 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Flow as Time Series: Discovering Temporal Consistency and Variability for VideoQA
Apr 08, 2025Video Question Answering (VideoQA) is a complex video-language task that demands a sophisticated understanding of both visual content and temporal dynamics. Traditional Transformer-style architectures, while effective in integrating multimodal data, often simplify temporal dynamics through positional encoding and fail to capture non-linear interactions within video sequences. In this paper, we introduce the Temporal Trio Transformer (T3T), a novel architecture that models time consistency and time variability. The T3T integrates three key components: Temporal Smoothing (TS), Temporal Difference (TD), and Temporal Fusion (TF). The TS module employs Brownian Bridge for capturing smooth, continuous temporal transitions, while the TD module identifies and encodes significant temporal variations and abrupt changes within the video content. Subsequently, the TF module synthesizes these temporal features with textual cues, facilitating a deeper contextual understanding and response accuracy. The efficacy of the T3T is demonstrated through extensive testing on multiple VideoQA benchmark datasets. Our results underscore the importance of a nuanced approach to temporal modeling in improving the accuracy and depth of video-based question answering.
Unveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
Feb 17, 2025The reasoning abilities are one of the most enigmatic and captivating aspects of large language models (LLMs). Numerous studies are dedicated to exploring and expanding the boundaries of this reasoning capability. However, tasks that embody both reasoning and recall characteristics are often overlooked. In this paper, we introduce such a novel task, code reasoning, to provide a new perspective for the reasoning abilities of LLMs. We summarize three meta-benchmarks based on established forms of logical reasoning, and instantiate these into eight specific benchmark tasks. Our testing on these benchmarks reveals that LLMs continue to struggle with identifying satisfactory reasoning pathways. Additionally, we present a new pathway exploration pipeline inspired by human intricate problem-solving methods. This Reflective Hypothesis Decomposition and Amendment (RHDA) pipeline consists of the following iterative steps: (1) Proposing potential hypotheses based on observations and decomposing them; (2) Utilizing tools to validate hypotheses and reflection outcomes; (3) Revising hypothesis in light of observations. Our approach effectively mitigates logical chain collapses arising from forgetting or hallucination issues in multi-step reasoning, resulting in performance gains of up to $3\times$. Finally, we expanded this pipeline by applying it to simulate complex household tasks in real-world scenarios, specifically in VirtualHome, enhancing the handling of failure cases. We release our code and all of results at https://github.com/TnTWoW/code_reasoning.
IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity
Sep 07, 2024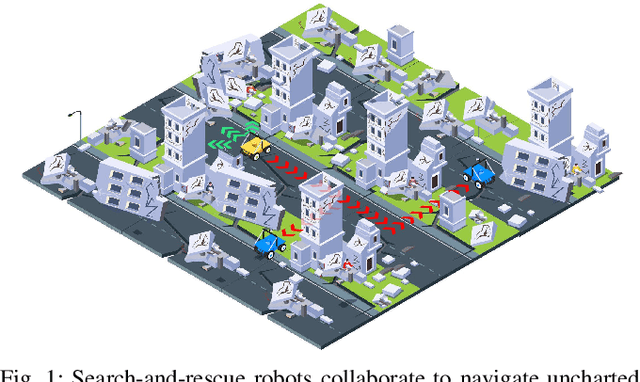

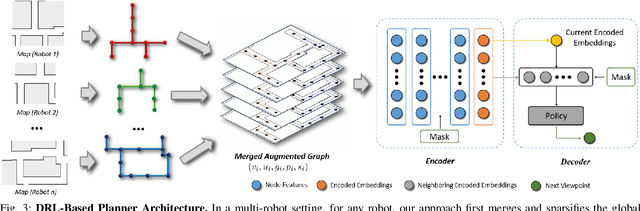
Information sharing is critical in time-sensitive and realistic multi-robot exploration, especially for smaller robotic teams in large-scale environments where connectivity may be sparse and intermittent. Existing methods often overlook such communication constraints by assuming unrealistic global connectivity. Other works account for communication constraints (by maintaining close proximity or line of sight during information exchange), but are often inefficient. For instance, preplanned rendezvous approaches typically involve unnecessary detours resulting from poorly timed rendezvous, while pursuit-based approaches often result in short-sighted decisions due to their greedy nature. We present IR2, a deep reinforcement learning approach to information sharing for multi-robot exploration. Leveraging attention-based neural networks trained via reinforcement and curriculum learning, IR2 allows robots to effectively reason about the longer-term trade-offs between disconnecting for solo exploration and reconnecting for information sharing. In addition, we propose a hierarchical graph formulation to maintain a sparse yet informative graph, enabling our approach to scale to large-scale environments. We present simulation results in three large-scale Gazebo environments, which show that our approach yields 6.6-34.1% shorter exploration paths and significantly improved mapped area consistency among robots when compared to state-of-the-art baselines. Our simulation training and testing code is available at https://github.com/marmotlab/IR2.
