 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Design for Reinforcement Learning Agents
Mar 27, 2025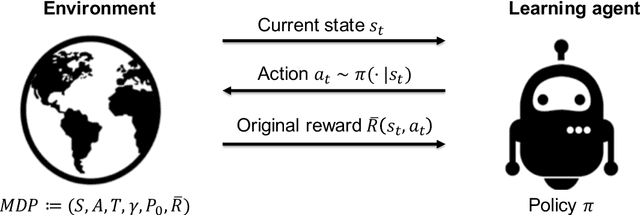
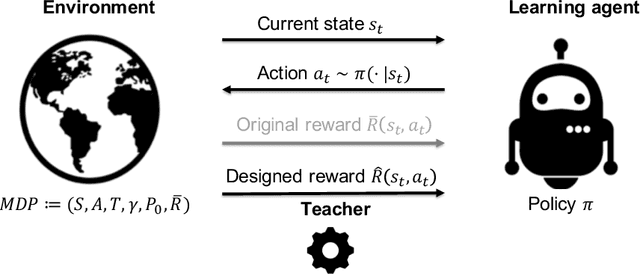

Reward functions are central in reinforcement learning (RL), guiding agents towards optimal decision-making. The complexity of RL tasks requires meticulously designed reward functions that effectively drive learning while avoiding unintended consequences. Effective reward design aims to provide signals that accelerate the agent's convergence to optimal behavior. Crafting rewards that align with task objectives, foster desired behaviors, and prevent undesirable actions is inherently challenging. This thesis delves into the critical role of reward signals in RL, highlighting their impact on the agent's behavior and learning dynamics and addressing challenges such as delayed, ambiguous, or intricate rewards. In this thesis work, we tackle different aspects of reward shaping. First, we address the problem of designing informative and interpretable reward signals from a teacher's/expert's perspective (teacher-driven). Here, the expert, equipped with the optimal policy and the corresponding value function, designs reward signals that expedite the agent's convergence to optimal behavior. Second, we build on this teacher-driven approach by introducing a novel method for adaptive interpretable reward design. In this scenario, the expert tailors the rewards based on the learner's current policy, ensuring alignment and optimal progression. Third, we propose a meta-learning approach, enabling the agent to self-design its reward signals online without expert input (agent-driven). This self-driven method considers the agent's learning and exploration to establish a self-improving feedback loop.
Informativeness of Reward Functions in Reinforcement Learning
Feb 10, 2024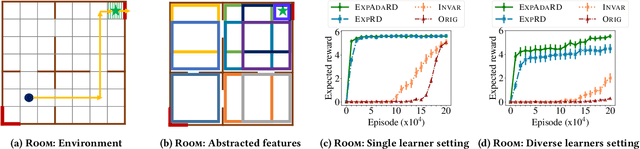
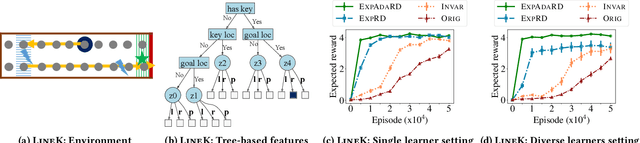
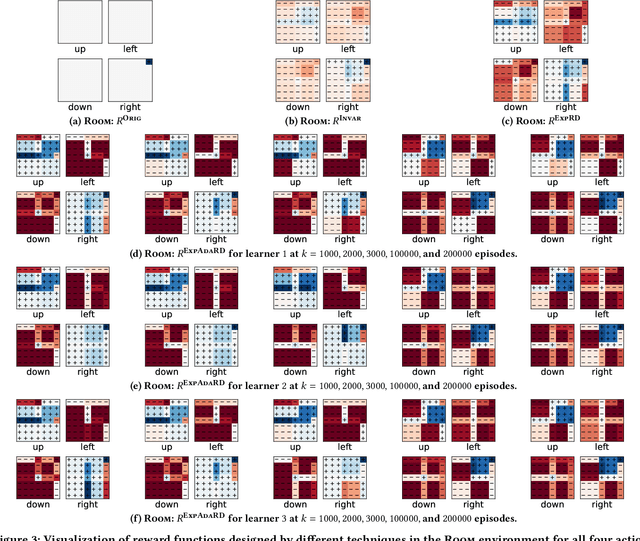
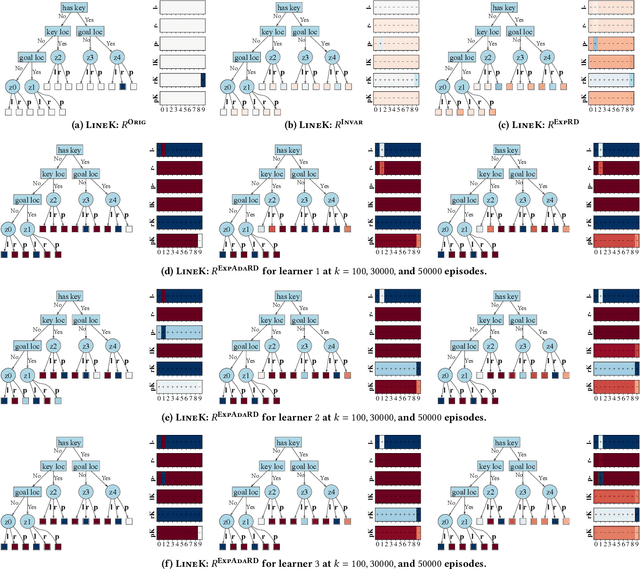
Reward functions are central in specifying the task we want a reinforcement learning agent to perform. Given a task and desired optimal behavior, we study the problem of designing informative reward functions so that the designed rewards speed up the agent's convergence. In particular, we consider expert-driven reward design settings where an expert or teacher seeks to provide informative and interpretable rewards to a learning agent. Existing works have considered several different reward design formulations; however, the key challenge is formulating a reward informativeness criterion that adapts w.r.t. the agent's current policy and can be optimized under specified structural constraints to obtain interpretable rewards. In this paper, we propose a novel reward informativeness criterion, a quantitative measure that captures how the agent's current policy will improve if it receives rewards from a specific reward function. We theoretically showcase the utility of the proposed informativeness criterion for adaptively designing rewards for an agent. Experimental results on two navigation tasks demonstrate the effectiveness of our adaptive reward informativeness criterion.
