 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Particle Automata: Learning Self-Organizing Particle Dynamics
Jan 22, 2026We introduce Neural Particle Automata (NPA), a Lagrangian generalization of Neural Cellular Automata (NCA) from static lattices to dynamic particle systems. Unlike classical Eulerian NCA where cells are pinned to pixels or voxels, NPA model each cell as a particle with a continuous position and internal state, both updated by a shared, learnable neural rule. This particle-based formulation yields clear individuation of cells, allows heterogeneous dynamics, and concentrates computation only on regions where activity is present. At the same time, particle systems pose challenges: neighborhoods are dynamic, and a naive implementation of local interactions scale quadratically with the number of particles. We address these challenges by replacing grid-based neighborhood perception with differentiable Smoothed Particle Hydrodynamics (SPH) operators backed by memory-efficient, CUDA-accelerated kernels, enabling scalable end-to-end training. Across tasks including morphogenesis, point-cloud classification, and particle-based texture synthesis, we show that NPA retain key NCA behaviors such as robustness and self-regeneration, while enabling new behaviors specific to particle systems. Together, these results position NPA as a compact neural model for learning self-organizing particle dynamics.
Canonical Latent Representations in Conditional Diffusion Models
Jun 11, 2025
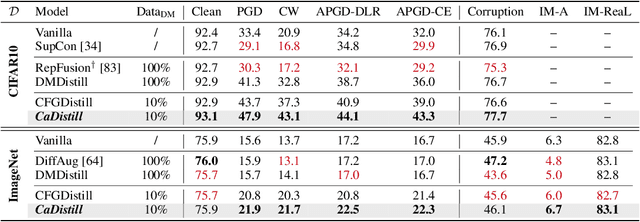
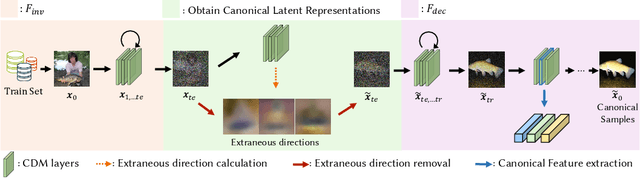

Conditional diffusion models (CDMs) have shown impressive performance across a range of generative tasks. Their ability to model the full data distribution has opened new avenues for analysis-by-synthesis in downstream discriminative learning. However, this same modeling capacity causes CDMs to entangle the class-defining features with irrelevant context, posing challenges to extracting robust and interpretable representations. To this end, we identify Canonical LAtent Representations (CLAReps), latent codes whose internal CDM features preserve essential categorical information while discarding non-discriminative signals. When decoded, CLAReps produce representative samples for each class, offering an interpretable and compact summary of the core class semantics with minimal irrelevant details. Exploiting CLAReps, we develop a novel diffusion-based feature-distillation paradigm, CaDistill. While the student has full access to the training set, the CDM as teacher transfers core class knowledge only via CLAReps, which amounts to merely 10 % of the training data in size. After training, the student achieves strong adversarial robustness and generalization ability, focusing more on the class signals instead of spurious background cues. Our findings suggest that CDMs can serve not just as image generators but also as compact, interpretable teachers that can drive robust representation learning.
NoiseNCA: Noisy Seed Improves Spatio-Temporal Continuity of Neural Cellular Automata
Apr 09, 2024Neural Cellular Automata (NCA) is a class of Cellular Automata where the update rule is parameterized by a neural network that can be trained using gradient descent. In this paper, we focus on NCA models used for texture synthesis, where the update rule is inspired by partial differential equations (PDEs) describing reaction-diffusion systems. To train the NCA model, the spatio-termporal domain is discretized, and Euler integration is used to numerically simulate the PDE. However, whether a trained NCA truly learns the continuous dynamic described by the corresponding PDE or merely overfits the discretization used in training remains an open question. We study NCA models at the limit where space-time discretization approaches continuity. We find that existing NCA models tend to overfit the training discretization, especially in the proximity of the initial condition, also called "seed". To address this, we propose a solution that utilizes uniform noise as the initial condition. We demonstrate the effectiveness of our approach in preserving the consistency of NCA dynamics across a wide range of spatio-temporal granularities. Our improved NCA model enables two new test-time interactions by allowing continuous control over the speed of pattern formation and the scale of the synthesized patterns. We demonstrate this new NCA feature in our interactive online demo. Our work reveals that NCA models can learn continuous dynamics and opens new venues for NCA research from a dynamical systems' perspective.
Emergent Dynamics in Neural Cellular Automata
Apr 09, 2024
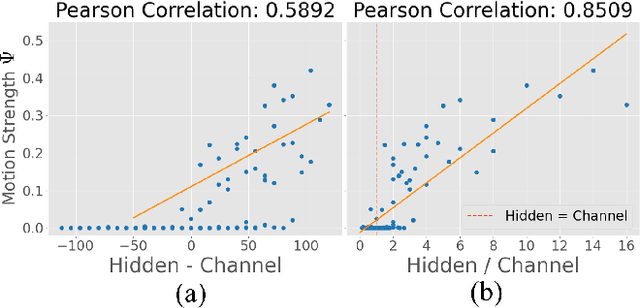

