 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Logic Cellular Automata: From Game of Life to Pattern Generation
Jun 05, 2025This paper introduces Differentiable Logic Cellular Automata (DiffLogic CA), a novel combination of Neural Cellular Automata (NCA) and Differentiable Logic Gates Networks (DLGNs). The fundamental computation units of the model are differentiable logic gates, combined into a circuit. During training, the model is fully end-to-end differentiable allowing gradient-based training, and at inference time it operates in a fully discrete state space. This enables learning local update rules for cellular automata while preserving their inherent discrete nature. We demonstrate the versatility of our approach through a series of milestones: (1) fully learning the rules of Conway's Game of Life, (2) generating checkerboard patterns that exhibit resilience to noise and damage, (3) growing a lizard shape, and (4) multi-color pattern generation. Our model successfully learns recurrent circuits capable of generating desired target patterns. For simpler patterns, we observe success with both synchronous and asynchronous updates, demonstrating significant generalization capabilities and robustness to perturbations. We make the case that this combination of DLGNs and NCA represents a step toward programmable matter and robust computing systems that combine binary logic, neural network adaptability, and localized processing. This work, to the best of our knowledge, is the first successful application of differentiable logic gate networks in recurrent architectures.
Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction
Jun 27, 2024



The fields of Origin of Life and Artificial Life both question what life is and how it emerges from a distinct set of "pre-life" dynamics. One common feature of most substrates where life emerges is a marked shift in dynamics when self-replication appears. While there are some hypotheses regarding how self-replicators arose in nature, we know very little about the general dynamics, computational principles, and necessary conditions for self-replicators to emerge. This is especially true on "computational substrates" where interactions involve logical, mathematical, or programming rules. In this paper we take a step towards understanding how self-replicators arise by studying several computational substrates based on various simple programming languages and machine instruction sets. We show that when random, non self-replicating programs are placed in an environment lacking any explicit fitness landscape, self-replicators tend to arise. We demonstrate how this occurs due to random interactions and self-modification, and can happen with and without background random mutations. We also show how increasingly complex dynamics continue to emerge following the rise of self-replicators. Finally, we show a counterexample of a minimalistic programming language where self-replicators are possible, but so far have not been observed to arise.
Mesh Neural Cellular Automata
Nov 06, 2023Modeling and synthesizing textures are essential for enhancing the realism of virtual environments. Methods that directly synthesize textures in 3D offer distinct advantages to the UV-mapping-based methods as they can create seamless textures and align more closely with the ways textures form in nature. We propose Mesh Neural Cellular Automata (MeshNCA), a method for directly synthesizing dynamic textures on 3D meshes without requiring any UV maps. MeshNCA is a generalized type of cellular automata that can operate on a set of cells arranged on a non-grid structure such as vertices of a 3D mesh. While only being trained on an Icosphere mesh, MeshNCA shows remarkable generalization and can synthesize textures on any mesh in real time after the training. Additionally, it accommodates multi-modal supervision and can be trained using different targets such as images, text prompts, and motion vector fields. Moreover, we conceptualize a way of grafting trained MeshNCA instances, enabling texture interpolation. Our MeshNCA model enables real-time 3D texture synthesis on meshes and allows several user interactions including texture density/orientation control, a grafting brush, and motion speed/direction control. Finally, we implement the forward pass of our MeshNCA model using the WebGL shading language and showcase our trained models in an online interactive demo which is accessible on personal computers and smartphones. Our demo and the high resolution version of this PDF are available at https://meshnca.github.io/.