Potential-based reward shaping for learning to play text-based adventure games
Feb 21, 2023Text-based games are a popular testbed for language-based reinforcement learning (RL). In previous work, deep Q-learning is commonly used as the learning agent. Q-learning algorithms are challenging to apply to complex real-world domains due to, for example, their instability in training. Therefore, in this paper, we adapt the soft-actor-critic (SAC) algorithm to the text-based environment. To deal with sparse extrinsic rewards from the environment, we combine it with a potential-based reward shaping technique to provide more informative (dense) reward signals to the RL agent. We apply our method to play difficult text-based games. The SAC method achieves higher scores than the Q-learning methods on many games with only half the number of training steps. This shows that it is well-suited for text-based games. Moreover, we show that the reward shaping technique helps the agent to learn the policy faster and achieve higher scores. In particular, we consider a dynamically learned value function as a potential function for shaping the learner's original sparse reward signals.
Curriculum Design for Teaching via Demonstrations: Theory and Applications
Jun 08, 2021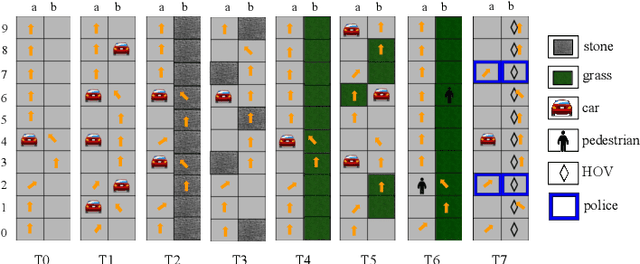

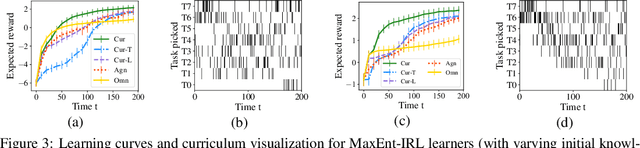
We consider the problem of teaching via demonstrations in sequential decision-making settings. In particular, we study how to design a personalized curriculum over demonstrations to speed up the learner's convergence. We provide a unified curriculum strategy for two popular learner models: Maximum Causal Entropy Inverse Reinforcement Learning (MaxEnt-IRL) and Cross-Entropy Behavioral Cloning (CrossEnt-BC). Our unified strategy induces a ranking over demonstrations based on a notion of difficulty scores computed w.r.t. the teacher's optimal policy and the learner's current policy. Compared to the state of the art, our strategy doesn't require access to the learner's internal dynamics and still enjoys similar convergence guarantees under mild technical conditions. Furthermore, we adapt our curriculum strategy to teach a learner using domain knowledge in the form of task-specific difficulty scores when the teacher's optimal policy is unknown. Experiments on a car driving simulator environment and shortest path problems in a grid-world environment demonstrate the effectiveness of our proposed curriculum strategy.
