 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Deep Text Hashing: Efficient Semantic Text Retrieval with Binary Representation
Oct 31, 2025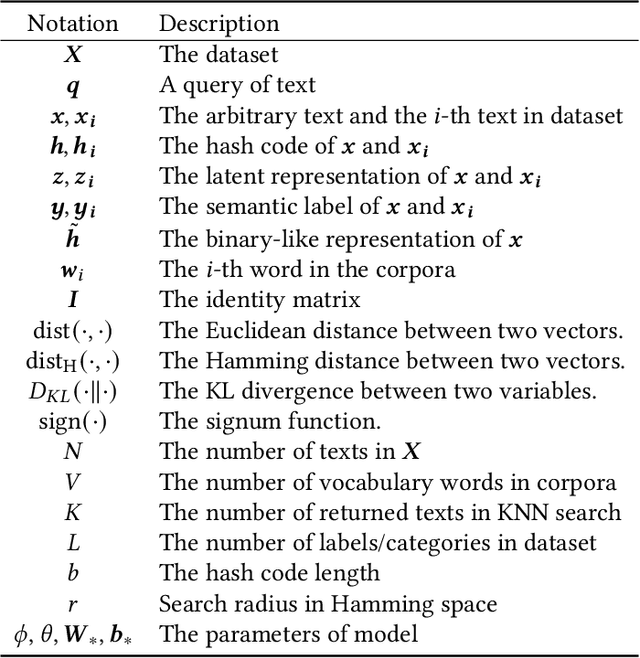
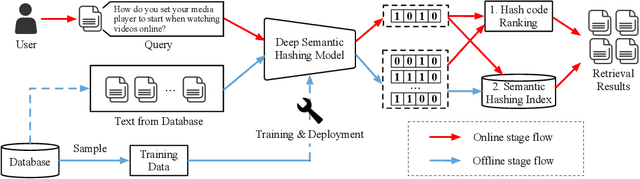
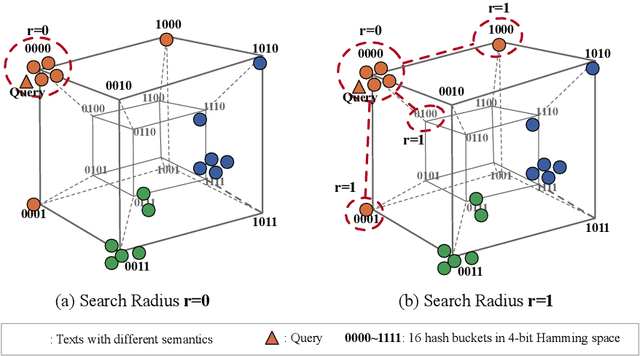
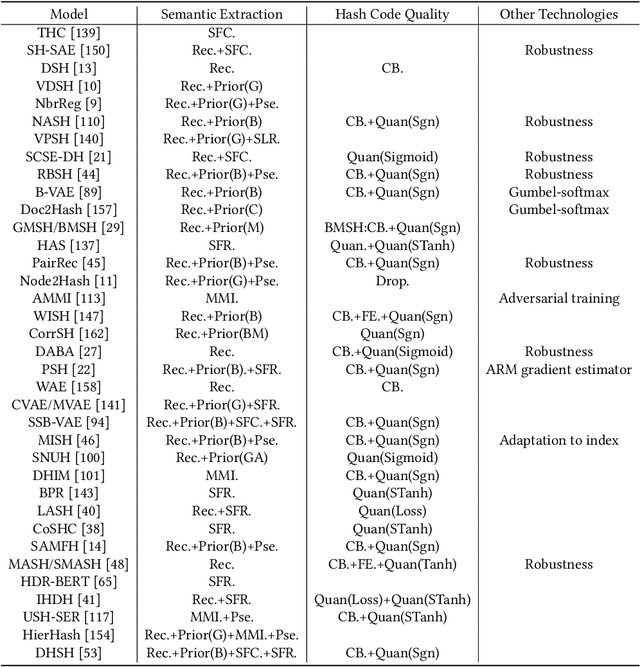
With the rapid growth of textual content on the Internet, efficient large-scale semantic text retrieval has garnered increasing attention from both academia and industry. Text hashing, which projects original texts into compact binary hash codes, is a crucial method for this task. By using binary codes, the semantic similarity computation for text pairs is significantly accelerated via fast Hamming distance calculations, and storage costs are greatly reduced. With the advancement of deep learning, deep text hashing has demonstrated significant advantages over traditional, data-independent hashing techniques. By leveraging deep neural networks, these methods can learn compact and semantically rich binary representations directly from data, overcoming the performance limitations of earlier approaches. This survey investigates current deep text hashing methods by categorizing them based on their core components: semantic extraction, hash code quality preservation, and other key technologies. We then present a detailed evaluation schema with results on several popular datasets, followed by a discussion of practical applications and open-source tools for implementation. Finally, we conclude by discussing key challenges and future research directions, including the integration of deep text hashing with large language models to further advance the field. The project for this survey can be accessed at https://github.com/hly1998/DeepTextHashing.