Uncovering mesa-optimization algorithms in Transformers
Sep 11, 2023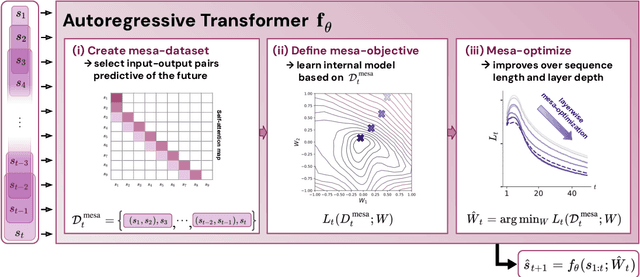
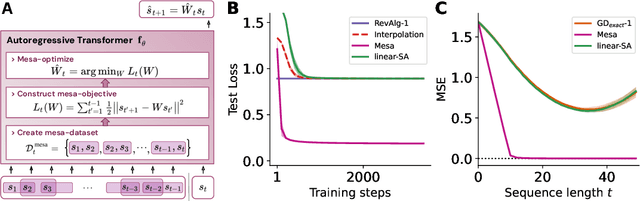
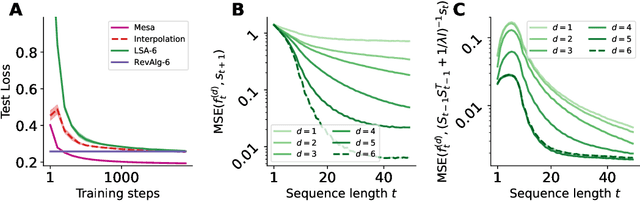
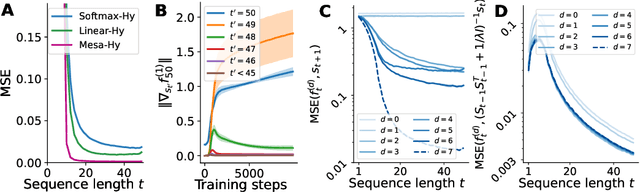
Transformers have become the dominant model in deep learning, but the reason for their superior performance is poorly understood. Here, we hypothesize that the strong performance of Transformers stems from an architectural bias towards mesa-optimization, a learned process running within the forward pass of a model consisting of the following two steps: (i) the construction of an internal learning objective, and (ii) its corresponding solution found through optimization. To test this hypothesis, we reverse-engineer a series of autoregressive Transformers trained on simple sequence modeling tasks, uncovering underlying gradient-based mesa-optimization algorithms driving the generation of predictions. Moreover, we show that the learned forward-pass optimization algorithm can be immediately repurposed to solve supervised few-shot tasks, suggesting that mesa-optimization might underlie the in-context learning capabilities of large language models. Finally, we propose a novel self-attention layer, the mesa-layer, that explicitly and efficiently solves optimization problems specified in context. We find that this layer can lead to improved performance in synthetic and preliminary language modeling experiments, adding weight to our hypothesis that mesa-optimization is an important operation hidden within the weights of trained Transformers.
Differentiable Programming of Chemical Reaction Networks
Feb 06, 2023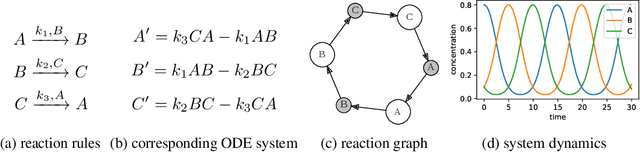
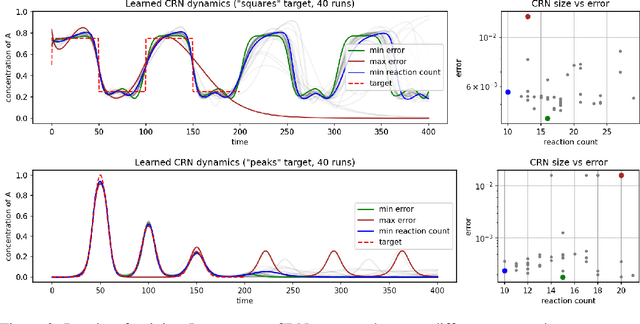
We present a differentiable formulation of abstract chemical reaction networks (CRNs) that can be trained to solve a variety of computational tasks. Chemical reaction networks are one of the most fundamental computational substrates used by nature. We study well-mixed single-chamber systems, as well as systems with multiple chambers separated by membranes, under mass-action kinetics. We demonstrate that differentiable optimisation, combined with proper regularisation, can discover non-trivial sparse reaction networks that can implement various sorts of oscillators and other chemical computing devices.
