 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocraticPO: Policy Optimization via Interactive Guidance
Jun 03, 2026Reinforcement learning (RL) for large language models usually supervises reasoning with scalar outcome rewards, such as binary correctness. Such rewards provide an optimization direction but rarely explain how a model should revise its mistaken reasoning, which can encourage shortcut learning and brittle policies. We propose \textbf{SocraticPO} (Socratic Policy Optimization), a policy-optimization framework that augments RL rollouts with Socratic-style natural-language guidance. During rollout, the student first answers independently; if the answer is incorrect, a teacher diagnoses the attempt and provides concise corrective guidance, after which the student continues under the expanded context. Crucially, this guidance is paired with reward decay: correct answers obtained after teacher intervention only receive decayed rewards, preventing the policy from treating teacher help as a free path to reward. Since SocraticPO only modifies the rollout process while leaving the standard expected-reward objective intact, it can be plugged into existing policy-gradient backends such as Reinforce++. Moreover, because the teacher provides only text-level guidance, SocraticPO can leverage stronger black-box teacher models without requiring access to logits or distribution matching. On undergraduate-level scientific reasoning benchmarks from SciKnowEval, SocraticPO improves over strong RL and self-distillation baselines. Ablations show that both targeted guidance and reward decay are necessary, with reward decay mitigating reliance on assisted correction.
SWE-Mutation: Can LLMs Generate Reliable Test Suites in Software Engineering?
May 21, 2026Evaluating software engineering capabilities has become a core component of modern large language models (LLMs); however, the key bottleneck hindering further scaling lies not in the scarcity of high-quality solutions, but in the lack of high-quality test suites. Test suites are indispensable both for synthesizing program repair trajectories and for providing precise feedback signals in reinforcement learning. Unfortunately, due to the high cost and difficulty of annotation, high-quality test suites have long been hard to obtain, while those automatically generated by LLMs tend to be superficial and lack sufficient discriminative power. As a first step toward constructing high-quality test suites, we introduce SWE-Mutation, a benchmark for evaluating LLM-generated test suites. The benchmark characterizes test suites by introducing systematically mutated solutions that attempt to ``fool'' the test suites and pass validation. We further propose an agentic, language-agnostic framework for automatically generating complex mutants. Our benchmark consists of 2,636 mutated variants derived from 800 original instances and includes a multilingual subset spanning nine programming languages. Experiments on seven LLMs reveal that even DeepSeek-V3.1 achieves only 10.20% verification and 36.15% detection rates, highlighting the inadequacy of current LLMs. Additionally, our agentic mutation strategy enhances realism, reducing average detection rates from 71.04% to 39.81% compared to conventional methods. These findings expose persistent deficiencies in the ability of current LLMs to generate reliable and discriminative test suites.
* 24 pages, 8 figures
What Really Improves Mathematical Reasoning: Structured Reasoning Signals Beyond Pure Code
May 19, 2026Code has become a standard component of modern foundation language model (LM) training, yet its role beyond programming remains unclear. We revisit the claim that code improves reasoning through controlled pretraining experiments on a 10T-token corpus with fine-grained domain separation. Our findings are threefold. First, when code is restricted to standalone executable programs and Code-NL data are controlled for, code substantially improves programming ability but does not act as a general reasoning enhancer; instead, it competes with knowledge-intensive tasks, especially complex mathematical reasoning. Second, the reasoning gains often attributed to code are better explained by cross-domain structured reasoning traces, such as code-text and math-text mixtures, rather than by executable code alone. Third, increasing the density of structured math-domain samples within a fixed math budget yields substantial gains on difficult mathematical reasoning while largely preserving programming performance, suggesting that cognitive scaffolds offer a targeted way to mitigate cross-domain trade-offs. Finally, routing analyses show that data-composition effects are reflected in expert-activation patterns, providing mechanism-level evidence for competitive and synergistic interactions across domains. Our results clarify which data characteristics transfer across capability dimensions and point to more precise data-centric optimization strategies.
