 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Should I Cite? A RAG Benchmark for Academic Citation Prediction
Jan 21, 2026With the rapid growth of Web-based academic publications, more and more papers are being published annually, making it increasingly difficult to find relevant prior work. Citation prediction aims to automatically suggest appropriate references, helping scholars navigate the expanding scientific literature. Here we present \textbf{CiteRAG}, the first comprehensive retrieval-augmented generation (RAG)-integrated benchmark for evaluating large language models on academic citation prediction, featuring a multi-level retrieval strategy, specialized retrievers, and generators. Our benchmark makes four core contributions: (1) We establish two instances of the citation prediction task with different granularity. Task 1 focuses on coarse-grained list-specific citation prediction, while Task 2 targets fine-grained position-specific citation prediction. To enhance these two tasks, we build a dataset containing 7,267 instances for Task 1 and 8,541 instances for Task 2, enabling comprehensive evaluation of both retrieval and generation. (2) We construct a three-level large-scale corpus with 554k papers spanning many major subfields, using an incremental pipeline. (3) We propose a multi-level hybrid RAG approach for citation prediction, fine-tuning embedding models with contrastive learning to capture complex citation relationships, paired with specialized generation models. (4) We conduct extensive experiments across state-of-the-art language models, including closed-source APIs, open-source models, and our fine-tuned generators, demonstrating the effectiveness of our framework. Our open-source toolkit enables reproducible evaluation and focuses on academic literature, providing the first comprehensive evaluation framework for citation prediction and serving as a methodological template for other scientific domains. Our source code and data are released at https://github.com/LQgdwind/CiteRAG.
What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
Dec 11, 2024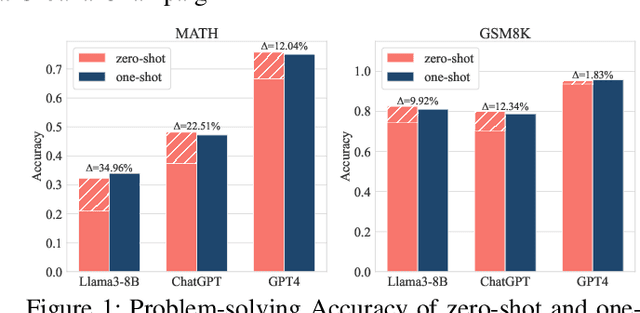
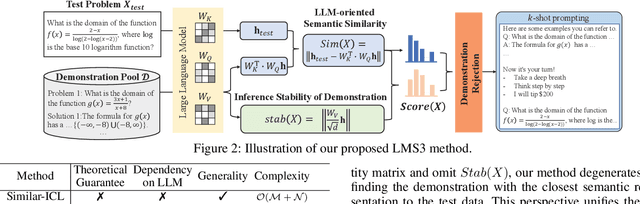
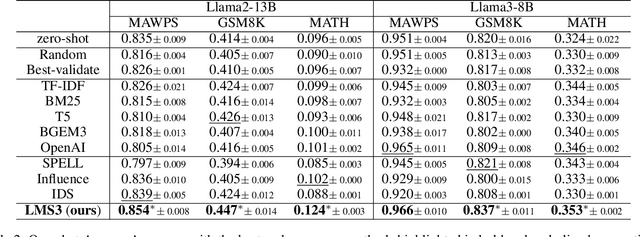
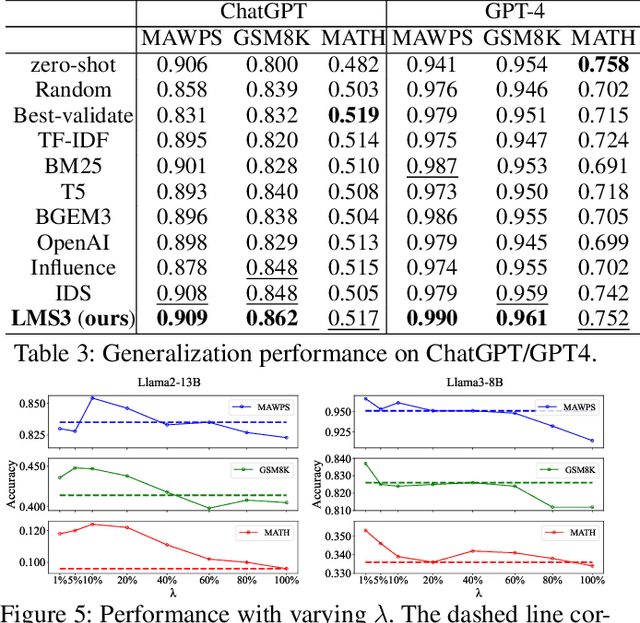
Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
rLLM: Relational Table Learning with LLMs
Jul 29, 2024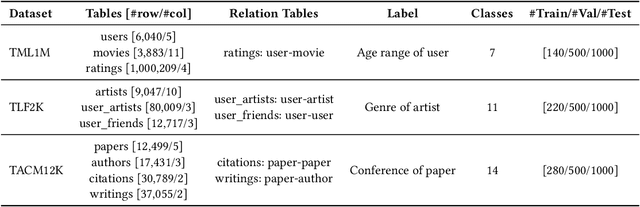
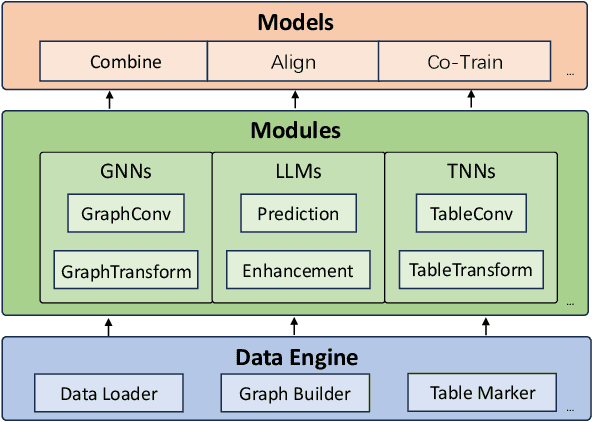
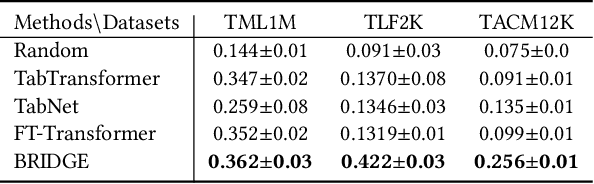
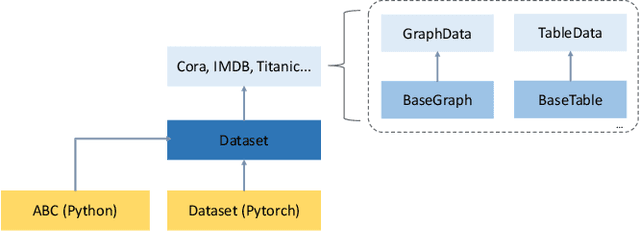