Transformers learn in-context by gradient descent
Dec 15, 2022Transformers have become the state-of-the-art neural network architecture across numerous domains of machine learning. This is partly due to their celebrated ability to transfer and to learn in-context based on few examples. Nevertheless, the mechanisms by which Transformers become in-context learners are not well understood and remain mostly an intuition. Here, we argue that training Transformers on auto-regressive tasks can be closely related to well-known gradient-based meta-learning formulations. We start by providing a simple weight construction that shows the equivalence of data transformations induced by 1) a single linear self-attention layer and by 2) gradient-descent (GD) on a regression loss. Motivated by that construction, we show empirically that when training self-attention-only Transformers on simple regression tasks either the models learned by GD and Transformers show great similarity or, remarkably, the weights found by optimization match the construction. Thus we show how trained Transformers implement gradient descent in their forward pass. This allows us, at least in the domain of regression problems, to mechanistically understand the inner workings of optimized Transformers that learn in-context. Furthermore, we identify how Transformers surpass plain gradient descent by an iterative curvature correction and learn linear models on deep data representations to solve non-linear regression tasks. Finally, we discuss intriguing parallels to a mechanism identified to be crucial for in-context learning termed induction-head (Olsson et al., 2022) and show how it could be understood as a specific case of in-context learning by gradient descent learning within Transformers.
$μ$NCA: Texture Generation with Ultra-Compact Neural Cellular Automata
Nov 26, 2021

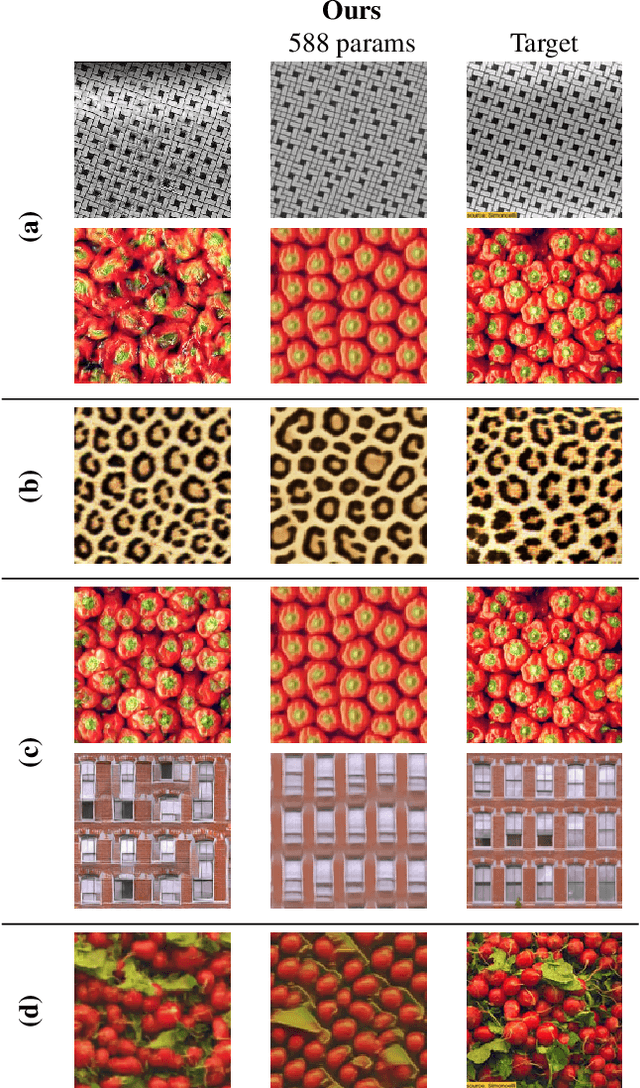
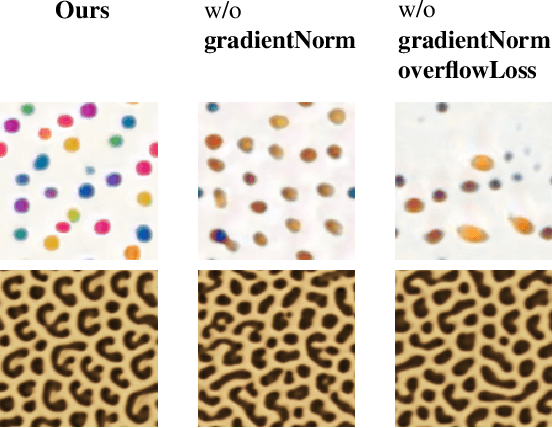
We study the problem of example-based procedural texture synthesis using highly compact models. Given a sample image, we use differentiable programming to train a generative process, parameterised by a recurrent Neural Cellular Automata (NCA) rule. Contrary to the common belief that neural networks should be significantly over-parameterised, we demonstrate that our model architecture and training procedure allows for representing complex texture patterns using just a few hundred learned parameters, making their expressivity comparable to hand-engineered procedural texture generating programs. The smallest models from the proposed $\mu$NCA family scale down to 68 parameters. When using quantisation to one byte per parameter, proposed models can be shrunk to a size range between 588 and 68 bytes. Implementation of a texture generator that uses these parameters to produce images is possible with just a few lines of GLSL or C code.
