 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Multiple Correct Answers -- A Trichotomy of Regret Bounds under Different Feedback Models
Feb 10, 2026We study an online learning problem with multiple correct answers, where each instance admits a set of valid labels, and in each round the learner must output a valid label for the queried example. This setting is motivated by language generation tasks, in which a prompt may admit many acceptable completions, but not every completion is acceptable. We study this problem under three feedback models. For each model, we characterize the optimal mistake bound in the realizable setting using an appropriate combinatorial dimension. We then establish a trichotomy of regret bounds across the three models in the agnostic setting. Our results also imply sample complexity bounds for the batch setup that depend on the respective combinatorial dimensions.
Learning Half-Spaces from Perturbed Contrastive Examples
Feb 02, 2026We study learning under a two-step contrastive example oracle, as introduced by Mansouri et. al. (2025), where each queried (or sampled) labeled example is paired with an additional contrastive example of opposite label. While Mansouri et al. assume an idealized setting, where the contrastive example is at minimum distance of the originally queried/sampled point, we introduce and analyze a mechanism, parameterized by a non-decreasing noise function $f$, under which this ideal contrastive example is perturbed. The amount of perturbation is controlled by $f(d)$, where $d$ is the distance of the queried/sampled point to the decision boundary. Intuitively, this results in higher-quality contrastive examples for points closer to the decision boundary. We study this model in two settings: (i) when the maximum perturbation magnitude is fixed, and (ii) when it is stochastic. For one-dimensional thresholds and for half-spaces under the uniform distribution on a bounded domain, we characterize active and passive contrastive sample complexity in dependence on the function $f$. We show that, under certain conditions on $f$, the presence of contrastive examples speeds up learning in terms of asymptotic query complexity and asymptotic expected query complexity.
Learning from positive and unlabeled examples -Finite size sample bounds
Jul 10, 2025PU (Positive Unlabeled) learning is a variant of supervised classification learning in which the only labels revealed to the learner are of positively labeled instances. PU learning arises in many real-world applications. Most existing work relies on the simplifying assumptions that the positively labeled training data is drawn from the restriction of the data generating distribution to positively labeled instances and/or that the proportion of positively labeled points (a.k.a. the class prior) is known apriori to the learner. This paper provides a theoretical analysis of the statistical complexity of PU learning under a wider range of setups. Unlike most prior work, our study does not assume that the class prior is known to the learner. We prove upper and lower bounds on the required sample sizes (of both the positively labeled and the unlabeled samples).
A Labelled Sample Compression Scheme of Size at Most Quadratic in the VC Dimension
Dec 28, 2022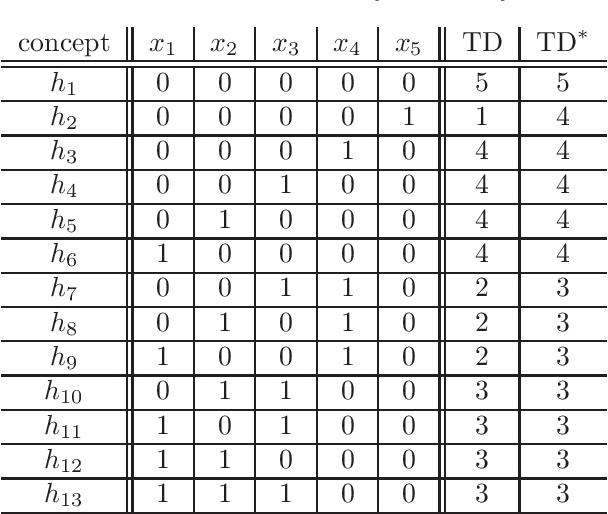
This paper presents a construction of a proper and stable labelled sample compression scheme of size $O(\VCD^2)$ for any finite concept class, where $\VCD$ denotes the Vapnik-Chervonenkis Dimension. The construction is based on a well-known model of machine teaching, referred to as recursive teaching dimension. This substantially improves on the currently best known bound on the size of sample compression schemes (due to Moran and Yehudayoff), which is exponential in $\VCD$. The long-standing open question whether the smallest size of a sample compression scheme is in $O(\VCD)$ remains unresolved, but our results show that research on machine teaching is a promising avenue for the study of this open problem. As further evidence of the strong connections between machine teaching and sample compression, we prove that the model of no-clash teaching, introduced by Kirkpatrick et al., can be used to define a non-trivial lower bound on the size of stable sample compression schemes.