Policy Teaching in Reinforcement Learning via Environment Poisoning Attacks
Nov 21, 2020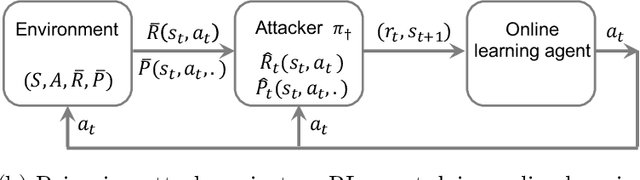
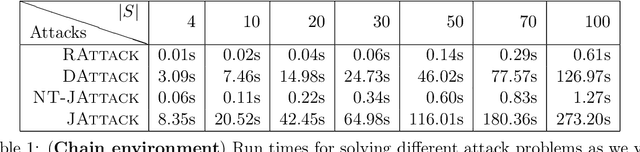
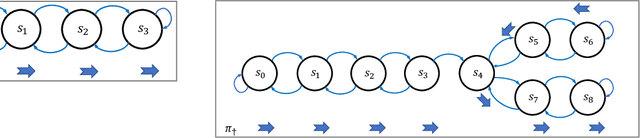
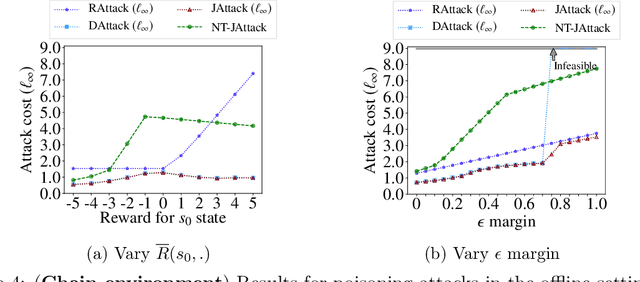
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes reward in infinite-horizon problem settings. The attacker can manipulate the rewards and the transition dynamics in the learning environment at training-time, and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an optimal stealthy attack for different measures of attack cost. We provide lower/upper bounds on the attack cost, and instantiate our attacks in two settings: (i) an offline setting where the agent is doing planning in the poisoned environment, and (ii) an online setting where the agent is learning a policy with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.
Environment Shaping in Reinforcement Learning using State Abstraction
Jun 23, 2020
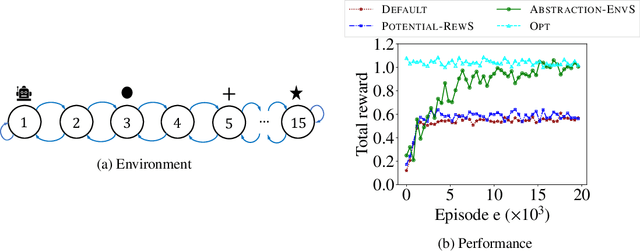
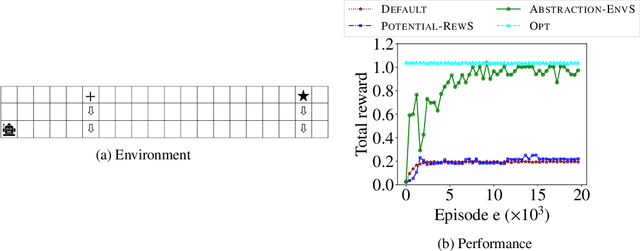
One of the central challenges faced by a reinforcement learning (RL) agent is to effectively learn a (near-)optimal policy in environments with large state spaces having sparse and noisy feedback signals. In real-world applications, an expert with additional domain knowledge can help in speeding up the learning process via \emph{shaping the environment}, i.e., making the environment more learner-friendly. A popular paradigm in literature is \emph{potential-based reward shaping}, where the environment's reward function is augmented with additional local rewards using a potential function. However, the applicability of potential-based reward shaping is limited in settings where (i) the state space is very large, and it is challenging to compute an appropriate potential function, (ii) the feedback signals are noisy, and even with shaped rewards the agent could be trapped in local optima, and (iii) changing the rewards alone is not sufficient, and effective shaping requires changing the dynamics. We address these limitations of potential-based shaping methods and propose a novel framework of \emph{environment shaping using state abstraction}. Our key idea is to compress the environment's large state space with noisy signals to an abstracted space, and to use this abstraction in creating smoother and more effective feedback signals for the agent. We study the theoretical underpinnings of our abstraction-based environment shaping, and show that the agent's policy learnt in the shaped environment preserves near-optimal behavior in the original environment.