MGS3: A Multi-Granularity Self-Supervised Code Search Framework
May 30, 2025In the pursuit of enhancing software reusability and developer productivity, code search has emerged as a key area, aimed at retrieving code snippets relevant to functionalities based on natural language queries. Despite significant progress in self-supervised code pre-training utilizing the vast amount of code data in repositories, existing methods have primarily focused on leveraging contrastive learning to align natural language with function-level code snippets. These studies have overlooked the abundance of fine-grained (such as block-level and statement-level) code snippets prevalent within the function-level code snippets, which results in suboptimal performance across all levels of granularity. To address this problem, we first construct a multi-granularity code search dataset called MGCodeSearchNet, which contains 536K+ pairs of natural language and code snippets. Subsequently, we introduce a novel Multi-Granularity Self-Supervised contrastive learning code Search framework (MGS$^{3}$}). First, MGS$^{3}$ features a Hierarchical Multi-Granularity Representation module (HMGR), which leverages syntactic structural relationships for hierarchical representation and aggregates fine-grained information into coarser-grained representations. Then, during the contrastive learning phase, we endeavor to construct positive samples of the same granularity for fine-grained code, and introduce in-function negative samples for fine-grained code. Finally, we conduct extensive experiments on code search benchmarks across various granularities, demonstrating that the framework exhibits outstanding performance in code search tasks of multiple granularities. These experiments also showcase its model-agnostic nature and compatibility with existing pre-trained code representation models.
Refining Sentence Embedding Model through Ranking Sentences Generation with Large Language Models
Feb 19, 2025Sentence embedding is essential for many NLP tasks, with contrastive learning methods achieving strong performance using annotated datasets like NLI. Yet, the reliance on manual labels limits scalability. Recent studies leverage large language models (LLMs) to generate sentence pairs, reducing annotation dependency. However, they overlook ranking information crucial for fine-grained semantic distinctions. To tackle this challenge, we propose a method for controlling the generation direction of LLMs in the latent space. Unlike unconstrained generation, the controlled approach ensures meaningful semantic divergence. Then, we refine exist sentence embedding model by integrating ranking information and semantic information. Experiments on multiple benchmarks demonstrate that our method achieves new SOTA performance with a modest cost in ranking sentence synthesis.
