 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Separation of Arbitrary Sounds
Apr 12, 2022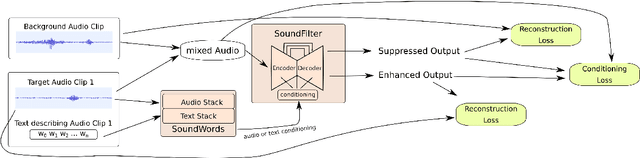

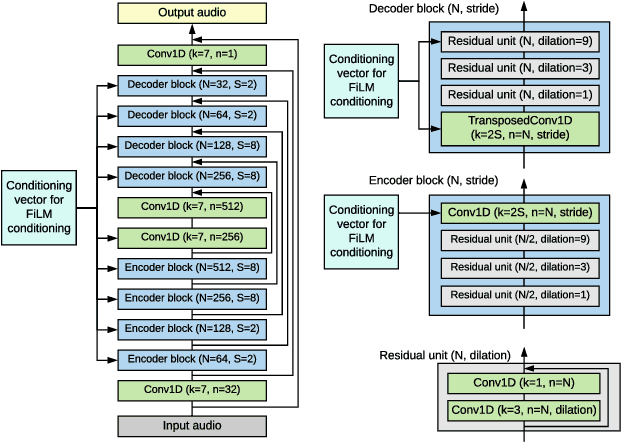
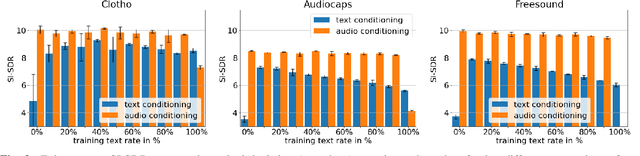
We propose a method of separating a desired sound source from a single-channel mixture, based on either a textual description or a short audio sample of the target source. This is achieved by combining two distinct models. The first model, SoundWords, is trained to jointly embed both an audio clip and its textual description to the same embedding in a shared representation. The second model, SoundFilter, takes a mixed source audio clip as an input and separates it based on a conditioning vector from the shared text-audio representation defined by SoundWords, making the model agnostic to the conditioning modality. Evaluating on multiple datasets, we show that our approach can achieve an SI-SDR of 9.1 dB for mixtures of two arbitrary sounds when conditioned on text and 10.1 dB when conditioned on audio. We also show that SoundWords is effective at learning co-embeddings and that our multi-modal training approach improves the performance of SoundFilter.
MicAugment: One-shot Microphone Style Transfer
Oct 19, 2020


A crucial aspect for the successful deployment of audio-based models "in-the-wild" is the robustness to the transformations introduced by heterogeneous acquisition conditions. In this work, we propose a method to perform one-shot microphone style transfer. Given only a few seconds of audio recorded by a target device, MicAugment identifies the transformations associated to the input acquisition pipeline and uses the learned transformations to synthesize audio as if it were recorded under the same conditions as the target audio. We show that our method can successfully apply the style transfer to real audio and that it significantly increases model robustness when used as data augmentation in the downstream tasks.