Differentiable Programming of Reaction-Diffusion Patterns
Jun 22, 2021

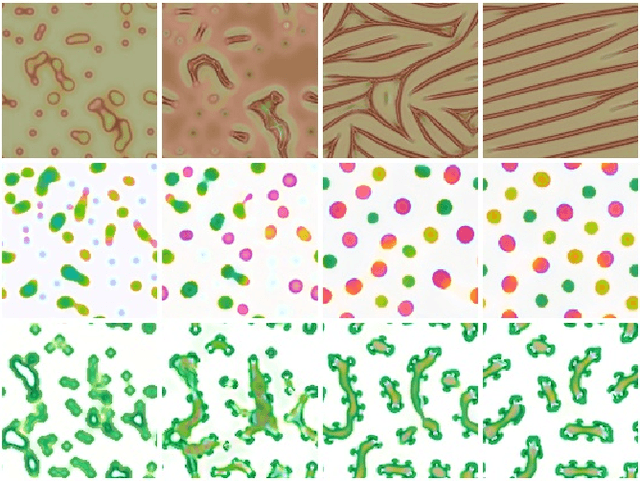

Reaction-Diffusion (RD) systems provide a computational framework that governs many pattern formation processes in nature. Current RD system design practices boil down to trial-and-error parameter search. We propose a differentiable optimization method for learning the RD system parameters to perform example-based texture synthesis on a 2D plane. We do this by representing the RD system as a variant of Neural Cellular Automata and using task-specific differentiable loss functions. RD systems generated by our method exhibit robust, non-trivial 'life-like' behavior.
Texture Generation with Neural Cellular Automata
May 15, 2021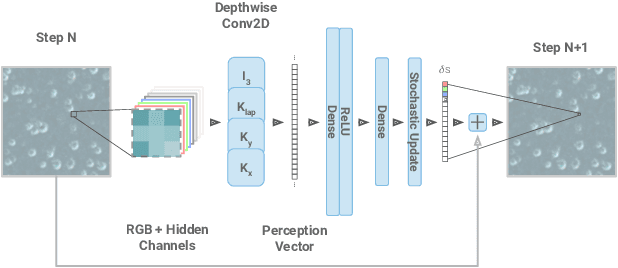
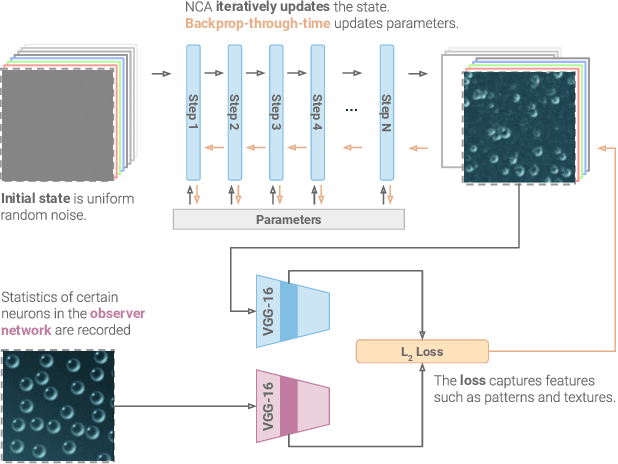


Neural Cellular Automata (NCA) have shown a remarkable ability to learn the required rules to "grow" images, classify morphologies, segment images, as well as to do general computation such as path-finding. We believe the inductive prior they introduce lends itself to the generation of textures. Textures in the natural world are often generated by variants of locally interacting reaction-diffusion systems. Human-made textures are likewise often generated in a local manner (textile weaving, for instance) or using rules with local dependencies (regular grids or geometric patterns). We demonstrate learning a texture generator from a single template image, with the generation method being embarrassingly parallel, exhibiting quick convergence and high fidelity of output, and requiring only some minimal assumptions around the underlying state manifold. Furthermore, we investigate properties of the learned models that are both useful and interesting, such as non-stationary dynamics and an inherent robustness to damage. Finally, we make qualitative claims that the behaviour exhibited by the NCA model is a learned, distributed, local algorithm to generate a texture, setting our method apart from existing work on texture generation. We discuss the advantages of such a paradigm.
