 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemRep: Generative Code Representation Learning with Code Transformations
Mar 13, 2026Code transformation is a foundational capability in the software development process, where its effectiveness relies on constructing a high-quality code representation to characterize the input code semantics and guide the transformation. Existing approaches treat code transformation as an end-to-end learning task, leaving the construction of the representation needed for semantic reasoning implicit in model weights or relying on rigid compiler-level abstractions. We present SemRep, a framework that improves code transformation through generative code representation learning. Our key insight is to employ the semantics-preserving transformations as the intermediate representation, which serves as both a generative mid-training task and the guidance for subsequent instruction-specific code transformations. Across general code editing and optimization tasks (e.g., GPU kernel optimization), SemRep outperforms the extensively finetuned baselines with strictly the same training budget by 6.9% in correctness, 1.1x in performance, 13.9% in generalization, and 6.7% in robustness. With the improved exploration of diverse code transformations, SemRep is particularly amenable to evolutionary search. Combined with an evolutionary coding agent, SemRep finds optimizations that 685B larger-weight baselines fail to discover while achieving the same performance with 25% less inference compute.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
rLLM: Relational Table Learning with LLMs
Jul 29, 2024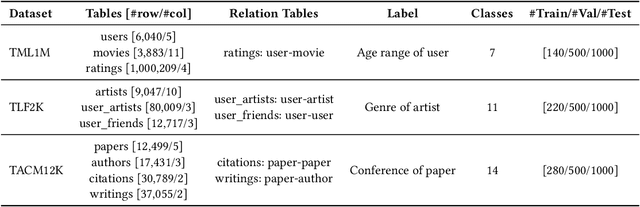
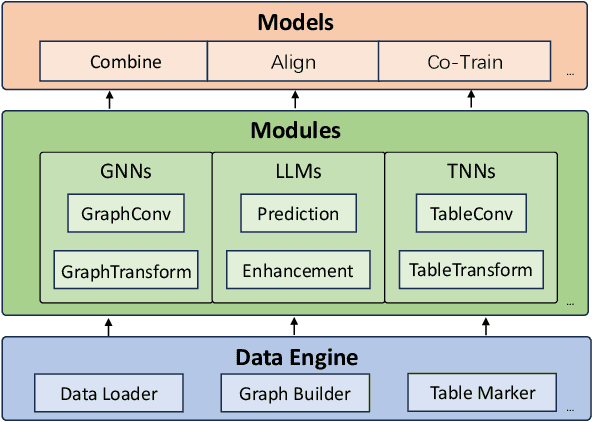
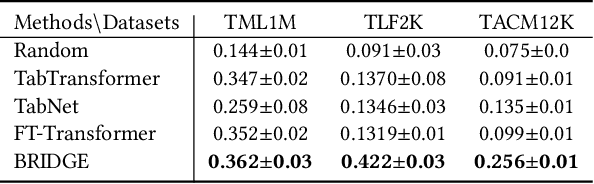
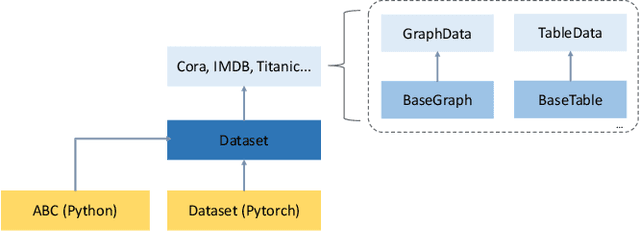
We introduce rLLM (relationLLM), a PyTorch library designed for Relational Table Learning (RTL) with Large Language Models (LLMs). The core idea is to decompose state-of-the-art Graph Neural Networks, LLMs, and Table Neural Networks into standardized modules, to enable the fast construction of novel RTL-type models in a simple "combine, align, and co-train" manner. To illustrate the usage of rLLM, we introduce a simple RTL method named \textbf{BRIDGE}. Additionally, we present three novel relational tabular datasets (TML1M, TLF2K, and TACM12K) by enhancing classic datasets. We hope rLLM can serve as a useful and easy-to-use development framework for RTL-related tasks. Our code is available at: https://github.com/rllm-project/rllm.