We introduce rLLM (relationLLM), a PyTorch library designed for Relational Table Learning (RTL) with Large Language Models (LLMs). The core idea is to decompose state-of-the-art Graph Neural Networks, LLMs, and Table Neural Networks into standardized modules, to enable the fast construction of novel RTL-type models in a simple "combine, align, and co-train" manner. To illustrate the usage of rLLM, we introduce a simple RTL method named \textbf{BRIDGE}. Additionally, we present three novel relational tabular datasets (TML1M, TLF2K, and TACM12K) by enhancing classic datasets. We hope rLLM can serve as a useful and easy-to-use development framework for RTL-related tasks. Our code is available at: https://github.com/rllm-project/rllm.
Graph Contrastive Learning with Generative Adversarial Network
Aug 01, 2023



Graph Neural Networks (GNNs) have demonstrated promising results on exploiting node representations for many downstream tasks through supervised end-to-end training. To deal with the widespread label scarcity issue in real-world applications, Graph Contrastive Learning (GCL) is leveraged to train GNNs with limited or even no labels by maximizing the mutual information between nodes in its augmented views generated from the original graph. However, the distribution of graphs remains unconsidered in view generation, resulting in the ignorance of unseen edges in most existing literature, which is empirically shown to be able to improve GCL's performance in our experiments. To this end, we propose to incorporate graph generative adversarial networks (GANs) to learn the distribution of views for GCL, in order to i) automatically capture the characteristic of graphs for augmentations, and ii) jointly train the graph GAN model and the GCL model. Specifically, we present GACN, a novel Generative Adversarial Contrastive learning Network for graph representation learning. GACN develops a view generator and a view discriminator to generate augmented views automatically in an adversarial style. Then, GACN leverages these views to train a GNN encoder with two carefully designed self-supervised learning losses, including the graph contrastive loss and the Bayesian personalized ranking Loss. Furthermore, we design an optimization framework to train all GACN modules jointly. Extensive experiments on seven real-world datasets show that GACN is able to generate high-quality augmented views for GCL and is superior to twelve state-of-the-art baseline methods. Noticeably, our proposed GACN surprisingly discovers that the generated views in data augmentation finally conform to the well-known preferential attachment rule in online networks.