Sense and Learn: Self-Supervision for Omnipresent Sensors
Sep 28, 2020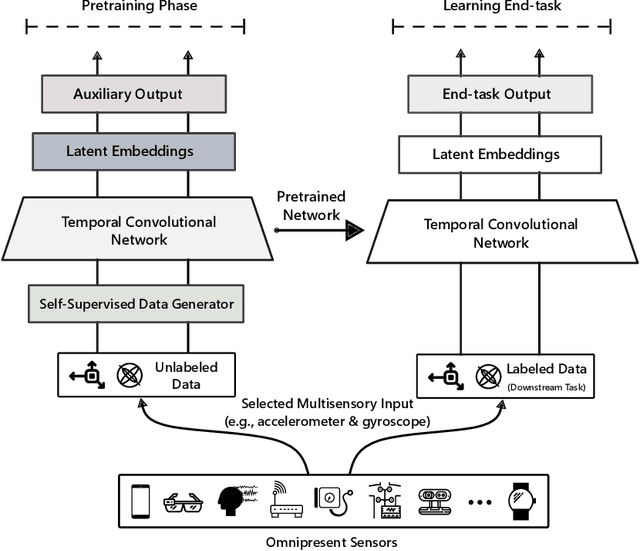

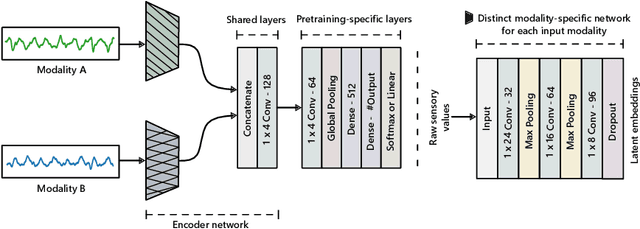
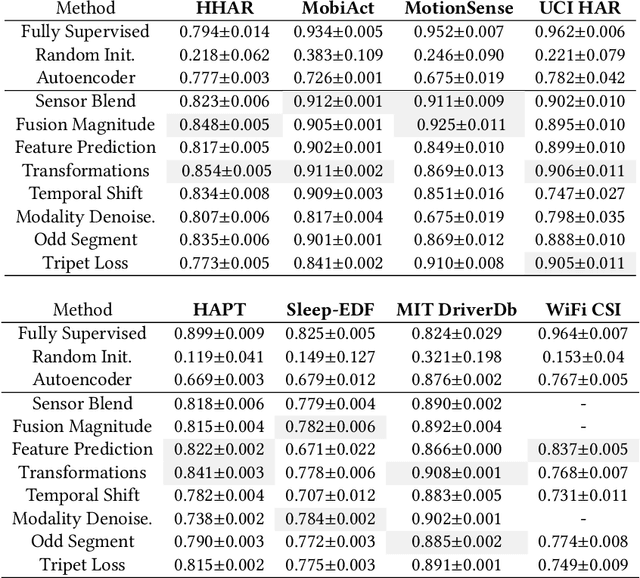
Learning general-purpose representations from multisensor data produced by the omnipresent sensing systems (or IoT in general) has numerous applications in diverse use areas. Existing purely supervised end-to-end deep learning techniques depend on the availability of a massive amount of well-curated data, acquiring which is notoriously difficult but required to achieve a sufficient level of generalization on a task of interest. In this work, we leverage the self-supervised learning paradigm towards realizing the vision of continual learning from unlabeled inputs. We present a generalized framework named Sense and Learn for representation or feature learning from raw sensory data. It consists of eight auxiliary tasks that can learn high-level and broadly useful features entirely from unannotated data without any human involvement in the tedious labeling process. We demonstrate the efficacy of our approach on several publicly available datasets from different domains and in various settings, including linear separability, semi-supervised or few shot learning, and transfer learning. Our methodology achieves results that are competitive with the supervised approaches and close the gap through fine-tuning a network while learning the downstream tasks in most cases. In particular, we show that the self-supervised network can be utilized as initialization to significantly boost the performance in a low-data regime with as few as 5 labeled instances per class, which is of high practical importance to real-world problems. Likewise, the learned representations with self-supervision are found to be highly transferable between related datasets, even when few labeled instances are available from the target domains. The self-learning nature of our methodology opens up exciting possibilities for on-device continual learning.