Step-Level Sparse Autoencoder for Reasoning Process Interpretation
Mar 03, 2026Large Language Models (LLMs) have achieved strong complex reasoning capabilities through Chain-of-Thought (CoT) reasoning. However, their reasoning patterns remain too complicated to analyze. While Sparse Autoencoders (SAEs) have emerged as a powerful tool for interpretability, existing approaches predominantly operate at the token level, creating a granularity mismatch when capturing more critical step-level information, such as reasoning direction and semantic transitions. In this work, we propose step-level sparse autoencoder (SSAE), which serves as an analytical tool to disentangle different aspects of LLMs' reasoning steps into sparse features. Specifically, by precisely controlling the sparsity of a step feature conditioned on its context, we form an information bottleneck in step reconstruction, which splits incremental information from background information and disentangles it into several sparsely activated dimensions. Experiments on multiple base models and reasoning tasks show the effectiveness of the extracted features. By linear probing, we can easily predict surface-level information, such as generation length and first token distribution, as well as more complicated properties, such as the correctness and logicality of the step. These observations indicate that LLMs should already at least partly know about these properties during generation, which provides the foundation for the self-verification ability of LLMs. The code is available at https://github.com/Miaow-Lab/SSAE
UniCog: Uncovering Cognitive Abilities of LLMs through Latent Mind Space Analysis
Jan 25, 2026A growing body of research suggests that the cognitive processes of large language models (LLMs) differ fundamentally from those of humans. However, existing interpretability methods remain limited in explaining how cognitive abilities are engaged during LLM reasoning. In this paper, we propose UniCog, a unified framework that analyzes LLM cognition via a latent mind space. Formulated as a latent variable model, UniCog encodes diverse abilities from dense model activations into sparse, disentangled latent dimensions. Through extensive analysis on six advanced LLMs, including DeepSeek-V3.2 and GPT-4o, we reveal a Pareto principle of LLM cognition, where a shared reasoning core is complemented by ability-specific signatures. Furthermore, we discover that reasoning failures often manifest as anomalous intensity in latent activations. These findings opens a new paradigm in LLM analysis, providing a cognition grounded view of reasoning dynamics. Finally, leveraging these insights, we introduce a latent-informed candidate prioritization strategy, which improves reasoning performance by up to 7.5% across challenging benchmarks. Our code is available at https://github.com/milksalute/unicog.
A Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation
Oct 31, 2025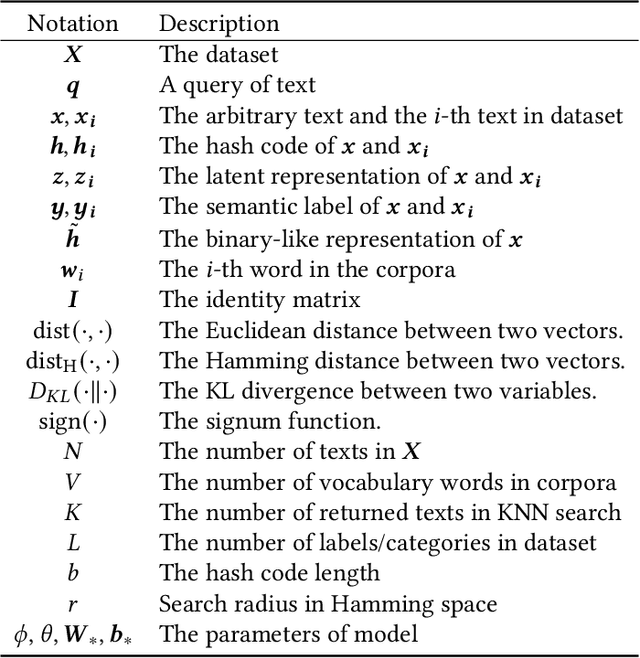
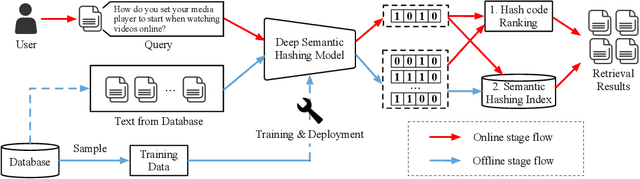
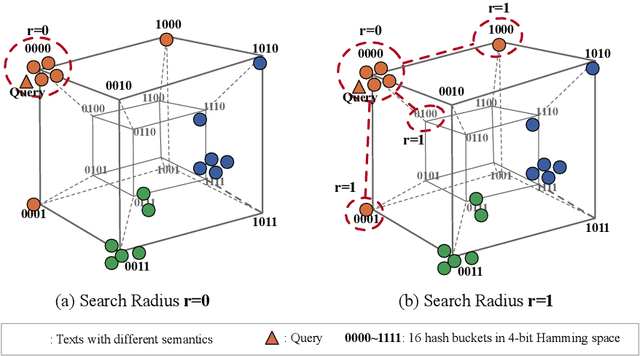
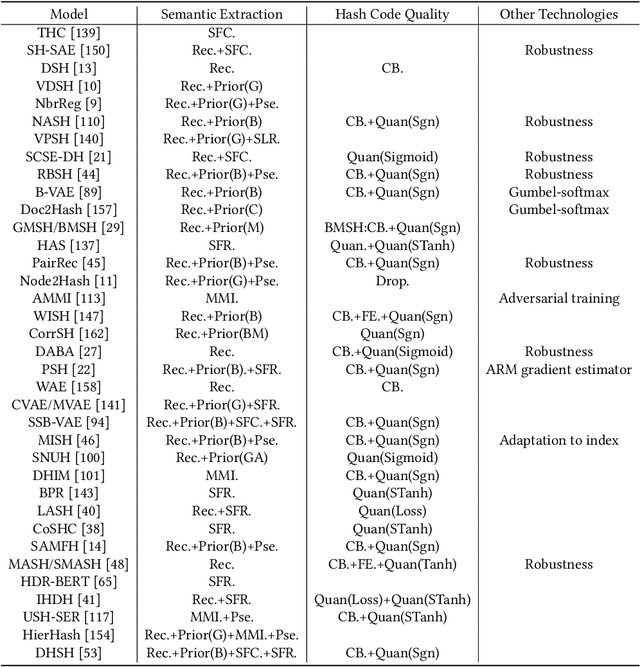
With the rapid growth of textual content on the Internet, efficient large-scale semantic text retrieval has garnered increasing attention from both academia and industry. Text hashing, which projects original texts into compact binary hash codes, is a crucial method for this task. By using binary codes, the semantic similarity computation for text pairs is significantly accelerated via fast Hamming distance calculations, and storage costs are greatly reduced. With the advancement of deep learning, deep text hashing has demonstrated significant advantages over traditional, data-independent hashing techniques. By leveraging deep neural networks, these methods can learn compact and semantically rich binary representations directly from data, overcoming the performance limitations of earlier approaches. This survey investigates current deep text hashing methods by categorizing them based on their core components: semantic extraction, hash code quality preservation, and other key technologies. We then present a detailed evaluation schema with results on several popular datasets, followed by a discussion of practical applications and open-source tools for implementation. Finally, we conclude by discussing key challenges and future research directions, including the integration of deep text hashing with large language models to further advance the field. The project for this survey can be accessed at https://github.com/hly1998/DeepTextHashing.
Pruning Long Chain-of-Thought of Large Reasoning Models via Small-Scale Preference Optimization
Aug 13, 2025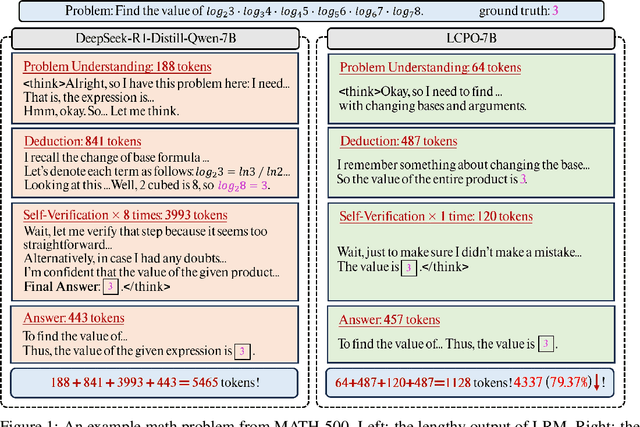
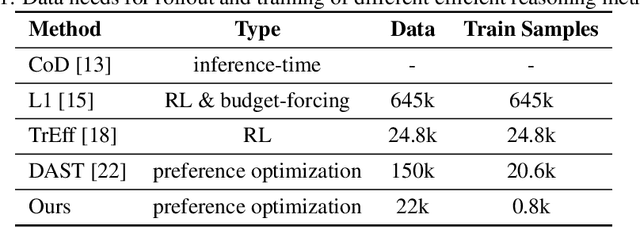
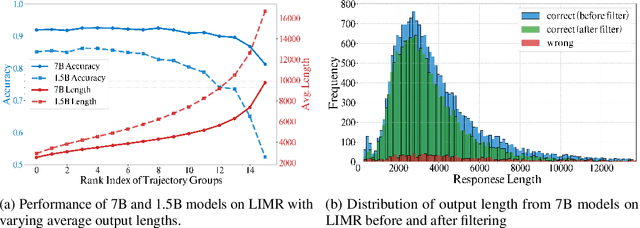
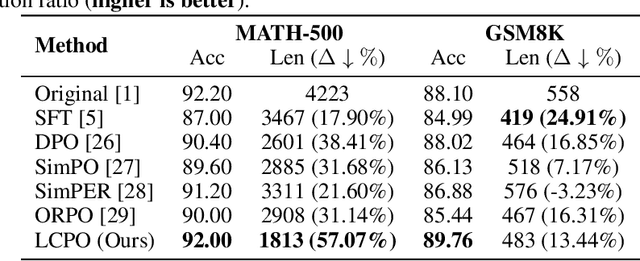
Recent advances in Large Reasoning Models (LRMs) have demonstrated strong performance on complex tasks through long Chain-of-Thought (CoT) reasoning. However, their lengthy outputs increase computational costs and may lead to overthinking, raising challenges in balancing reasoning effectiveness and efficiency. Current methods for efficient reasoning often compromise reasoning quality or require extensive resources. This paper investigates efficient methods to reduce the generation length of LRMs. We analyze generation path distributions and filter generated trajectories through difficulty estimation. Subsequently, we