 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Natural Language Processing and Deep Learning based Model for Automated Vehicle Diagnostics using Free-Text Customer Service Reports
Nov 29, 2021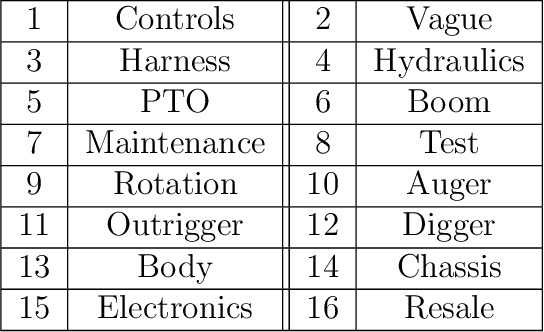
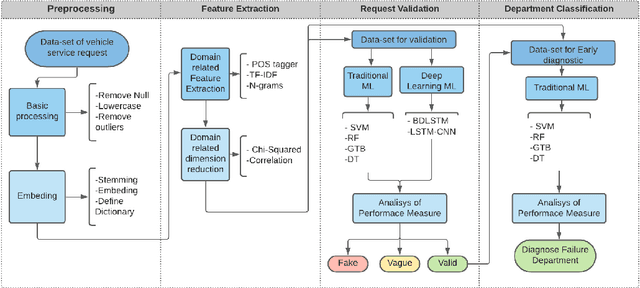


Initial fault detection and diagnostics are imperative measures to improve the efficiency, safety, and stability of vehicle operation. In recent years, numerous studies have investigated data-driven approaches to improve the vehicle diagnostics process using available vehicle data. Moreover, data-driven methods are employed to enhance customer-service agent interactions. In this study, we demonstrate a machine learning pipeline to improve automated vehicle diagnostics. First, Natural Language Processing (NLP) is used to automate the extraction of crucial information from free-text failure reports (generated during customers' calls to the service department). Then, deep learning algorithms are employed to validate service requests and filter vague or misleading claims. Ultimately, different classification algorithms are implemented to classify service requests so that valid service requests can be directed to the relevant service department. The proposed model- Bidirectional Long Short Term Memory (BiLSTM) along with Convolution Neural Network (CNN)- shows more than 18\% accuracy improvement in validating service requests compared to technicians' capabilities. In addition, using domain-based NLP techniques at preprocessing and feature extraction stages along with CNN-BiLSTM based request validation enhanced the accuracy ($>25\%$), sensitivity ($>39\%$), specificity ($>11\%$), and precision ($>11\%$) of Gradient Tree Boosting (GTB) service classification model. The Receiver Operating Characteristic Area Under the Curve (ROC-AUC) reached 0.82.
ChOracle: A Unified Statistical Framework for Churn Prediction
Sep 15, 2019
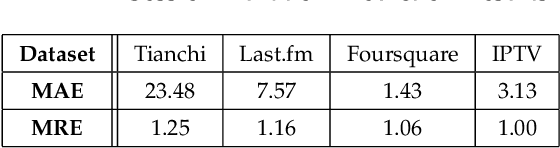


User churn is an important issue in online services that threatens the health and profitability of services. Most of the previous works on churn prediction convert the problem into a binary classification task where the users are labeled as churned and non-churned. More recently, some works have tried to convert the user churn prediction problem into the prediction of user return time. In this approach which is more realistic in real world online services, at each time-step the model predicts the user return time instead of predicting a churn label. However, the previous works in this category suffer from lack of generality and require high computational complexity. In this paper, we introduce \emph{ChOracle}, an oracle that predicts the user churn by modeling the user return times to service by utilizing a combination of Temporal Point Processes and Recurrent Neural Networks. Moreover, we incorporate latent variables into the proposed recurrent neural network to model the latent user loyalty to the system. We also develop an efficient approximate variational algorithm for learning parameters of the proposed RNN by using back propagation through time. Finally, we demonstrate the superior performance of ChOracle on a wide variety of real world datasets.