Learning to Denoise Historical Music
Aug 05, 2020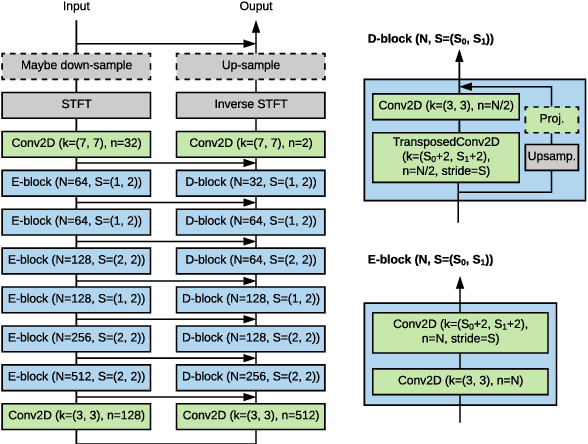
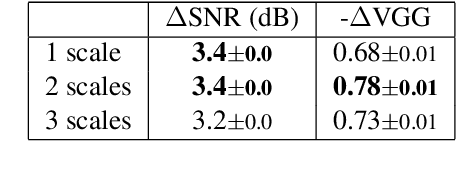
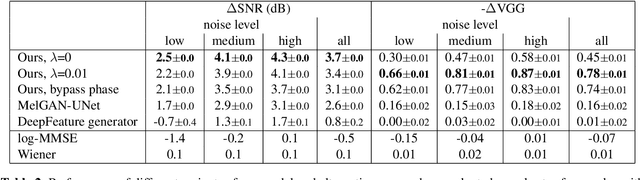
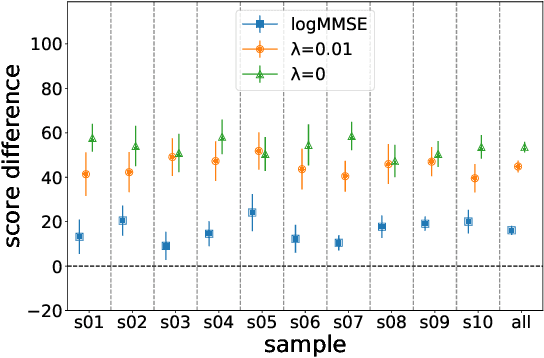
We propose an audio-to-audio neural network model that learns to denoise old music recordings. Our model internally converts its input into a time-frequency representation by means of a short-time Fourier transform (STFT), and processes the resulting complex spectrogram using a convolutional neural network. The network is trained with both reconstruction and adversarial objectives on a synthetic noisy music dataset, which is created by mixing clean music with real noise samples extracted from quiet segments of old recordings. We evaluate our method quantitatively on held-out test examples of the synthetic dataset, and qualitatively by human rating on samples of actual historical recordings. Our results show that the proposed method is effective in removing noise, while preserving the quality and details of the original music.
SPICE: Self-supervised Pitch Estimation
Oct 25, 2019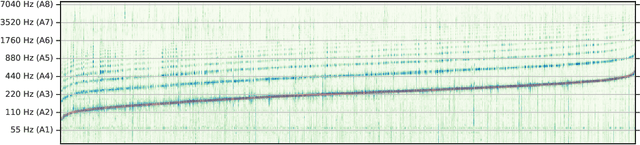
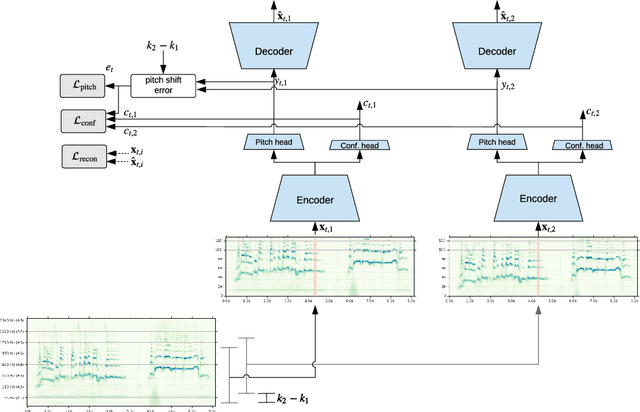
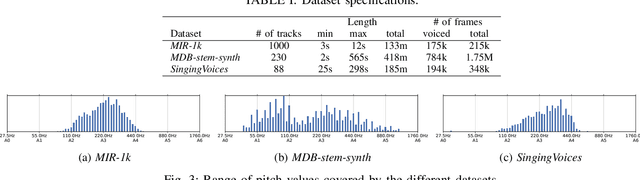
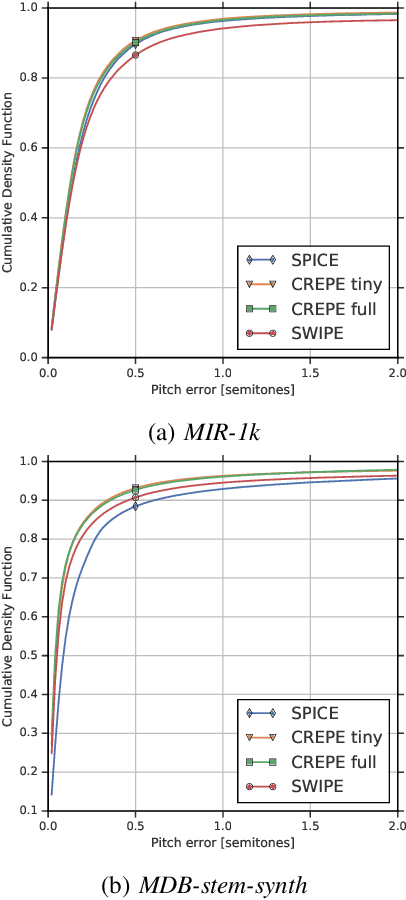
We propose a model to estimate the fundamental frequency in monophonic audio, often referred to as pitch estimation. We acknowledge the fact that obtaining ground truth annotations at the required temporal and frequency resolution is a particularly daunting task. Therefore, we propose to adopt a self-supervised learning technique, which is able to estimate (relative) pitch