclusive jet classifier.
Machine Learning in High Energy Physics Community White Paper
Jul 08, 2018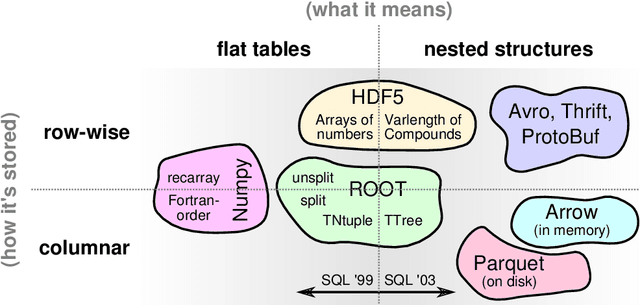
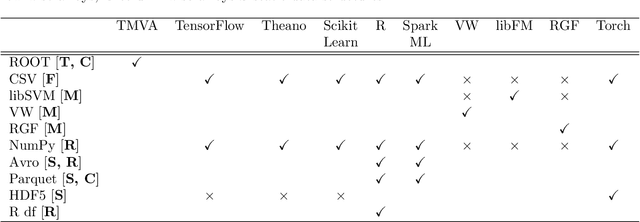

Machine learning is an important research area in particle physics, beginning with applications to high-level physics analysis in the 1990s and 2000s, followed by an explosion of applications in particle and event identification and reconstruction in the 2010s. In this document we discuss promising future research and development areas in machine learning in particle physics with a roadmap for their implementation, software and hardware resource requirements, collaborative initiatives with the data science community, academia and industry, and training the particle physics community in data science. The main objective of the document is to connect and motivate these areas of research and development with the physics drivers of the High-Luminosity Large Hadron Collider and future neutrino experiments and identify the resource needs for their implementation. Additionally we identify areas where collaboration with external communities will be of great benefit.