A Flexible Plug-and-Play Module for Generating Variable-Length
Dec 12, 2024Deep supervised hashing has become a pivotal technique in large-scale image retrieval, offering significant benefits in terms of storage and search efficiency. However, existing deep supervised hashing models predominantly focus on generating fixed-length hash codes. This approach fails to address the inherent trade-off between efficiency and effectiveness when using hash codes of varying lengths. To determine the optimal hash code length for a specific task, multiple models must be trained for different lengths, leading to increased training time and computational overhead. Furthermore, the current paradigm overlooks the potential relationships between hash codes of different lengths, limiting the overall effectiveness of the models. To address these challenges, we propose the Nested Hash Layer (NHL), a plug-and-play module designed for existing deep supervised hashing models. The NHL framework introduces a novel mechanism to simultaneously generate hash codes of varying lengths in a nested manner. To tackle the optimization conflicts arising from the multiple learning objectives associated with different code lengths, we further propose an adaptive weights strategy that dynamically monitors and adjusts gradients during training. Additionally, recognizing that the structural information in longer hash codes can provide valuable guidance for shorter hash codes, we develop a long-short cascade self-distillation method within the NHL to enhance the overall quality of the generated hash codes. Extensive experiments demonstrate that NHL not only accelerates the training process but also achieves superior retrieval performance across various deep hashing models. Our code is publicly available at https://github.com/hly1998/NHL.
Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering
May 27, 2024
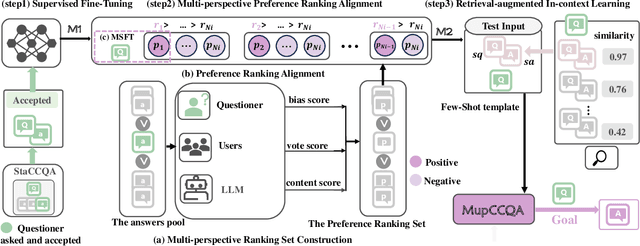
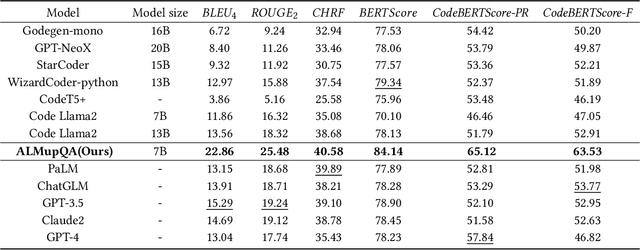
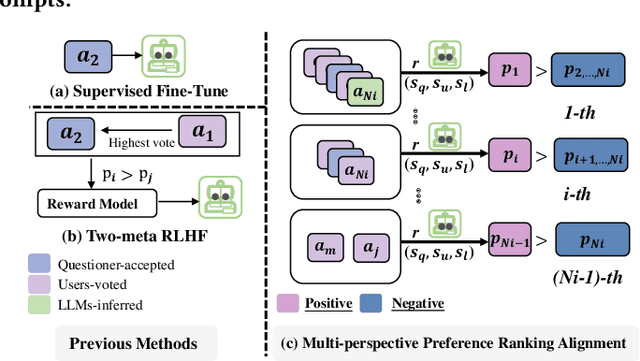
Code Community Question Answering (CCQA) seeks to tackle programming-related issues, thereby boosting productivity in both software engineering and academic research. Recent advancements in Reinforcement Learning from Human Feedback (RLHF) have transformed the fine-tuning process of Large Language Models (LLMs) to produce responses that closely mimic human behavior. Leveraging LLMs with RLHF for practical CCQA applications has thus emerged as a promising area of study. Unlike standard code question-answering tasks, CCQA involves multiple possible answers, with varying user preferences for each response. Additionally, code communities often show a preference for new APIs. These challenges prevent LLMs from generating responses that cater to the diverse preferences of users in CCQA tasks. To address these issues, we propose a novel framework called Aligning LLMs through Multi-perspective User Preference Ranking-based Feedback for Programming Question Answering (ALMupQA) to create user-focused responses. Our approach starts with Multi-perspective Preference Ranking Alignment (MPRA), which synthesizes varied user preferences based on the characteristics of answers from code communities. We then introduce a Retrieval-augmented In-context Learning (RIL) module to mitigate the problem of outdated answers by retrieving responses to similar questions from a question bank. Due to the limited availability of high-quality, multi-answer CCQA datasets, we also developed a dataset named StaCCQA from real code communities. Extensive experiments demonstrated the effectiveness of the ALMupQA framework in terms of accuracy and user preference. Compared to the base model, ALMupQA showed nearly an 11% improvement in BLEU, with increases of 20% and 17.5% in BERTScore and CodeBERTScore, respectively.
