 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGS3: A Multi-Granularity Self-Supervised Code Search Framework
May 30, 2025In the pursuit of enhancing software reusability and developer productivity, code search has emerged as a key area, aimed at retrieving code snippets relevant to functionalities based on natural language queries. Despite significant progress in self-supervised code pre-training utilizing the vast amount of code data in repositories, existing methods have primarily focused on leveraging contrastive learning to align natural language with function-level code snippets. These studies have overlooked the abundance of fine-grained (such as block-level and statement-level) code snippets prevalent within the function-level code snippets, which results in suboptimal performance across all levels of granularity. To address this problem, we first construct a multi-granularity code search dataset called MGCodeSearchNet, which contains 536K+ pairs of natural language and code snippets. Subsequently, we introduce a novel Multi-Granularity Self-Supervised contrastive learning code Search framework (MGS$^{3}$}). First, MGS$^{3}$ features a Hierarchical Multi-Granularity Representation module (HMGR), which leverages syntactic structural relationships for hierarchical representation and aggregates fine-grained information into coarser-grained representations. Then, during the contrastive learning phase, we endeavor to construct positive samples of the same granularity for fine-grained code, and introduce in-function negative samples for fine-grained code. Finally, we conduct extensive experiments on code search benchmarks across various granularities, demonstrating that the framework exhibits outstanding performance in code search tasks of multiple granularities. These experiments also showcase its model-agnostic nature and compatibility with existing pre-trained code representation models.
RePair: Automated Program Repair with Process-based Feedback
Aug 21, 2024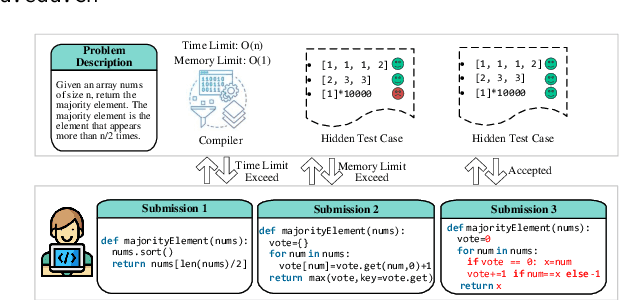

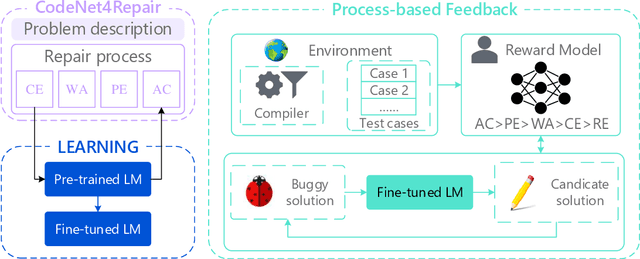

The gap between the trepidation of program reliability and the expense of repairs underscores the indispensability of Automated Program Repair (APR). APR is instrumental in transforming vulnerable programs into more robust ones, bolstering program reliability while simultaneously diminishing the financial burden of manual repairs. Commercial-scale language models (LM) have taken APR to unprecedented levels. However, the emergence reveals that for models fewer than 100B parameters, making single-step modifications may be difficult to achieve the desired effect. Moreover, humans interact with the LM through explicit prompts, which hinders the LM from receiving feedback from compiler and test cases to automatically optimize its repair policies. In this literature, we explore how small-scale LM (less than 20B) achieve excellent performance through process supervision and feedback. We start by constructing a dataset named CodeNet4Repair, replete with multiple repair records, which supervises the fine-tuning of a foundational model. Building upon the encouraging outcomes of reinforcement learning, we develop a reward model that serves as a critic, providing feedback for the fine-tuned LM's action, progressively optimizing its policy. During inference, we require the LM to generate solutions iteratively until the repair effect no longer improves or hits the maximum step limit. The results show that process-based not only outperforms larger outcome-based generation methods, but also nearly matches the performance of closed-source commercial large-scale LMs.
* 15 pages, 13 figures
Quiz-based Knowledge Tracing
Apr 06, 2023Knowledge tracing (KT) aims to assess individuals' evolving knowledge states according to their learning interactions with different exercises in online learning systems (OIS), which is critical in supporting decision-making for subsequent intelligent services, such as personalized learning source recommendation. Existing researchers have broadly studied KT and developed many effective methods. However, most of them assume that students' historical interactions are uniformly distributed in a continuous sequence, ignoring the fact that actual interaction sequences are organized based on a series of quizzes with clear boundaries, where interactions within a quiz are consecutively completed, but interactions across different quizzes are discrete and may be spaced over days. In this paper, we present the Quiz-based Knowledge Tracing (QKT) model to monitor students' knowledge states according to their quiz-based learning interactions. Specifically, as students' interactions within a quiz are continuous and have the same or similar knowledge concepts, we design the adjacent gate followed by a global average pooling layer to capture the intra-quiz short-term knowledge influence. Then, as various quizzes tend to focus on different knowledge concepts, we respectively measure the inter-quiz knowledge substitution by the gated recurrent unit and the inter-quiz knowledge complementarity by the self-attentive encoder with a novel recency-aware attention mechanism. Finally, we integrate the inter-quiz long-term knowledge substitution and complementarity across different quizzes to output students' evolving knowledge states. Extensive experimental results on three public real-world datasets demonstrate that QKT achieves state-of-the-art performance compared to existing methods. Further analyses confirm that QKT is promising in designing more effective quizzes.