without any form of supervision. The key observation is that pitch shift maps to a simple translation when the audio signal is analysed through the lens of the constant-Q transform (CQT). We design a self-supervised task by feeding two shifted slices of the CQT to the same convolutional encoder, and require that the difference in the outputs is proportional to the corresponding difference in pitch. In addition, we introduce a small model head on top of the encoder, which is able to determine the confidence of the pitch estimate, so as to distinguish between voiced and unvoiced audio. Our results show that the proposed method is able to estimate pitch at a level of accuracy comparable to fully supervised models, both on clean and noisy audio samples, yet it does not require access to large labeled datasets
Self-supervised audio representation learning for mobile devices
May 24, 2019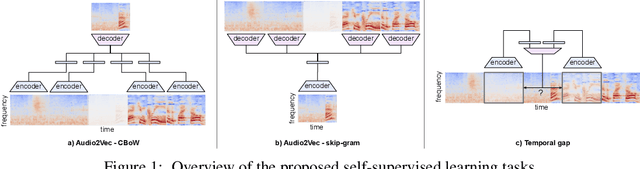
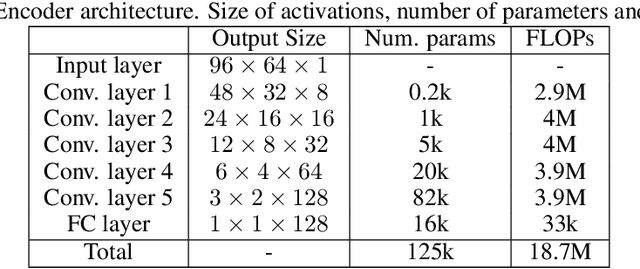
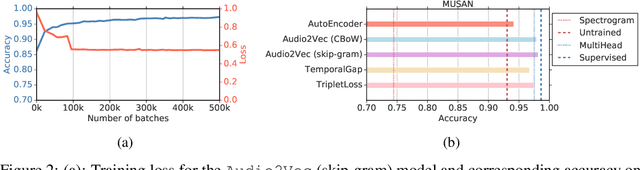
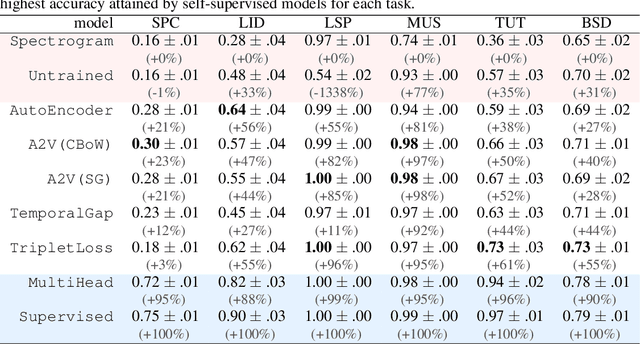
We explore self-supervised models that can be potentially deployed on mobile devices to learn general purpose audio representations. Specifically, we propose methods that exploit the temporal context in the spectrogram domain. One method estimates the temporal gap between two short audio segments extracted at random from the same audio clip. The other methods are inspired by Word2Vec, a popular technique used to learn word embeddings, and aim at reconstructing a temporal spectrogram slice from past and future slices or, alternatively, at reconstructing the context of surrounding