Recurrent Poisson Factorization for Temporal Recommendation
Mar 04, 2017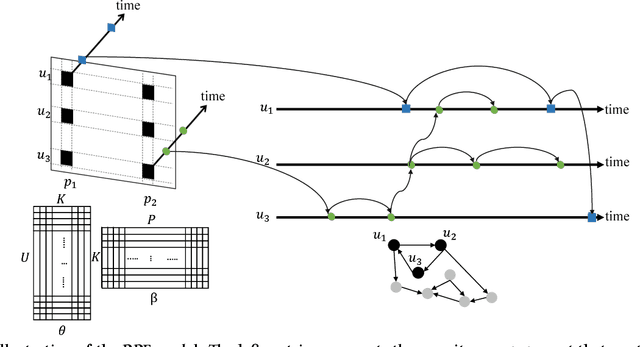
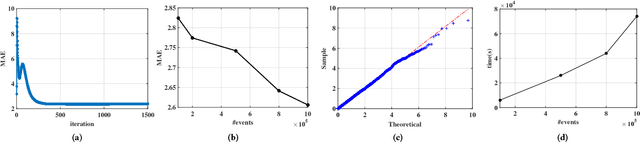
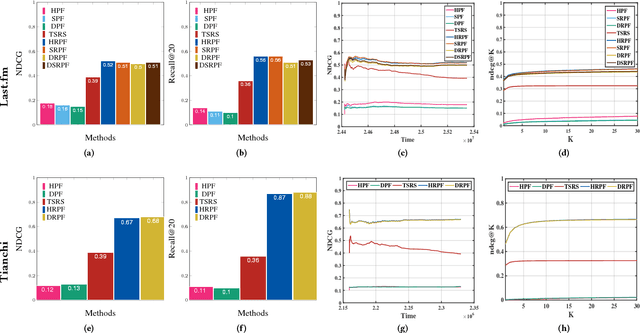
Poisson factorization is a probabilistic model of users and items for recommendation systems, where the so-called implicit consumer data is modeled by a factorized Poisson distribution. There are many variants of Poisson factorization methods who show state-of-the-art performance on real-world recommendation tasks. However, most of them do not explicitly take into account the temporal behavior and the recurrent activities of users which is essential to recommend the right item to the right user at the right time. In this paper, we introduce Recurrent Poisson Factorization (RPF) framework that generalizes the classical PF methods by utilizing a Poisson process for modeling the implicit feedback. RPF treats time as a natural constituent of the model and brings to the table a rich family of time-sensitive factorization models. To elaborate, we instantiate several variants of RPF who are capable of handling dynamic user preferences and item specification (DRPF), modeling the social-aspect of product adoption (SRPF), and capturing the consumption heterogeneity among users and items (HRPF). We also develop a variational algorithm for approximate posterior inference that scales up to massive data sets. Furthermore, we demonstrate RPF's superior performance over many state-of-the-art methods on synthetic dataset, and large scale real-world datasets on music streaming logs, and user-item interactions in M-Commerce platforms.
Continuous-Time User Modeling in the Presence of Badges: A Probabilistic Approach
Feb 07, 2017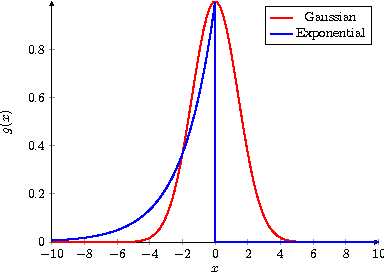
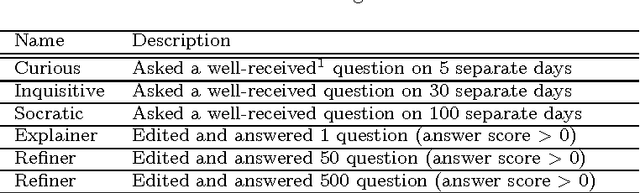
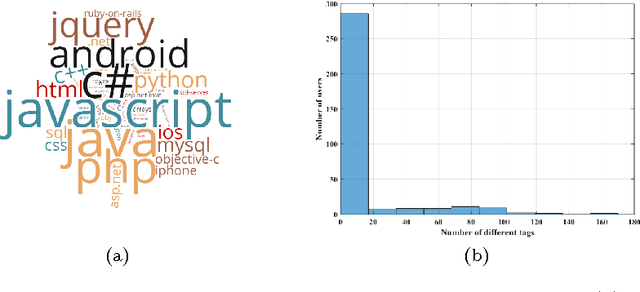

User modeling plays an important role in delivering customized web services to the users and improving their engagement. However, most user models in the literature do not explicitly consider the temporal behavior of users. More recently, continuous-time user modeling has gained considerable attention and many user behavior models have been proposed based on temporal point processes. However, typical point process based models often considered the impact of peer influence and content on the user participation and neglected other factors. Gamification elements, are among those factors that are neglected, while they have a strong impact on user participation in online services. In this paper, we propose interdependent multi-dimensional temporal point processes that capture the impact of badges on user participation besides the peer influence and content factors. We extend the proposed processes to model user actions over the community based question and answering websites, and propose an inference algorithm based on Variational-EM that can efficiently learn the model parameters. Extensive experiments on both synthetic and real data gathered from Stack Overflow show that our inference algorithm learns the parameters efficiently and the proposed method can better predict the user behavior compared to the alternatives.