RePair: Automated Program Repair with Process-based Feedback
Aug 21, 2024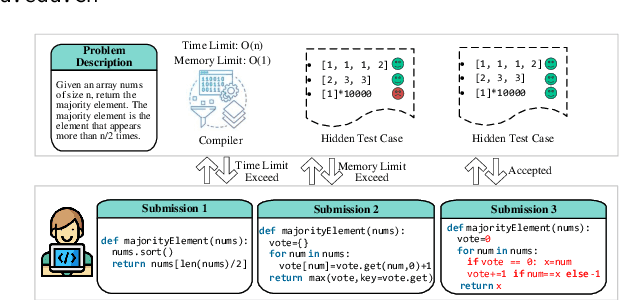

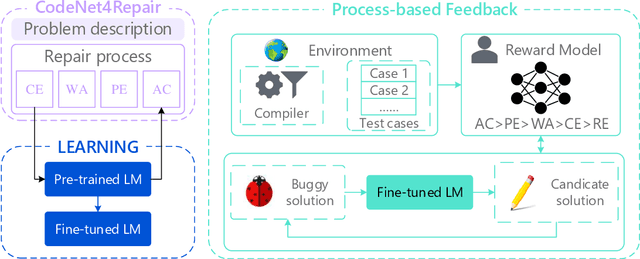

The gap between the trepidation of program reliability and the expense of repairs underscores the indispensability of Automated Program Repair (APR). APR is instrumental in transforming vulnerable programs into more robust ones, bolstering program reliability while simultaneously diminishing the financial burden of manual repairs. Commercial-scale language models (LM) have taken APR to unprecedented levels. However, the emergence reveals that for models fewer than 100B parameters, making single-step modifications may be difficult to achieve the desired effect. Moreover, humans interact with the LM through explicit prompts, which hinders the LM from receiving feedback from compiler and test cases to automatically optimize its repair policies. In this literature, we explore how small-scale LM (less than 20B) achieve excellent performance through process supervision and feedback. We start by constructing a dataset named CodeNet4Repair, replete with multiple repair records, which supervises the fine-tuning of a foundational model. Building upon the encouraging outcomes of reinforcement learning, we develop a reward model that serves as a critic, providing feedback for the fine-tuned LM's action, progressively optimizing its policy. During inference, we require the LM to generate solutions iteratively until the repair effect no longer improves or hits the maximum step limit. The results show that process-based not only outperforms larger outcome-based generation methods, but also nearly matches the performance of closed-source commercial large-scale LMs.
* 15 pages, 13 figures
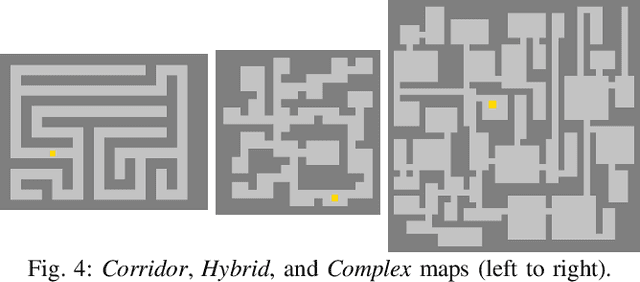
HDPlanner: Advancing Autonomous Deployments in Unknown Environments through Hierarchical Decision Networks
Aug 07, 2024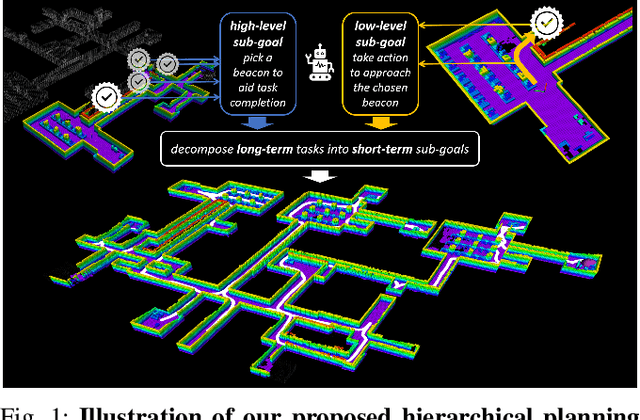
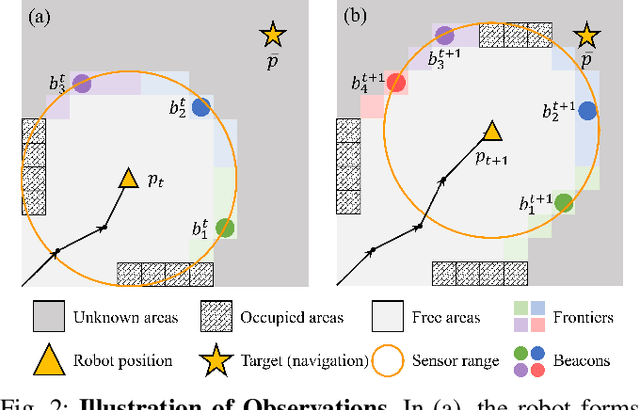
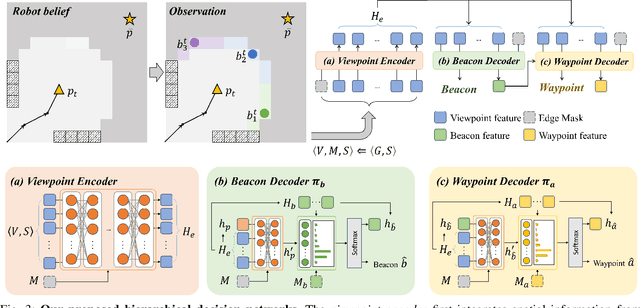
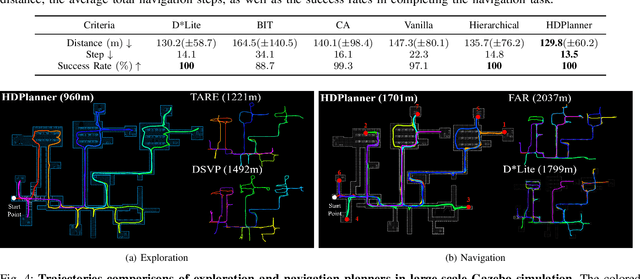
In this paper, we introduce HDPlanner, a deep reinforcement learning (DRL) based framework designed to tackle two core and challenging tasks for mobile robots: autonomous exploration and navigation, where the robot must optimize its trajectory adaptively to achieve the task objective through continuous interactions in unknown environments. Specifically, HDPlanner relies on novel hierarchical attention networks to empower the robot to reason about its belief across multiple spatial scales and sequence collaborative decisions, where our networks decompose long-term objectives into short-term informative task assignments and informative path plannings. We further propose a contrastive learning-based joint optimization to enhance the robustness of HDPlanner. We empirically demonstrate that HDPlanner significantly outperforms state-of-the-art conventional and learning-based baselines on an extensive set of simulations, including hundreds of test maps and large-scale, complex Gazebo environments. Notably, HDPlanner achieves real-time planning with travel distances reduced by up to 35.7% compared to exploration benchmarks and by up to 16.5% than navigation benchmarks. Furthermore, we validate our approach on hardware, where it generates high-quality, adaptive trajectories in both indoor and outdoor environments, highlighting its real-world applicability without additional training.
Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration
Jul 29, 2024



Communication bandwidth is an important consideration in multi-robot exploration, where information exchange among robots is critical. While existing methods typically aim to reduce communication throughput, they either require significant computation or significantly compromise exploration efficiency. In this work, we propose a deep reinforcement learning framework based on communication and privileged reinforcement learning to achieve a significant reduction in bandwidth consumption, while minimally sacrificing exploration efficiency. Specifically, our approach allows robots to learn to embed the most salient information from their individual belief (partial map) over the environment into fixed-sized messages. Robots then reason about their own belief as well as received messages to distributedly explore the environment while avoiding redundant work. In doing so, we employ privileged learning and learned attention mechanisms to endow the critic (i.e., teacher) network with ground truth map knowledge to effectively guide the policy (i.e., student) network during training. Compared to relevant baselines, our model allows the team to reduce communication by up to two orders of magnitude, while only sacrificing a marginal 2.4\% in total travel distance, paving the way for efficient, distributed multi-robot exploration in bandwidth-limited scenarios.
Caseformer: Pre-training for Legal Case Retrieval
Nov 01, 2023Legal case retrieval aims to help legal workers find relevant cases related to their cases at hand, which is important for the guarantee of fairness and justice in legal judgments. While recent advances in neural retrieval methods have significantly improved the performance of open-domain retrieval tasks (e.g., Web search), their advantages have not been observed in legal case retrieval due to their thirst for annotated data. As annotating large-scale training data in legal domains is prohibitive due to the need for domain expertise, traditional search techniques based on lexical matching such as TF-IDF, BM25, and Query Likelihood are still prevalent in legal case retrieval systems. While previous studies have designed several pre-training methods for IR models in open-domain tasks, these methods are usually suboptimal in legal case retrieval because they cannot understand and capture the key knowledge and data structures in the legal corpus. To this end, we propose a novel pre-training framework named Caseformer that enables the pre-trained models to learn legal knowledge and domain-specific relevance information in legal case retrieval without any human-labeled data. Through three unsupervised learning tasks, Caseformer is able to capture the special language, document structure, and relevance patterns of legal case documents, making it a strong backbone for downstream legal case retrieval tasks. Experimental results show that our model has achieved state-of-the-art performance in both zero-shot and full-data fine-tuning settings. Also, experiments on both Chinese and English legal datasets demonstrate that the effectiveness of Caseformer is language-independent in legal case retrieval.