MPLP: Learning a Message Passing Learning Protocol
Jul 03, 2020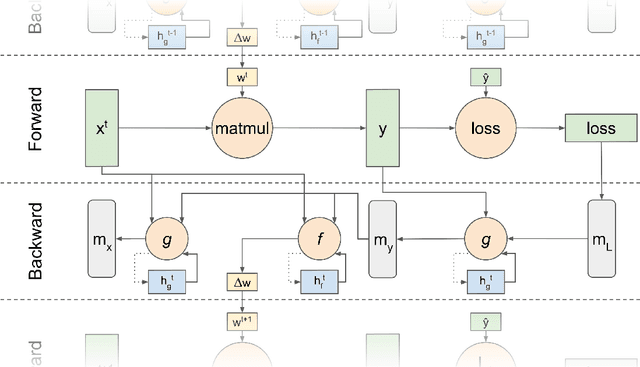

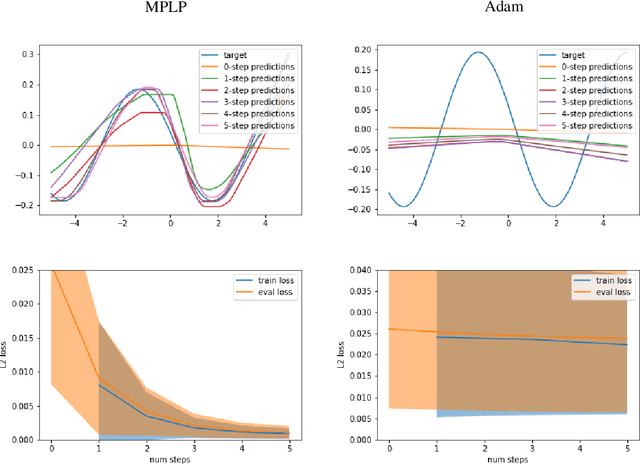
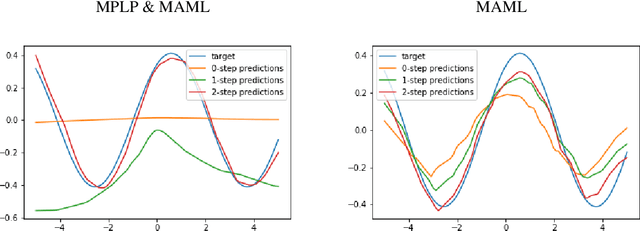
We present a novel method for learning the weights of an artificial neural network - a Message Passing Learning Protocol (MPLP). In MPLP, we abstract every operations occurring in ANNs as independent agents. Each agent is responsible for ingesting incoming multidimensional messages from other agents, updating its internal state, and generating multidimensional messages to be passed on to neighbouring agents. We demonstrate the viability of MPLP as opposed to traditional gradient-based approaches on simple feed-forward neural networks, and present a framework capable of generalizing to non-traditional neural network architectures. MPLP is meta learned using end-to-end gradient-based meta-optimisation. We further discuss the observed properties of MPLP and hypothesize its applicability on various fields of deep learning.