slices from the current slice. We focus our evaluation on small encoder architectures, which can be potentially run on mobile devices during both inference (re-using a common learned representation across multiple downstream tasks) and training (capturing the true data distribution without compromising users' privacy when combined with federated learning). We evaluate the quality of the embeddings produced by the self-supervised learning models, and show that they can be re-used for a variety of downstream tasks, and for some tasks even approach the performance of fully supervised models of similar size.
Now Playing: Continuous low-power music recognition
Nov 29, 2017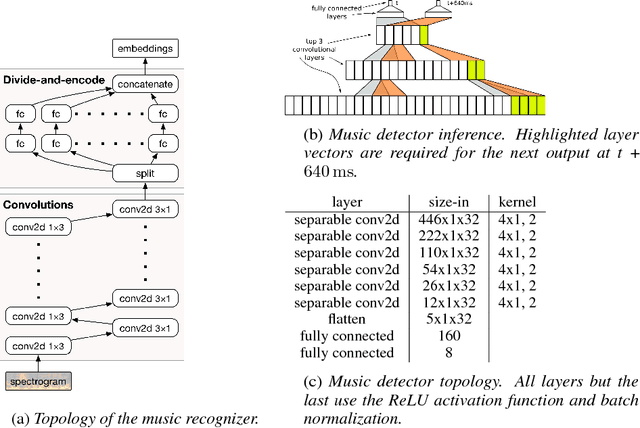
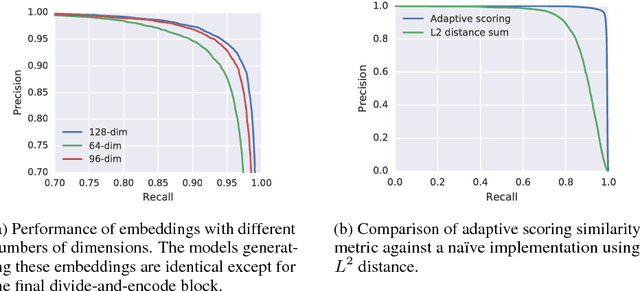
Existing music recognition applications require a connection to a server that performs the actual recognition. In this paper we present a low-power music recognizer that runs entirely on a mobile device and automatically recognizes music without user interaction. To reduce battery consumption, a small music detector runs continuously on the mobile device's DSP chip and wakes up the main application processor only when it is confident that music is present. Once woken, the recognizer on the application processor is provided with a few seconds of audio which is fingerprinted and compared to the stored fingerprints in the on-device fingerprint database of tens of thousands of songs. Our presented system, Now Playing, has a daily battery usage of less than 1% on average, respects user privacy by running entirely on-device and can passively recognize a wide range of music.