PANE-GNN: Unifying Positive and Negative Edges in Graph Neural Networks for Recommendation
Jun 08, 2023



Recommender systems play a crucial role in addressing the issue of information overload by delivering personalized recommendations to users. In recent years, there has been a growing interest in leveraging graph neural networks (GNNs) for recommender systems, capitalizing on advancements in graph representation learning. These GNN-based models primarily focus on analyzing users' positive feedback while overlooking the valuable insights provided by their negative feedback. In this paper, we propose PANE-GNN, an innovative recommendation model that unifies Positive And Negative Edges in Graph Neural Networks for recommendation. By incorporating user preferences and dispreferences, our approach enhances the capability of recommender systems to offer personalized suggestions. PANE-GNN first partitions the raw rating graph into two distinct bipartite graphs based on positive and negative feedback. Subsequently, we employ two separate embeddings, the interest embedding and the disinterest embedding, to capture users' likes and dislikes, respectively. To facilitate effective information propagation, we design distinct message-passing mechanisms for positive and negative feedback. Furthermore, we introduce a distortion to the negative graph, which exclusively consists of negative feedback edges, for contrastive training. This distortion plays a crucial role in effectively denoising the negative feedback. The experimental results provide compelling evidence that PANE-GNN surpasses the existing state-of-the-art benchmark methods across four real-world datasets. These datasets include three commonly used recommender system datasets and one open-source short video recommendation dataset.
Knowledge Distillation based Contextual Relevance Matching for E-commerce Product Search
Oct 04, 2022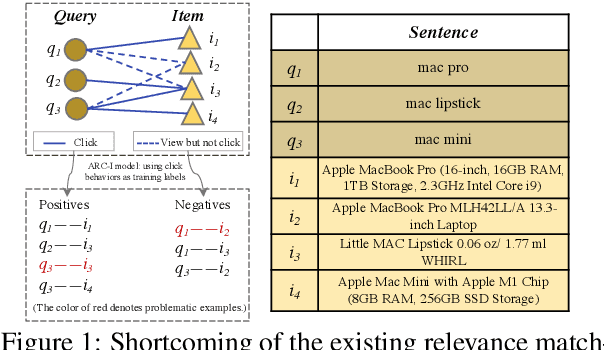