Policy Teaching via Environment Poisoning: Training-time Adversarial Attacks against Reinforcement Learning
Mar 28, 2020
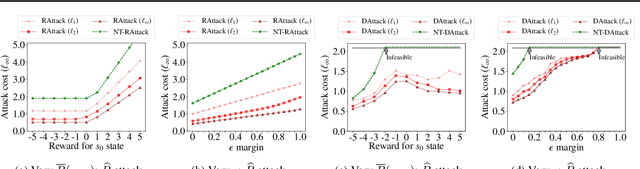
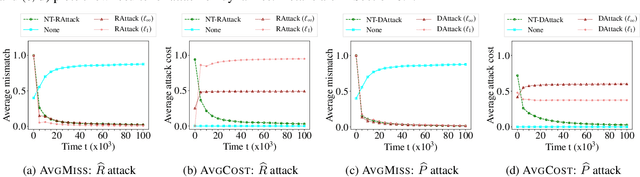
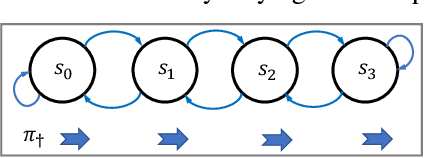
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes average reward in undiscounted infinite-horizon problem settings. The attacker can manipulate the rewards or the transition dynamics in the learning environment at training-time and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an \emph{optimal stealthy attack} for different measures of attack cost. We provide sufficient technical conditions under which the attack is feasible and provide lower/upper bounds on the attack cost. We instantiate our attacks in two settings: (i) an \emph{offline} setting where the agent is doing planning in the poisoned environment, and (ii) an \emph{online} setting where the agent is learning a policy using a regret-minimization framework with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.
Understanding the Power and Limitations of Teaching with Imperfect Knowledge
Mar 21, 2020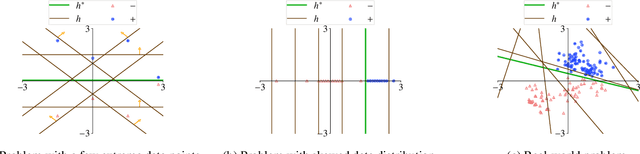
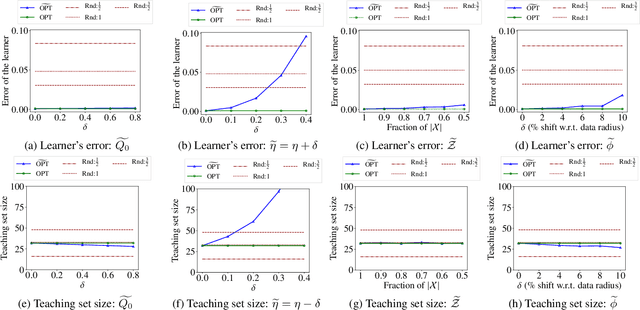
Machine teaching studies the interaction between a teacher and a student/learner where the teacher selects training examples for the learner to learn a specific task. The typical assumption is that the teacher has perfect knowledge of the task---this knowledge comprises knowing the desired learning target, having the exact task representation used by the learner, and knowing the parameters capturing the learning dynamics of the learner. Inspired by real-world applications of machine teaching in education, we consider the setting where teacher's knowledge is limited and noisy, and the key research question we study is the following: When does a teacher succeed or fail in effectively teaching a learner using its imperfect knowledge? We answer this question by showing connections to how imperfect knowledge affects the teacher's solution of the corresponding machine teaching problem when constructing optimal teaching sets. Our results have important implications for designing robust teaching algorithms for real-world applications.