HNP3: A Hierarchical Nonparametric Point Process for Modeling Content Diffusion over Social Media
Oct 02, 2016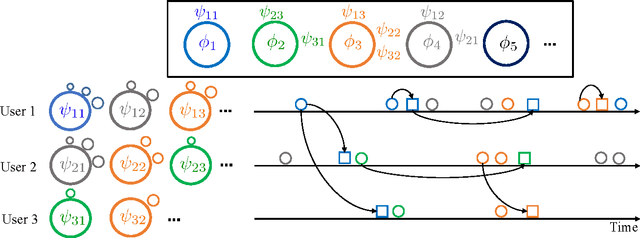
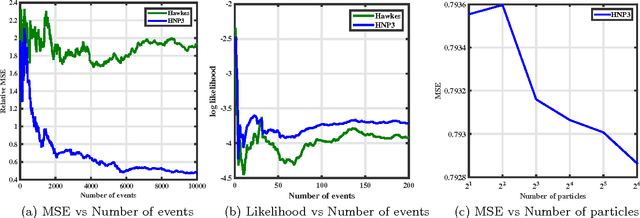
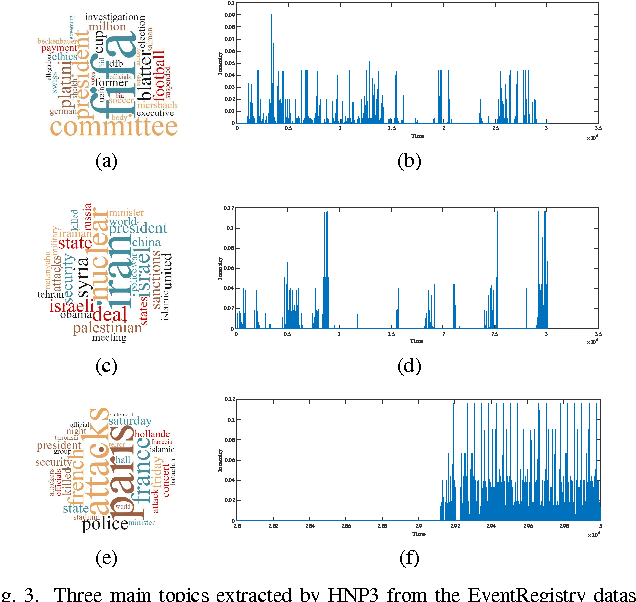
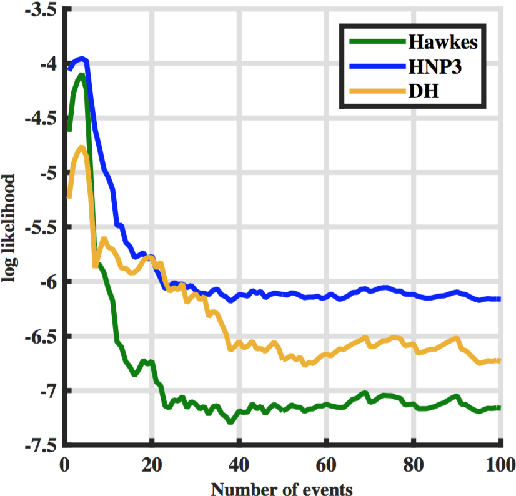
This paper introduces a novel framework for modeling temporal events with complex longitudinal dependency that are generated by dependent sources. This framework takes advantage of multidimensional point processes for modeling time of events. The intensity function of the proposed process is a mixture of intensities, and its complexity grows with the complexity of temporal patterns of data. Moreover, it utilizes a hierarchical dependent nonparametric approach to model marks of events. These capabilities allow the proposed model to adapt its temporal and topical complexity according to the complexity of data, which makes it a suitable candidate for real world scenarios. An online inference algorithm is also proposed that makes the framework applicable to a vast range of applications. The framework is applied to a real world application, modeling the diffusion of contents over networks. Extensive experiments reveal the effectiveness of the proposed framework in comparison with state-of-the-art methods.