 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction
Jun 27, 2024



The fields of Origin of Life and Artificial Life both question what life is and how it emerges from a distinct set of "pre-life" dynamics. One common feature of most substrates where life emerges is a marked shift in dynamics when self-replication appears. While there are some hypotheses regarding how self-replicators arose in nature, we know very little about the general dynamics, computational principles, and necessary conditions for self-replicators to emerge. This is especially true on "computational substrates" where interactions involve logical, mathematical, or programming rules. In this paper we take a step towards understanding how self-replicators arise by studying several computational substrates based on various simple programming languages and machine instruction sets. We show that when random, non self-replicating programs are placed in an environment lacking any explicit fitness landscape, self-replicators tend to arise. We demonstrate how this occurs due to random interactions and self-modification, and can happen with and without background random mutations. We also show how increasingly complex dynamics continue to emerge following the rise of self-replicators. Finally, we show a counterexample of a minimalistic programming language where self-replicators are possible, but so far have not been observed to arise.
Large-Scale Visual Speech Recognition
Oct 01, 2018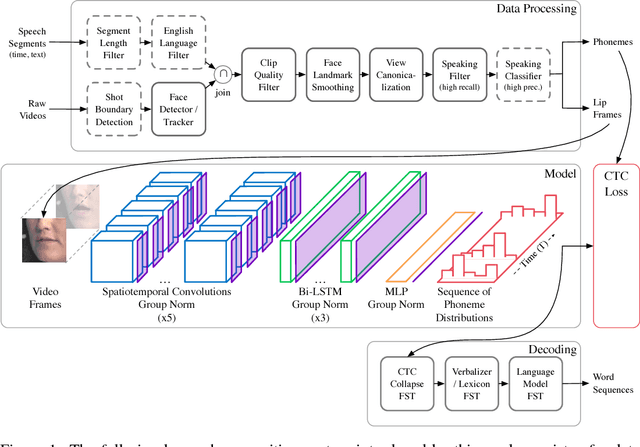
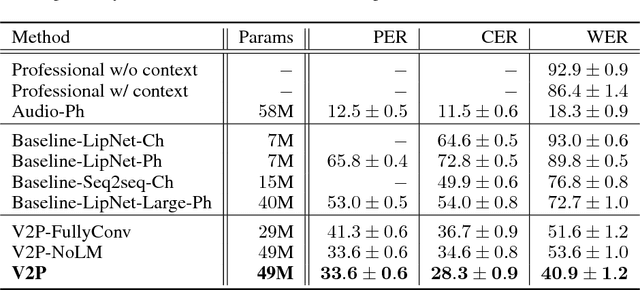


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018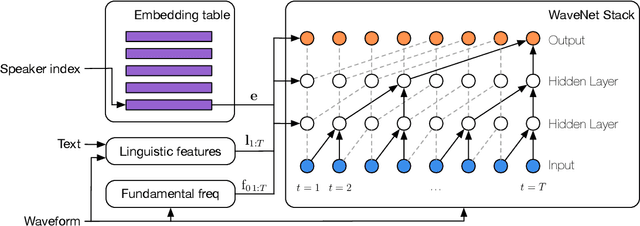
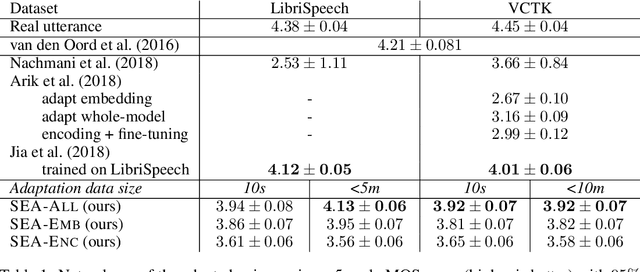
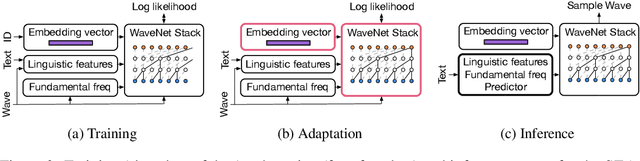
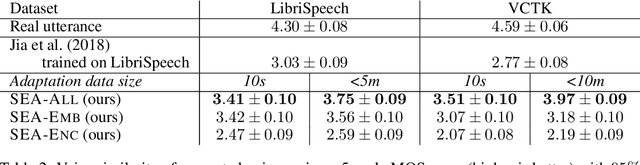
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.