Bit-mask Robust Contrastive Knowledge Distillation for Unsupervised Semantic Hashing
Mar 10, 2024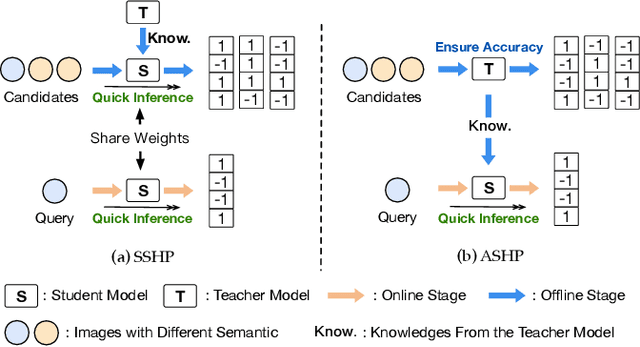
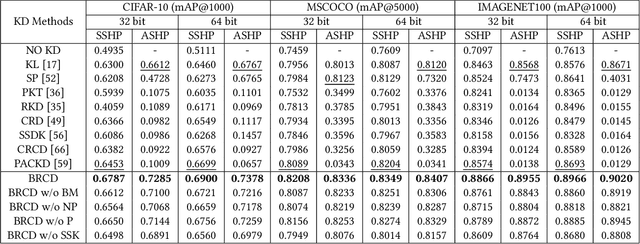
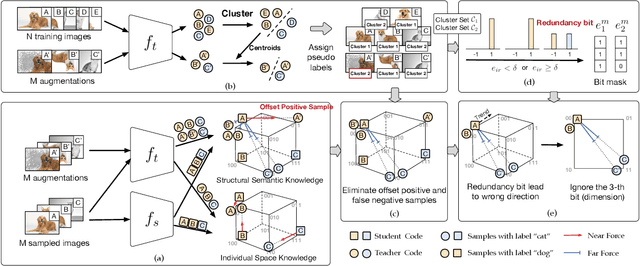
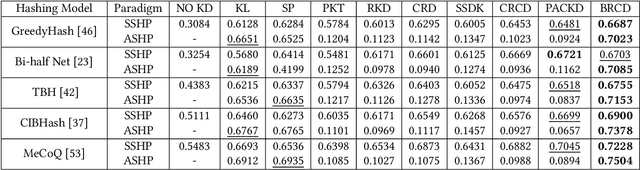
Unsupervised semantic hashing has emerged as an indispensable technique for fast image search, which aims to convert images into binary hash codes without relying on labels. Recent advancements in the field demonstrate that employing large-scale backbones (e.g., ViT) in unsupervised semantic hashing models can yield substantial improvements. However, the inference delay has become increasingly difficult to overlook. Knowledge distillation provides a means for practical model compression to alleviate this delay. Nevertheless, the prevailing knowledge distillation approaches are not explicitly designed for semantic hashing. They ignore the unique search paradigm of semantic hashing, the inherent necessities of the distillation process, and the property of hash codes. In this paper, we propose an innovative Bit-mask Robust Contrastive knowledge Distillation (BRCD) method, specifically devised for the distillation of semantic hashing models. To ensure the effectiveness of two kinds of search paradigms in the context of semantic hashing, BRCD first aligns the semantic spaces between the teacher and student models through a contrastive knowledge distillation objective. Additionally, to eliminate noisy augmentations and ensure robust optimization, a cluster-based method within the knowledge distillation process is introduced. Furthermore, through a bit-level analysis, we uncover the presence of redundancy bits resulting from the bit independence property. To mitigate these effects, we introduce a bit mask mechanism in our knowledge distillation objective. Finally, extensive experiments not only showcase the noteworthy performance of our BRCD method in comparison to other knowledge distillation methods but also substantiate the generality of our methods across diverse semantic hashing models and backbones. The code for BRCD is available at https://github.com/hly1998/BRCD.