Symmetry-Preserving Program Representations for Learning Code Semantics
Aug 07, 2023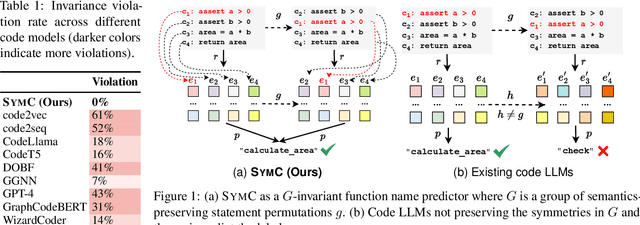
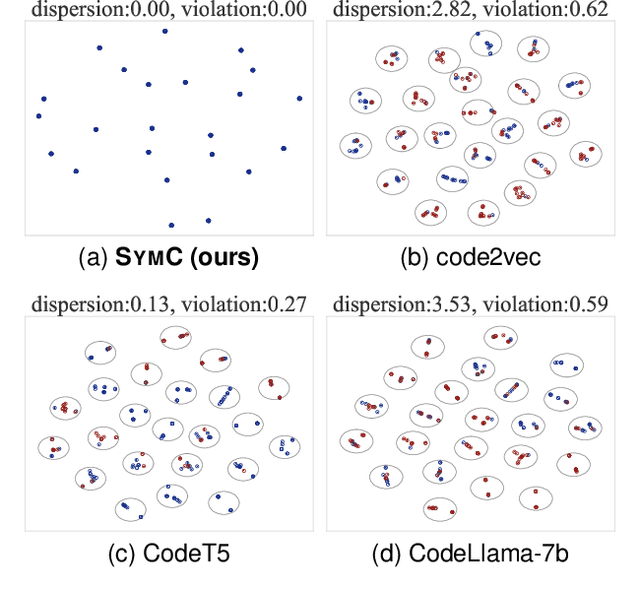
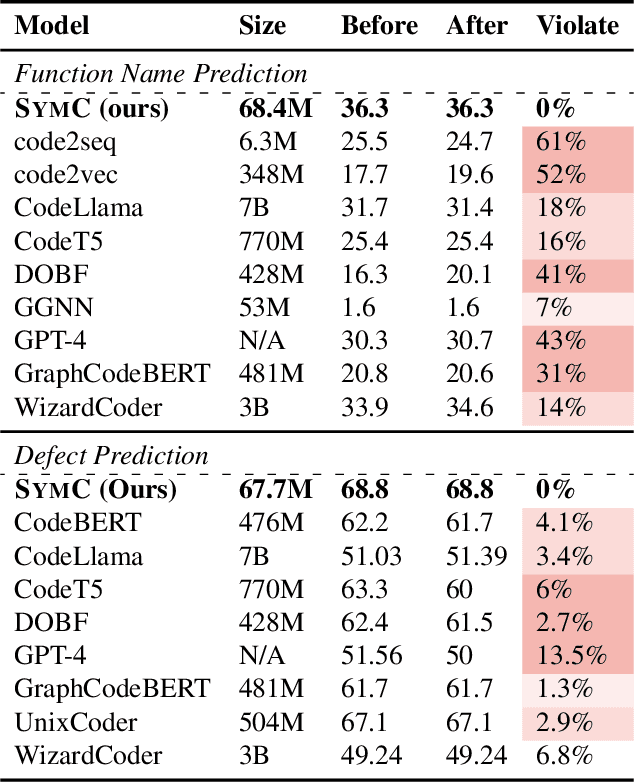
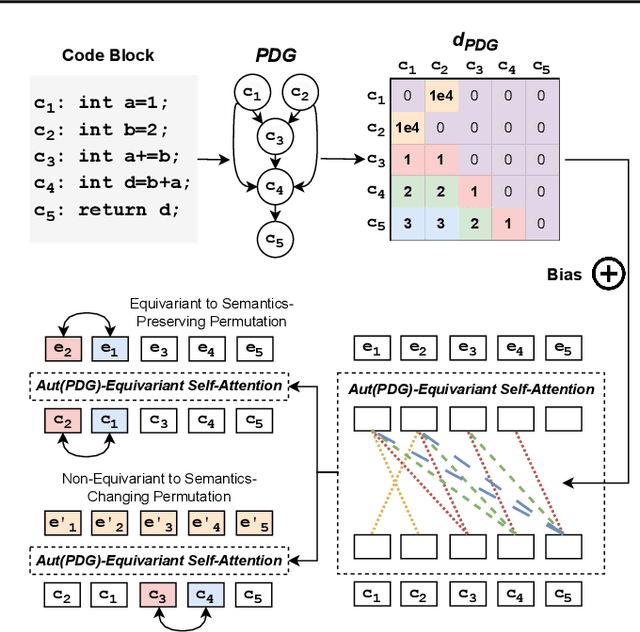
Large Language Models (LLMs) have shown promise in automated program reasoning, a crucial aspect of many security tasks. However, existing LLM architectures for code are often borrowed from other domains like natural language processing, raising concerns about their generalization and robustness to unseen code. A key generalization challenge is to incorporate the knowledge of code semantics, including control and data flow, into the LLM architectures. Drawing inspiration from examples of convolution layers exploiting translation symmetry, we explore how code symmetries can enhance LLM architectures for program analysis and modeling. We present a rigorous group-theoretic framework that formally defines code symmetries as semantics-preserving transformations and provides techniques for precisely reasoning about symmetry preservation within LLM architectures. Using this framework, we introduce a novel variant of self-attention that preserves program symmetries, demonstrating its effectiveness in generalization and robustness through detailed experimental evaluations across different binary and source code analysis tasks. Overall, our code symmetry framework offers rigorous and powerful reasoning techniques that can guide the future development of specialized LLMs for code and advance LLM-guided program reasoning tasks.
Potential-based reward shaping for learning to play text-based adventure games
Feb 21, 2023Text-based games are a popular testbed for language-based reinforcement learning (RL). In previous work, deep Q-learning is commonly used as the learning agent. Q-learning algorithms are challenging to apply to complex real-world domains due to, for example, their instability in training. Therefore, in this paper, we adapt the soft-actor-critic (SAC) algorithm to the text-based environment. To deal with sparse extrinsic rewards from the environment, we combine it with a potential-based reward shaping technique to provide more informative (dense) reward signals to the RL agent. We apply our method to play difficult text-based games. The SAC method achieves higher scores than the Q-learning methods on many games with only half the number of training steps. This shows that it is well-suited for text-based games. Moreover, we show that the reward shaping technique helps the agent to learn the policy faster and achieve higher scores. In particular, we consider a dynamically learned value function as a potential function for shaping the learner's original sparse reward signals.