analyze the convergence behaviors of the objectives of various preference optimization methods under a Bradley-Terry loss based framework. Based on the analysis, we propose Length Controlled Preference Optimization (LCPO) that directly balances the implicit reward related to NLL loss. LCPO can effectively learn length preference with limited data and training. Extensive experiments demonstrate that our approach significantly reduces the average output length by over 50\% across multiple benchmarks while maintaining the reasoning performance. Our work highlights the potential for computationally efficient approaches in guiding LRMs toward efficient reasoning.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025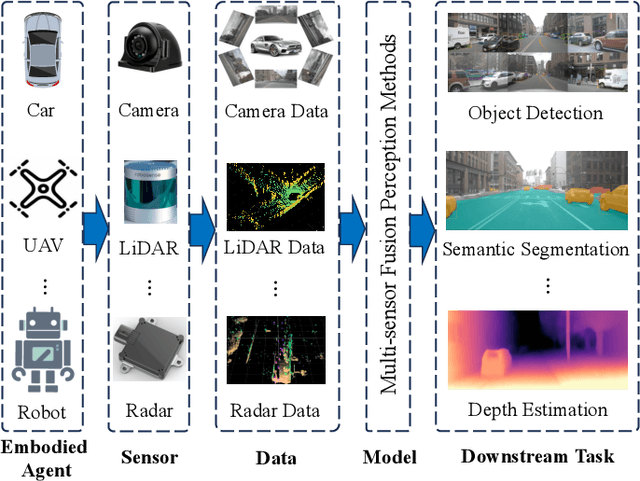
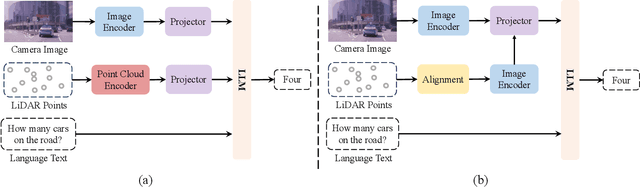
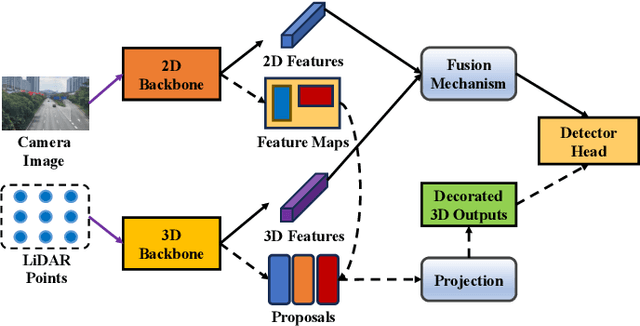
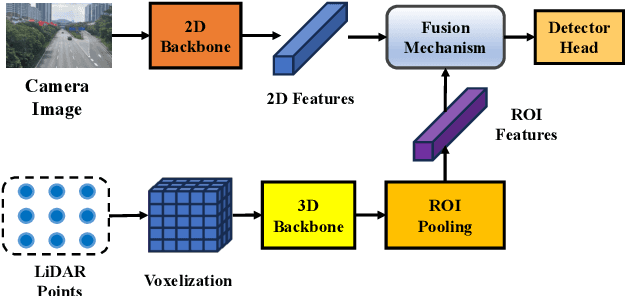
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
Advancing Multimodal Reasoning Capabilities of Multimodal Large Language Models via Visual Perception Reward
Jun 08, 2025Enhancing the multimodal reasoning capabilities of Multimodal Large Language Models (MLLMs) is a challenging task that has attracted increasing attention in the community. Recently, several studies have applied Reinforcement Learning with Verifiable Rewards (RLVR) to the multimodal domain in order to enhance the reasoning abilities of MLLMs. However, these works largely overlook the enhancement of multimodal perception capabilities in MLLMs, which serve as a core prerequisite and foundational component of complex multimodal reasoning. Through McNemar's test, we find that existing RLVR method fails to effectively enhance the multimodal perception capabilities of MLLMs, thereby limiting their further improvement in multimodal reasoning. To address this limitation, we propose Perception-R1, which introduces a novel visual perception reward that explicitly encourages MLLMs to perceive the visual content accurately, thereby can effectively incentivizing both their multimodal perception and reasoning capabilities. Specifically, we first collect textual visual annotations from the CoT trajectories of multimodal problems, which will serve as visual references for reward assignment. During RLVR training, we employ a judging LLM to assess the consistency between the visual annotations and the responses generated by MLLM, and assign the visual perception reward based on these consistency judgments. Extensive experiments on several multimodal reasoning benchmarks demonstrate the effectiveness of our Perception-R1, which achieves state-of-the-art performance on most benchmarks using only 1,442 training data.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.