Interactive Teaching Algorithms for Inverse Reinforcement Learning
Jun 05, 2019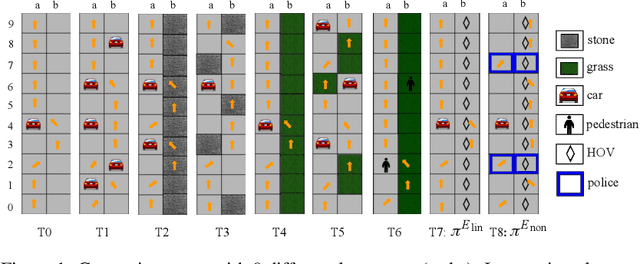

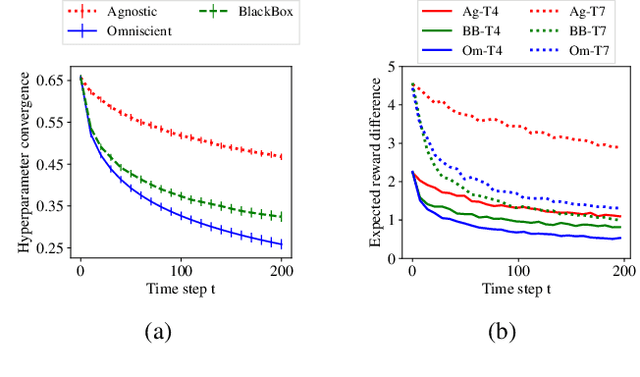
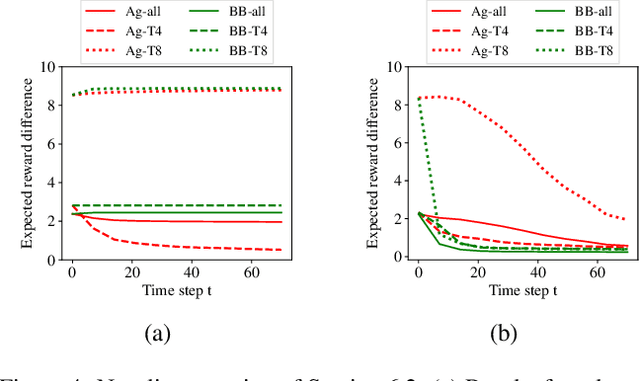
We study the problem of inverse reinforcement learning (IRL) with the added twist that the learner is assisted by a helpful teacher. More formally, we tackle the following algorithmic question: How could a teacher provide an informative sequence of demonstrations to an IRL learner to speed up the learning process? We present an interactive teaching framework where a teacher adaptively chooses the next demonstration based on learner's current policy. In particular, we design teaching algorithms for two concrete settings: an omniscient setting where a teacher has full knowledge about the learner's dynamics and a blackbox setting where the teacher has minimal knowledge. Then, we study a sequential variant of the popular MCE-IRL learner and prove convergence guarantees of our teaching algorithm in the omniscient setting. Extensive experiments with a car driving simulator environment show that the learning progress can be speeded up drastically as compared to an uninformative teacher.
Learner-aware Teaching: Inverse Reinforcement Learning with Preferences and Constraints
Jun 02, 2019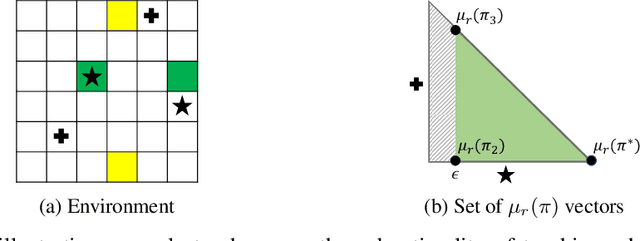

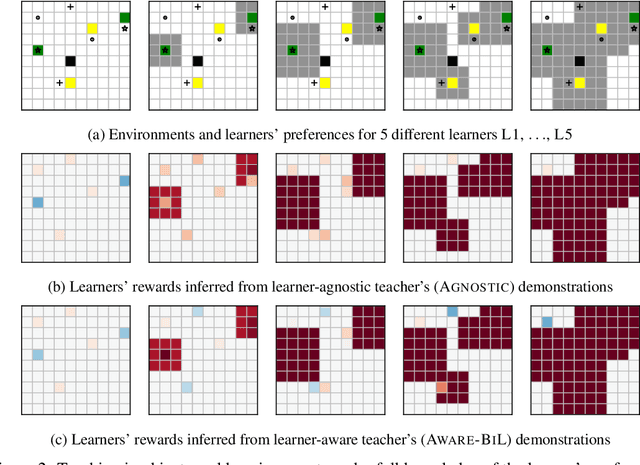

Inverse reinforcement learning (IRL) enables an agent to learn complex behavior by observing demonstrations from a (near-)optimal policy. The typical assumption is that the learner's goal is to match the teacher's demonstrated behavior. In this paper, we consider the setting where the learner has her own preferences that she additionally takes into consideration. These preferences can for example capture behavioral biases, mismatched worldviews, or physical constraints. We study two teaching approaches: learner-agnostic teaching, where the teacher provides demonstrations from an optimal policy ignoring the learner's preferences, and learner-aware teaching, where the teacher accounts for the learner's preferences. We design learner-aware teaching algorithms and show that significant performance improvements can be achieved over learner-agnostic teaching.