Neural Cellular Automata (NCA) models are trainable variations of traditional Cellular Automata (CA). Emergent motion in the patterns created by NCA has been successfully applied to synthesize dynamic textures. However, the conditions required for an NCA to display dynamic patterns remain unexplored. Here, we investigate the relationship between the NCA architecture and the emergent dynamics of the trained models. Specifically, we vary the number of channels in the cell state and the number of hidden neurons in the MultiLayer Perceptron (MLP), and draw a relationship between the combination of these two variables and the motion strength between successive frames. Our analysis reveals that the disparity and proportionality between these two variables have a strong correlation with the emergent dynamics in the NCA output. We thus propose a design principle for creating dynamic NCA.
Mesh Neural Cellular Automata
Nov 06, 2023Modeling and synthesizing textures are essential for enhancing the realism of virtual environments. Methods that directly synthesize textures in 3D offer distinct advantages to the UV-mapping-based methods as they can create seamless textures and align more closely with the ways textures form in nature. We propose Mesh Neural Cellular Automata (MeshNCA), a method for directly synthesizing dynamic textures on 3D meshes without requiring any UV maps. MeshNCA is a generalized type of cellular automata that can operate on a set of cells arranged on a non-grid structure such as vertices of a 3D mesh. While only being trained on an Icosphere mesh, MeshNCA shows remarkable generalization and can synthesize textures on any mesh in real time after the training. Additionally, it accommodates multi-modal supervision and can be trained using different targets such as images, text prompts, and motion vector fields. Moreover, we conceptualize a way of grafting trained MeshNCA instances, enabling texture interpolation. Our MeshNCA model enables real-time 3D texture synthesis on meshes and allows several user interactions including texture density/orientation control, a grafting brush, and motion speed/direction control. Finally, we implement the forward pass of our MeshNCA model using the WebGL shading language and showcase our trained models in an online interactive demo which is accessible on personal computers and smartphones. Our demo and the high resolution version of this PDF are available at https://meshnca.github.io/.
DyNCA: Real-time Dynamic Texture Synthesis Using Neural Cellular Automata
Nov 21, 2022Current Dynamic Texture Synthesis (DyTS) models in the literature can synthesize realistic videos. However, these methods require a slow iterative optimization process to synthesize a single fixed-size short video, and they do not offer any post-training control over the synthesis process. We propose Dynamic Neural Cellular Automata (DyNCA), a framework for real-time and controllable dynamic texture synthesis. Our method is built upon the recently introduced NCA models, and can synthesize infinitely-long and arbitrary-size realistic texture videos in real-time. We quantitatively and qualitatively evaluate our model and show that our synthesized videos appear more realistic than the existing results. We improve the SOTA DyTS performance by $2\sim 4$ orders of magnitude. Moreover, our model offers several real-time and interactive video controls including motion speed, motion direction, and an editing brush tool.
CLIPasso: Semantically-Aware Object Sketching
Feb 11, 2022


Abstraction is at the heart of sketching due to the simple and minimal nature of line drawings. Abstraction entails identifying the essential visual properties of an object or scene, which requires semantic understanding and prior knowledge of high-level concepts. Abstract depictions are therefore challenging for artists, and even more so for machines. We present an object sketching method that can achieve different levels of abstraction, guided by geometric and semantic simplifications. While sketch generation methods often rely on explicit sketch datasets for training, we utilize the remarkable ability of CLIP (Contrastive-Language-Image-Pretraining) to distill semantic concepts from sketches and images alike. We define a sketch as a set of B\'ezier curves and use a differentiable rasterizer to optimize the parameters of the curves directly with respect to a CLIP-based perceptual loss. The abstraction degree is controlled by varying the number of strokes. The generated sketches demonstrate multiple levels of abstraction while maintaining recognizability, underlying structure, and essential visual components of the subject drawn.
Optimizing Latent Space Directions For GAN-based Local Image Editing
Nov 24, 2021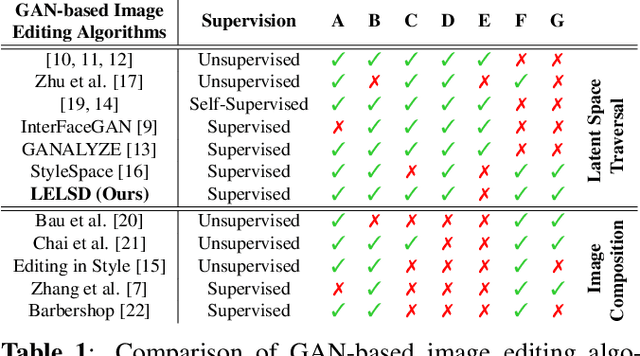
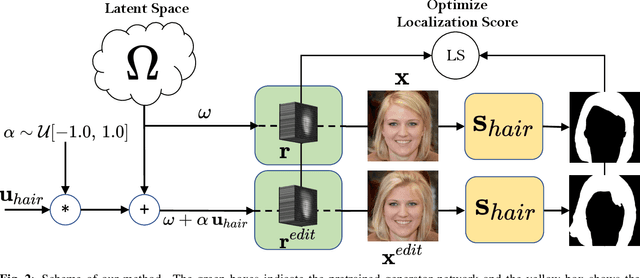