Deep Reinforcement Learning for Online Control of Stochastic Partial Differential Equations
Oct 23, 2021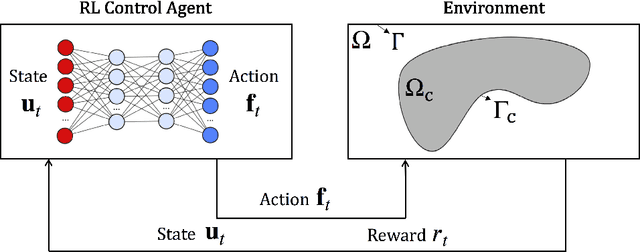

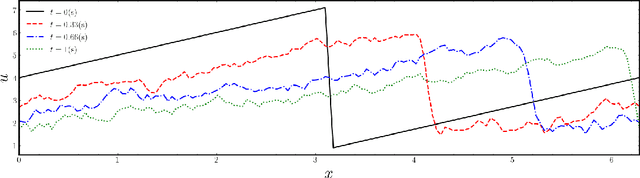
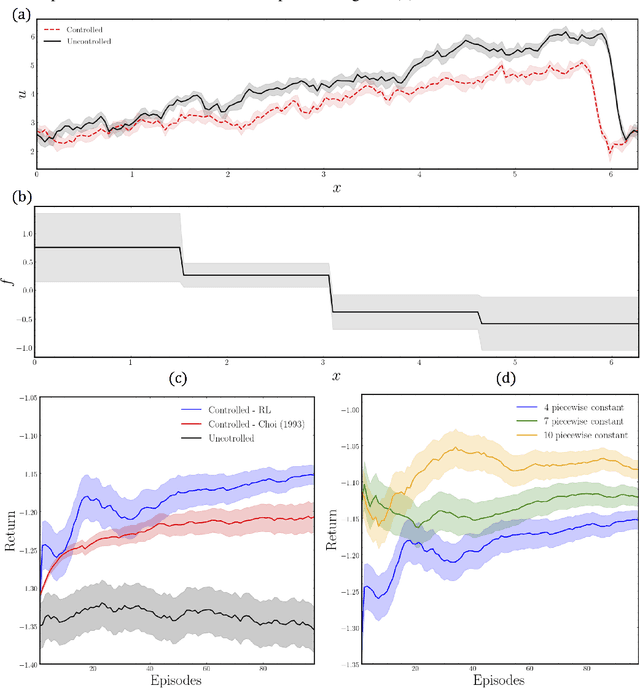
In many areas, such as the physical sciences, life sciences, and finance, control approaches are used to achieve a desired goal in complex dynamical systems governed by differential equations. In this work we formulate the problem of controlling stochastic partial differential equations (SPDE) as a reinforcement learning problem. We present a learning-based, distributed control approach for online control of a system of SPDEs with high dimensional state-action space using deep deterministic policy gradient method. We tested the performance of our method on the problem of controlling the stochastic Burgers' equation, describing a turbulent fluid flow in an infinitely large domain.
Preference-Based Batch and Sequential Teaching
Oct 17, 2020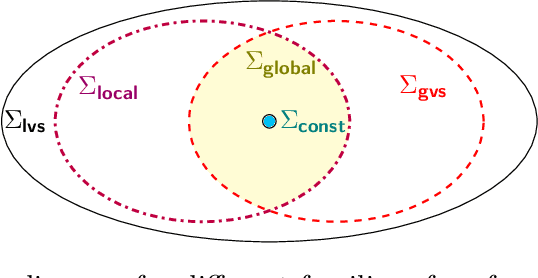
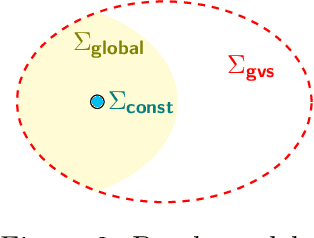

Algorithmic machine teaching studies the interaction between a teacher and a learner where the teacher selects labeled examples aiming at teaching a target hypothesis. In a quest to lower teaching complexity, several teaching models and complexity measures have been proposed for both the batch settings (e.g., worst-case, recursive, preference-based, and non-clashing models) and the sequential settings (e.g., local preference-based model). To better understand the connections between these models, we develop a novel framework that captures the teaching process via preference functions $\Sigma$. In our framework, each function $\sigma \in \Sigma$ induces a teacher-learner pair with teaching complexity as $TD(\sigma)$. We show that the above-mentioned teaching models are equivalent to specific types/families of preference functions. We analyze several properties of the teaching complexity parameter $TD(\sigma)$ associated with different families of the preference functions, e.g., comparison to the VC dimension of the hypothesis class and additivity/sub-additivity of $TD(\sigma)$ over disjoint domains. Finally, we identify preference functions inducing a novel family of sequential models with teaching complexity linear in the VC dimension: this is in contrast to the best-known complexity result for the batch models, which is quadratic in the VC dimension.