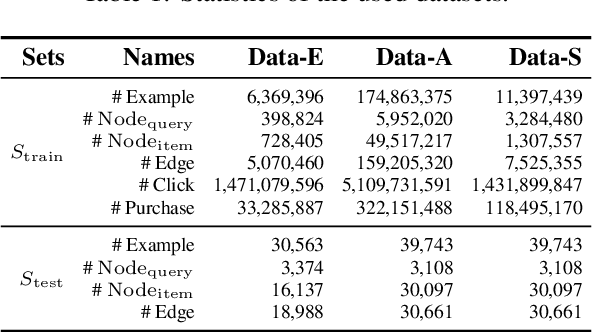
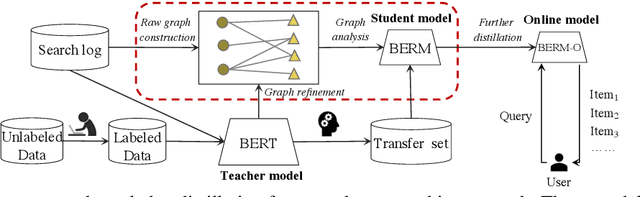
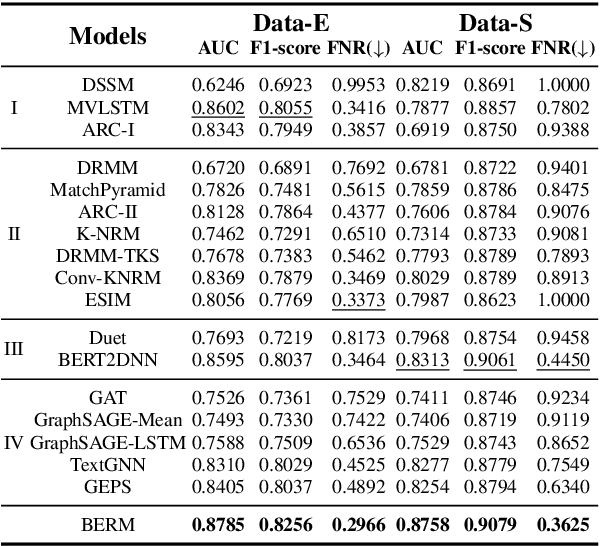
Online relevance matching is an essential task of e-commerce product search to boost the utility of search engines and ensure a smooth user experience. Previous work adopts either classical relevance matching models or Transformer-style models to address it. However, they ignore the inherent bipartite graph structures that are ubiquitous in e-commerce product search logs and are too inefficient to deploy online. In this paper, we design an efficient knowledge distillation framework for e-commerce relevance matching to integrate the respective advantages of Transformer-style models and classical relevance matching models. Especially for the core student model of the framework, we propose a novel method using $k$-order relevance modeling. The experimental results on large-scale real-world data (the size is 6$\sim$174 million) show that the proposed method significantly improves the prediction accuracy in terms of human relevance judgment. We deploy our method to the anonymous online search platform. The A/B testing results show that our method significantly improves 5.7% of UV-value under price sort mode.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022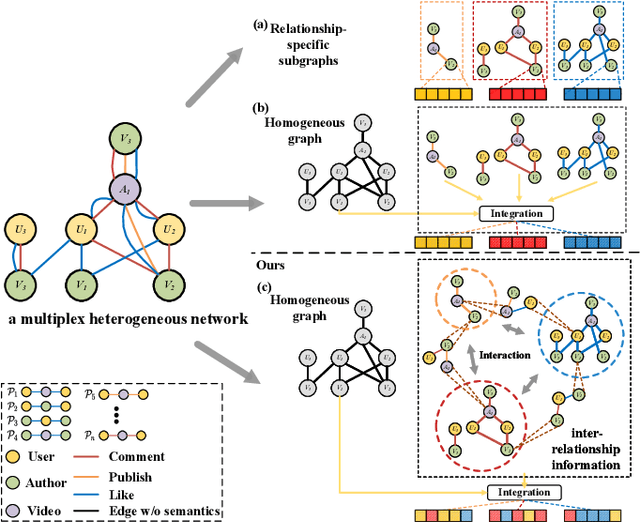
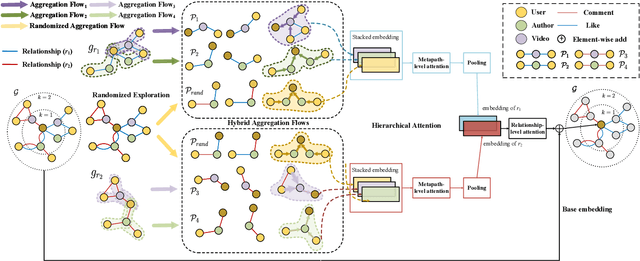
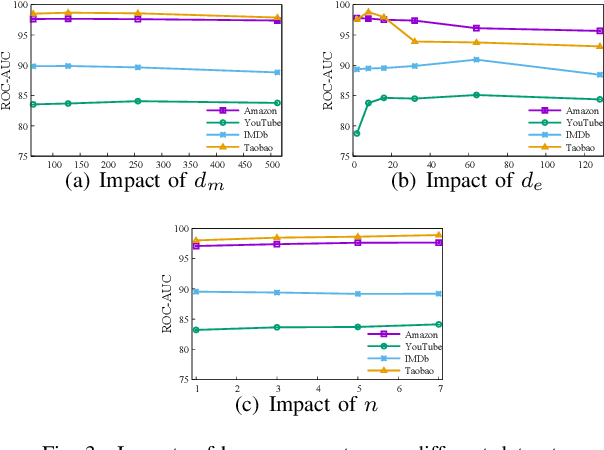
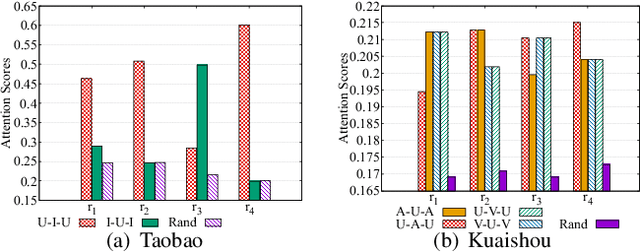
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
Expanding Semantic Knowledge for Zero-shot Graph Embedding
Mar 23, 2021
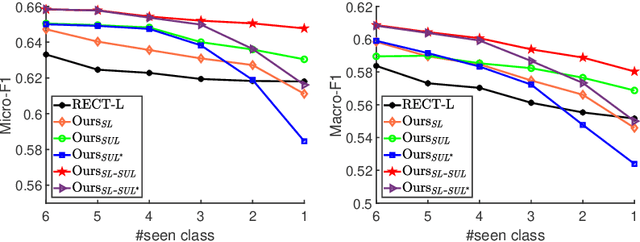
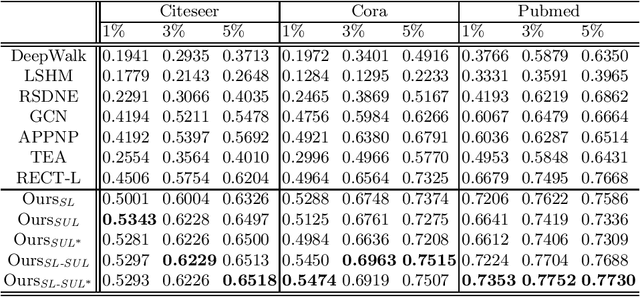
