 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelection of Layers from Self-supervised Learning Models for Predicting Mean-Opinion-Score of Speech
Aug 12, 2025Self-supervised learning (SSL) models like Wav2Vec2, HuBERT, and WavLM have been widely used in speech processing. These transformer-based models consist of multiple layers, each capturing different levels of representation. While prior studies explored their layer-wise representations for efficiency and performance, speech quality assessment (SQA) models predominantly rely on last-layer features, leaving intermediate layers underexamined. In this work, we systematically evaluate different layers of multiple SSL models for predicting mean-opinion-score (MOS). Features from each layer are fed into a lightweight regression network to assess effectiveness. Our experiments consistently show early-layers features outperform or match those from the last layer, leading to significant improvements over conventional approaches and state-of-the-art MOS prediction models. These findings highlight the advantages of early-layer selection, offering enhanced performance and reduced system complexity.
Multivariate Probabilistic Assessment of Speech Quality
Jun 05, 2025The mean opinion score (MOS) is a standard metric for assessing speech quality, but its singular focus fails to identify specific distortions when low scores are observed. The NISQA dataset addresses this limitation by providing ratings across four additional dimensions: noisiness, coloration, discontinuity, and loudness, alongside MOS. In this paper, we extend the explored univariate MOS estimation to a multivariate framework by modeling these dimensions jointly using a multivariate Gaussian distribution. Our approach utilizes Cholesky decomposition to predict covariances without imposing restrictive assumptions and extends probabilistic affine transformations to a multivariate context. Experimental results show that our model performs on par with state-of-the-art methods in point estimation, while uniquely providing uncertainty and correlation estimates across speech quality dimensions. This enables better diagnosis of poor speech quality and informs targeted improvements.
Impairments are Clustered in Latents of Deep Neural Network-based Speech Quality Models
Apr 30, 2025In this article, we provide an experimental observation: Deep neural network (DNN) based speech quality assessment (SQA) models have inherent latent representations where many types of impairments are clustered. While DNN-based SQA models are not trained for impairment classification, our experiments show good impairment classification results in an appropriate SQA latent representation. We investigate the clustering of impairments using various kinds of audio degradations that include different types of noises, waveform clipping, gain transition, pitch shift, compression, reverberation, etc. To visualize the clusters we perform classification of impairments in the SQA-latent representation domain using a standard k-nearest neighbor (kNN) classifier. We also develop a new DNN-based SQA model, named DNSMOS+, to examine whether an improvement in SQA leads to an improvement in impairment classification. The classification accuracy is 94% for LibriAugmented dataset with 16 types of impairments and 54% for ESC-50 dataset with 50 types of real noises.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
Sense and Learn: Self-Supervision for Omnipresent Sensors
Sep 28, 2020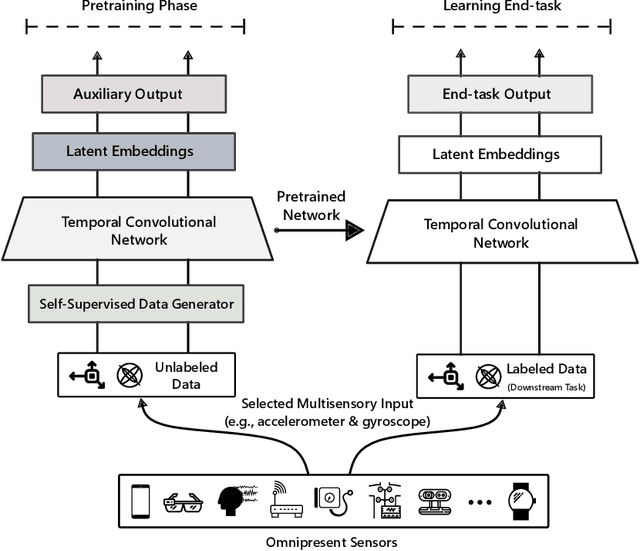

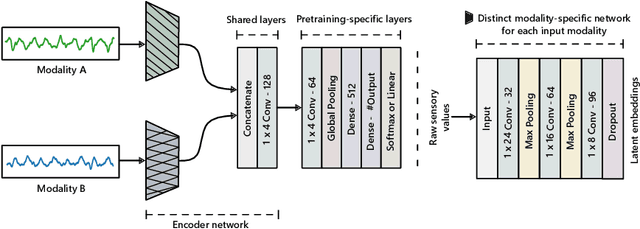
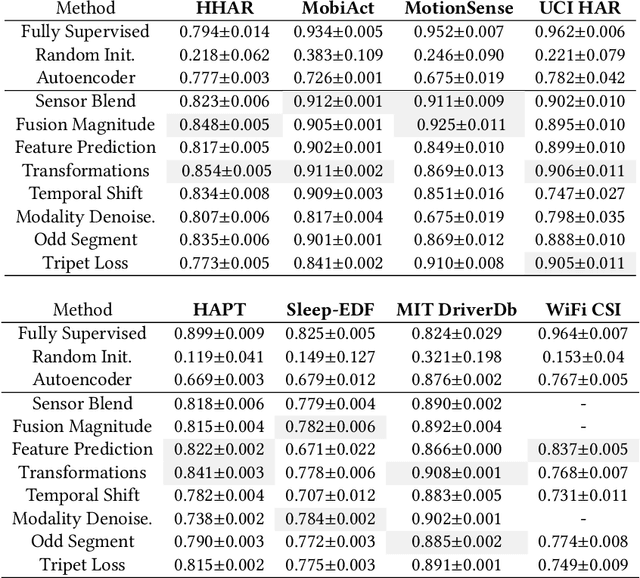
Learning general-purpose representations from multisensor data produced by the omnipresent sensing systems (or IoT in general) has numerous applications in diverse use areas. Existing purely supervised end-to-end deep learning techniques depend on the availability of a massive amount of well-curated data, acquiring which is notoriously difficult but required to achieve a sufficient level of generalization on a task of interest. In this work, we leverage the self-supervised learning paradigm towards realizing the vision of continual learning from unlabeled inputs. We present a generalized framework named Sense and Learn for representation or feature learning from raw sensory data. It consists of eight auxiliary tasks that can learn high-level and broadly useful features entirely from unannotated data without any human involvement in the tedious labeling process. We demonstrate the efficacy of our approach on several publicly available datasets from different domains and in various settings, including linear separability, semi-supervised or few shot learning, and transfer learning. Our methodology achieves results that are competitive with the supervised approaches and close the gap through fine-tuning a network while learning the downstream tasks in most cases. In particular, we show that the self-supervised network can be utilized as initialization to significantly boost the performance in a low-data regime with as few as 5 labeled instances per class, which is of high practical importance to real-world problems. Likewise, the learned representations with self-supervision are found to be highly transferable between related datasets, even when few labeled instances are available from the target domains. The self-learning nature of our methodology opens up exciting possibilities for on-device continual learning.