Understanding the Power and Limitations of Teaching with Imperfect Knowledge
Mar 21, 2020
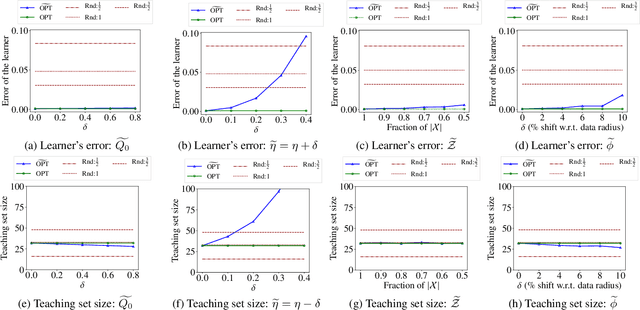
Machine teaching studies the interaction between a teacher and a student/learner where the teacher selects training examples for the learner to learn a specific task. The typical assumption is that the teacher has perfect knowledge of the task---this knowledge comprises knowing the desired learning target, having the exact task representation used by the learner, and knowing the parameters capturing the learning dynamics of the learner. Inspired by real-world applications of machine teaching in education, we consider the setting where teacher's knowledge is limited and noisy, and the key research question we study is the following: When does a teacher succeed or fail in effectively teaching a learner using its imperfect knowledge? We answer this question by showing connections to how imperfect knowledge affects the teacher's solution of the corresponding machine teaching problem when constructing optimal teaching sets. Our results have important implications for designing robust teaching algorithms for real-world applications.
Preference-Based Batch and Sequential Teaching: Towards a Unified View of Models
Oct 24, 2019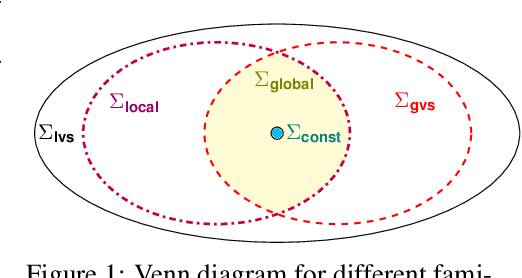

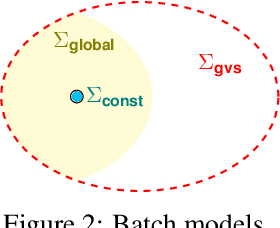
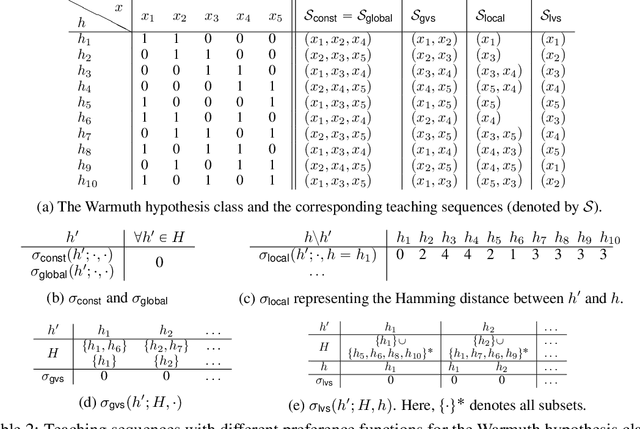
Algorithmic machine teaching studies the interaction between a teacher and a learner where the teacher selects labeled examples aiming at teaching a target hypothesis. In a quest to lower teaching complexity and to achieve more natural teacher-learner interactions, several teaching models and complexity measures have been proposed for both the batch settings (e.g., worst-case, recursive, preference-based, and non-clashing models) as well as the sequential settings (e.g., local preference-based model). To better understand the connections between these different batch and sequential models, we develop a novel framework which captures the teaching process via preference functions $\Sigma$. In our framework, each function $\sigma \in \Sigma$ induces a teacher-learner pair with teaching complexity as $\TD(\sigma)$. We show that the above-mentioned teaching models are equivalent to specific types/families of preference functions in our framework. This equivalence, in turn, allows us to study the differences between two important teaching models, namely $\sigma$ functions inducing the strongest batch (i.e., non-clashing) model and $\sigma$ functions inducing a weak sequential (i.e., local preference-based) model. Finally, we identify preference functions inducing a novel family of sequential models with teaching complexity linear in the VC dimension of the hypothesis class: this is in contrast to the best known complexity result for the batch models which is quadratic in the VC dimension.
ChOracle: A Unified Statistical Framework for Churn Prediction
Sep 15, 2019
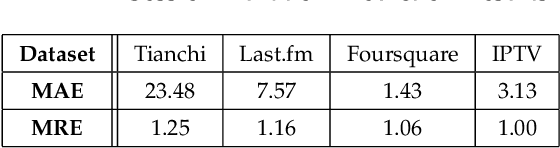


User churn is an important issue in online services that threatens the health and profitability of services. Most of the previous works on churn prediction convert the problem into a binary classification task where the users are labeled as churned and non-churned. More recently, some works have tried to convert the user churn prediction problem into the prediction of user return time. In this approach which is more realistic in real world online services, at each time-step the model predicts the user return time instead of predicting a churn label. However, the previous works in this category suffer from lack of generality and require high computational complexity. In this paper, we introduce \emph{ChOracle}, an oracle that predicts the user churn by modeling the user return times to service by utilizing a combination of Temporal Point Processes and Recurrent Neural Networks. Moreover, we incorporate latent variables into the proposed recurrent neural network to model the latent user loyalty to the system. We also develop an efficient approximate variational algorithm for learning parameters of the proposed RNN by using back propagation through time. Finally, we demonstrate the superior performance of ChOracle on a wide variety of real world datasets.