Zero-shot graph embedding is a major challenge for supervised graph learning. Although a recent method RECT has shown promising performance, its working mechanisms are not clear and still needs lots of training data. In this paper, we give deep insights into RECT, and address its fundamental limits. We show that its core part is a GNN prototypical model in which a class prototype is described by its mean feature vector. As such, RECT maps nodes from the raw-input feature space into an intermediate-level semantic space that connects the raw-input features to both seen and unseen classes. This mechanism makes RECT work well on both seen and unseen classes, which however also reduces the discrimination. To realize its full potentials, we propose two label expansion strategies. Specifically, besides expanding the labeled node set of seen classes, we can also expand that of unseen classes. Experiments on real-world datasets validate the superiority of our methods.
Network Embedding with Completely-imbalanced Labels
Jul 07, 2020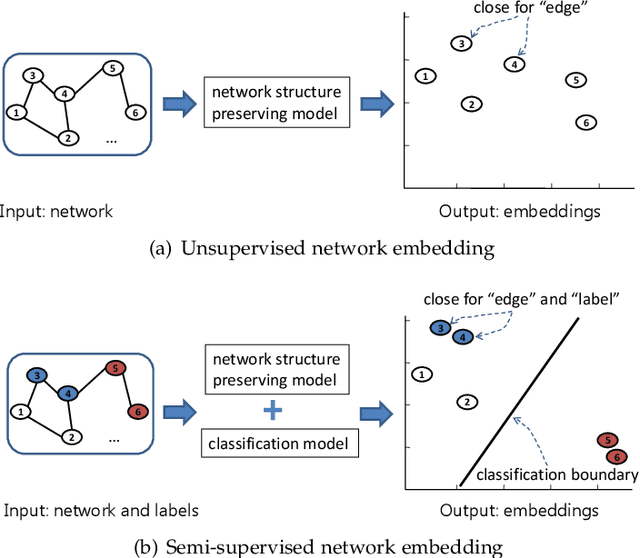
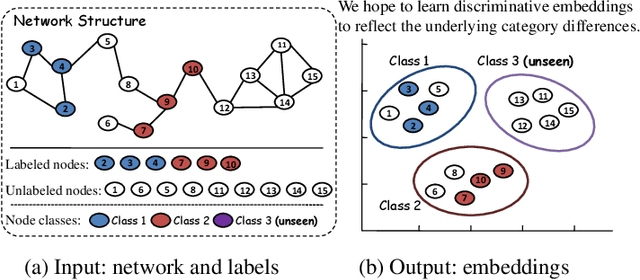


Network embedding, aiming to project a network into a low-dimensional space, is increasingly becoming a focus of network research. Semi-supervised network embedding takes advantage of labeled data, and has shown promising performance. However, existing semi-supervised methods would get unappealing results in the completely-imbalanced label setting where some classes have no labeled nodes at all. To alleviate this, we propose two novel semi-supervised network embedding methods. The first one is a shallow method named RSDNE. Specifically, to benefit from the completely-imbalanced labels, RSDNE guarantees both intra-class similarity and inter-class dissimilarity in an approximate way. The other method is RECT which is a new class of graph neural networks. Different from RSDNE, to benefit from the completely-imbalanced labels, RECT explores the class-semantic knowledge. This enables RECT to handle networks with node features and multi-label setting. Experimental results on several real-world datasets demonstrate the superiority of the proposed methods.