 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan In-Context Learning Support Intrinsic Curiosity?
Jun 17, 2026Effective machine learning depends not only on how we model data, but also on what data we choose to collect. While large sequence models have revolutionized data modeling, the problem of automated data selection, or "intrinsic curiosity", remains a significant challenge. Classic approaches incentivize exploration by rewarding an agent based on its "learning progress", which measures how much a newly acquired observation improves a world model's predictive ability. However, evaluating these rewards traditionally requires expensive inner loops of gradient descent updates within each trajectory, rendering them computationally impractical at scale. In this work, we investigate whether the emergent in-context learning (ICL) capabilities of sequence models can eliminate this bottleneck by serving as immediate, update-free world models. Specifically, we evaluate whether an exploration policy can be trained to maximize learning progress, using solely the prediction errors and counterfactual context manipulations of an in-context learner. We first prove that in general Markov decision processes, this is in fact impossible in an unbiased way: the resulting intrinsic rewards either suffer from nuisance terms that bias their estimation of true learning progress, or they cannot be implemented using an in-context learner's prediction errors. Conversely, we prove a positive result for a broad subclass of non-temporal settings, encompassing active learning and Bayesian Experimental Design: here, ICL-derived rewards successfully bound and asymptotically converge to the true learning progress. We corroborate our theory with controlled experiments across continuous and symbolic environments, demonstrating that our ICL-driven framework successfully trains curious data-collection policies that explore optimally.
Formal Conjectures: An Open and Evolving Benchmark for Verified Discovery in Mathematics
May 13, 2026As automated reasoning systems advance rapidly, there is a growing need for research-level formal mathematical problems to accurately evaluate their capabilities. To address this, we present Formal Conjectures, an evolving benchmark of currently 2615 mathematical problem statements formalized in Lean 4. Sourced from areas of active mathematical research, the dataset features 1029 open research conjectures providing a zero-contamination benchmark for mathematical proof discovery, and 836 solved problems for proof autoformalization. Notably, the repository provides a structured interface connecting mathematicians who formalize and clarify problems with the AI systems and humans attempting to solve them. Demonstrating its immediate utility, the benchmark has already been leveraged to make new mathematical discoveries, including the resolution of open research conjectures. We describe our approach to ensuring the correctness of these formalizations in a collaborative open-source project where contributions stem from an active community. In this framework, AI-generated proofs and disproofs serve as a valuable auditing mechanism to iteratively improve the fidelity of the benchmark. Finally, we provide a standardized evaluation setup and report baseline results on frozen evaluation subsets, demonstrating a climbable signal that measures the current frontier of automated reasoning on research-level mathematics.
Agentic AI and the next intelligence explosion
Mar 21, 2026The "AI singularity" is often miscast as a monolithic, godlike mind. Evolution suggests a different path: intelligence is fundamentally plural, social, and relational. Recent advances in agentic AI reveal that frontier reasoning models, such as DeepSeek-R1, do not improve simply by "thinking longer". Instead, they simulate internal "societies of thought," spontaneous cognitive debates that argue, verify, and reconcile to solve complex tasks. Moreover, we are entering an era of human-AI centaurs: hybrid actors where collective agency transcends individual control. Scaling this intelligence requires shifting from dyadic alignment (RLHF) toward institutional alignment. By designing digital protocols, modeled on organizations and markets, we can build a social infrastructure of checks and balances. The next intelligence explosion will not be a single silicon brain, but a complex, combinatorial society specializing and sprawling like a city. No mind is an island.
Multi-agent cooperation through in-context co-player inference
Feb 18, 2026Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work-where vulnerability to extortion drives mutual shaping-emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.
The unreasonable effectiveness of pattern matching
Jan 16, 2026We report on an astonishing ability of large language models (LLMs) to make sense of "Jabberwocky" language in which most or all content words have been randomly replaced by nonsense strings, e.g., translating "He dwushed a ghanc zawk" to "He dragged a spare chair". This result addresses ongoing controversies regarding how to best think of what LLMs are doing: are they a language mimic, a database, a blurry version of the Web? The ability of LLMs to recover meaning from structural patterns speaks to the unreasonable effectiveness of pattern-matching. Pattern-matching is not an alternative to "real" intelligence, but rather a key ingredient.
Reasoning Models Generate Societies of Thought
Jan 15, 2026Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive. Recent reasoning models outperform comparable instruction-tuned models on complex cognitive tasks, attributed to extended computation through longer chains of thought. Here we show that enhanced reasoning emerges not from extended computation alone, but from simulating multi-agent-like interactions -- a society of thought -- which enables diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis and mechanistic interpretability methods applied to reasoning traces, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviors, including question-answering, perspective shifts, and the reconciliation of conflicting views, and in socio-emotional roles that characterize sharp back-and-forth conversations, together accounting for the accuracy advantage in reasoning tasks. Controlled reinforcement learning experiments reveal that base models increase conversational behaviors when rewarded solely for reasoning accuracy, and fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups, where diversity enables superior problem-solving when systematically structured, which suggests new opportunities for agent organization to harness the wisdom of crowds.
Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Dec 24, 2025Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
What Lives? A meta-analysis of diverse opinions on the definition of life
May 19, 2025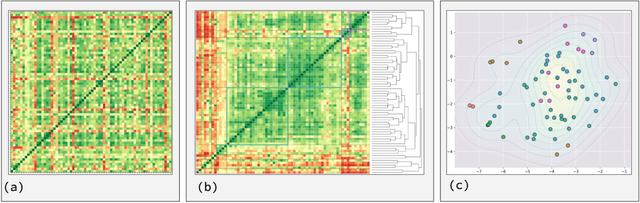
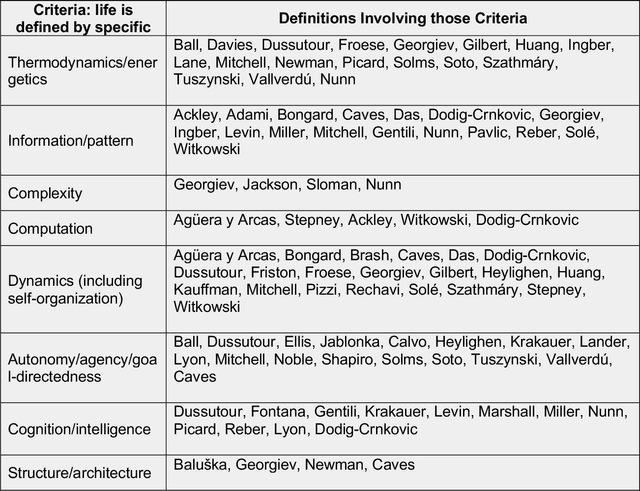
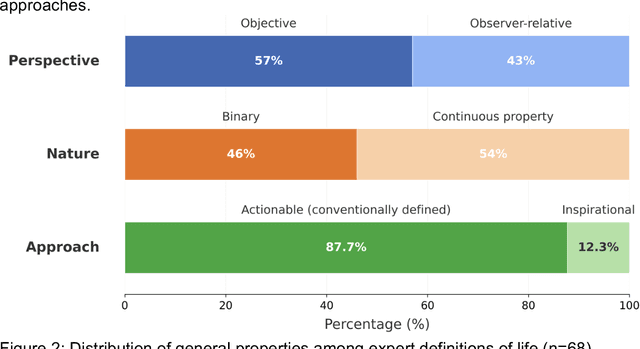
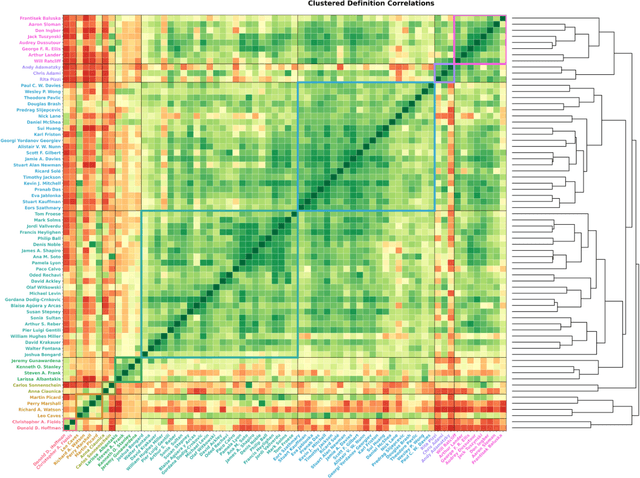
The question of "what is life?" has challenged scientists and philosophers for centuries, producing an array of definitions that reflect both the mystery of its emergence and the diversity of disciplinary perspectives brought to bear on the question. Despite significant progress in our understanding of biological systems, psychology, computation, and information theory, no single definition for life has yet achieved universal acceptance. This challenge becomes increasingly urgent as advances in synthetic biology, artificial intelligence, and astrobiology challenge our traditional conceptions of what it means to be alive. We undertook a methodological approach that leverages large language models (LLMs) to analyze a set of definitions of life provided by a curated set of cross-disciplinary experts. We used a novel pairwise correlation analysis to map the definitions into distinct feature vectors, followed by agglomerative clustering, intra-cluster semantic analysis, and t-SNE projection to reveal underlying conceptual archetypes. This methodology revealed a continuous landscape of the themes relating to the definition of life, suggesting that what has historically been approached as a binary taxonomic problem should be instead conceived as differentiated perspectives within a unified conceptual latent space. We offer a new methodological bridge between reductionist and holistic approaches to fundamental questions in science and philosophy, demonstrating how computational semantic analysis can reveal conceptual patterns across disciplinary boundaries, and opening similar pathways for addressing other contested definitional territories across the sciences.
Can LLMs make trade-offs involving stipulated pain and pleasure states?
Nov 01, 2024



Pleasure and pain play an important role in human decision making by providing a common currency for resolving motivational conflicts. While Large Language Models (LLMs) can generate detailed descriptions of pleasure and pain experiences, it is an open question whether LLMs can recreate the motivational force of pleasure and pain in choice scenarios - a question which may bear on debates about LLM sentience, understood as the capacity for valenced experiential states. We probed this question using a simple game in which the stated goal is to maximise points, but where either the points-maximising option is said to incur a pain penalty or a non-points-maximising option is said to incur a pleasure reward, providing incentives to deviate from points-maximising behaviour. Varying the intensity of the pain penalties and pleasure rewards, we found that Claude 3.5 Sonnet, Command R+, GPT-4o, and GPT-4o mini each demonstrated at least one trade-off in which the majority of responses switched from points-maximisation to pain-minimisation or pleasure-maximisation after a critical threshold of stipulated pain or pleasure intensity is reached. LLaMa 3.1-405b demonstrated some graded sensitivity to stipulated pleasure rewards and pain penalties. Gemini 1.5 Pro and PaLM 2 prioritised pain-avoidance over points-maximisation regardless of intensity, while tending to prioritise points over pleasure regardless of intensity. We discuss the implications of these findings for debates about the possibility of LLM sentience.