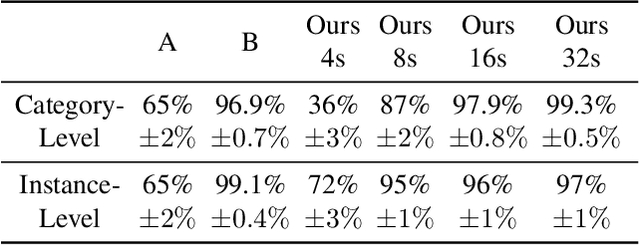
Generative Adversarial Network (GAN) based localized image editing can suffer ambiguity between semantic attributes. We thus present a novel objective function to evaluate the locality of an image edit. By introducing the supervision from a pre-trained segmentation network and optimizing the objective function, our framework, called Locally Effective Latent Space Direction (LELSD), is applicable to any dataset and GAN architecture. Our method is also computationally fast and exhibits a high extent of disentanglement, which allows users to interactively perform a sequence of edits on an image. Our experiments on both GAN-generated and real images qualitatively demonstrate the high quality and advantages of our method.
ChOracle: A Unified Statistical Framework for Churn Prediction
Sep 15, 2019
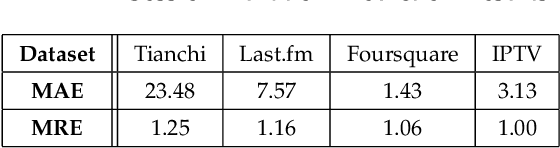


User churn is an important issue in online services that threatens the health and profitability of services. Most of the previous works on churn prediction convert the problem into a binary classification task where the users are labeled as churned and non-churned. More recently, some works have tried to convert the user churn prediction problem into the prediction of user return time. In this approach which is more realistic in real world online services, at each time-step the model predicts the user return time instead of predicting a churn label. However, the previous works in this category suffer from lack of generality and require high computational complexity. In this paper, we introduce \emph{ChOracle}, an oracle that predicts the user churn by modeling the user return times to service by utilizing a combination of Temporal Point Processes and Recurrent Neural Networks. Moreover, we incorporate latent variables into the proposed recurrent neural network to model the latent user loyalty to the system. We also develop an efficient approximate variational algorithm for learning parameters of the proposed RNN by using back propagation through time. Finally, we demonstrate the superior performance of ChOracle on a wide variety of real world datasets.
Back to square one: probabilistic trajectory forecasting without bells and whistles
Dec 07, 2018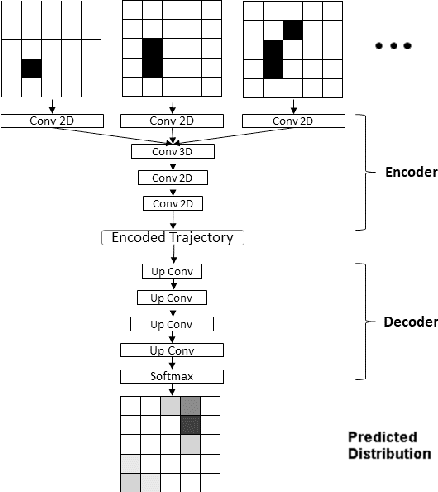


We introduce a spatio-temporal convolutional neural network model for trajectory forecasting from visual sources. Applied in an auto-regressive way it provides an explicit probability distribution over continuations of a given initial trajectory segment. We discuss it in relation to (more complicated) existing work and report on experiments on two standard datasets for trajectory forecasting: MNISTseq and Stanford Drones, achieving results on-par with or better than previous methods.