LeCaRDv2: A Large-Scale Chinese Legal Case Retrieval Dataset
Oct 26, 2023As an important component of intelligent legal systems, legal case retrieval plays a critical role in ensuring judicial justice and fairness. However, the development of legal case retrieval technologies in the Chinese legal system is restricted by three problems in existing datasets: limited data size, narrow definitions of legal relevance, and naive candidate pooling strategies used in data sampling. To alleviate these issues, we introduce LeCaRDv2, a large-scale Legal Case Retrieval Dataset (version 2). It consists of 800 queries and 55,192 candidates extracted from 4.3 million criminal case documents. To the best of our knowledge, LeCaRDv2 is one of the largest Chinese legal case retrieval datasets, providing extensive coverage of criminal charges. Additionally, we enrich the existing relevance criteria by considering three key aspects: characterization, penalty, procedure. This comprehensive criteria enriches the dataset and may provides a more holistic perspective. Furthermore, we propose a two-level candidate set pooling strategy that effectively identify potential candidates for each query case. It's important to note that all cases in the dataset have been annotated by multiple legal experts specializing in criminal law. Their expertise ensures the accuracy and reliability of the annotations. We evaluate several state-of-the-art retrieval models at LeCaRDv2, demonstrating that there is still significant room for improvement in legal case retrieval. The details of LeCaRDv2 can be found at the anonymous website https://github.com/anonymous1113243/LeCaRDv2.
An Intent Taxonomy of Legal Case Retrieval
Jul 25, 2023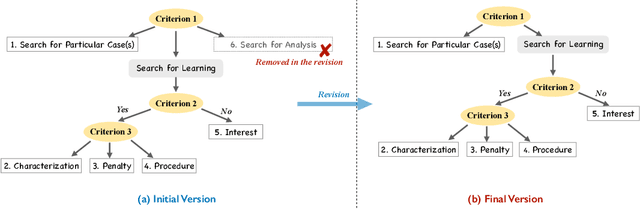
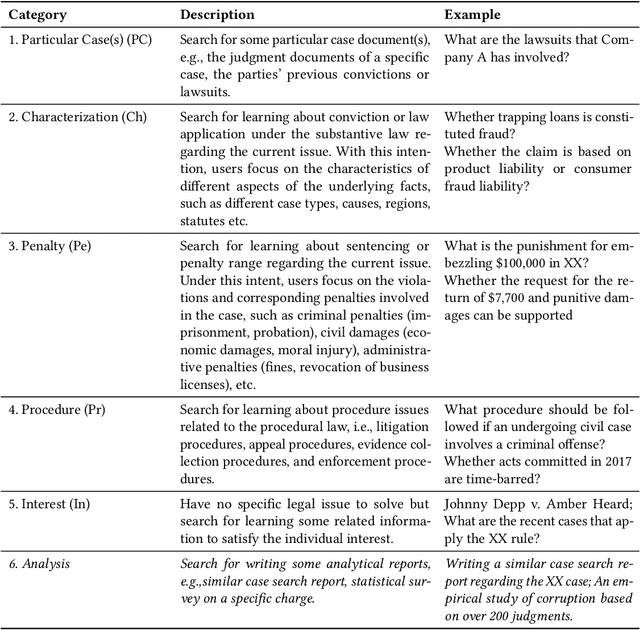


Legal case retrieval is a special Information Retrieval~(IR) task focusing on legal case documents. Depending on the downstream tasks of the retrieved case documents, users' information needs in legal case retrieval could be significantly different from those in Web search and traditional ad-hoc retrieval tasks. While there are several studies that retrieve legal cases based on text similarity, the underlying search intents of legal retrieval users, as shown in this paper, are more complicated than that yet mostly unexplored. To this end, we present a novel hierarchical intent taxonomy of legal case retrieval. It consists of five intent types categorized by three criteria, i.e., search for Particular Case(s), Characterization, Penalty, Procedure, and Interest. The taxonomy was constructed transparently and evaluated extensively through interviews, editorial user studies, and query log analysis. Through a laboratory user study, we reveal significant differences in user behavior and satisfaction under different search intents in legal case retrieval. Furthermore, we apply the proposed taxonomy to various downstream legal retrieval tasks, e.g., result ranking and satisfaction prediction, and demonstrate its effectiveness. Our work provides important insights into the understanding of user intents in legal case retrieval and potentially leads to better retrieval techniques in the legal domain, such as intent-aware ranking strategies and evaluation methodologies.
CaseEncoder: A Knowledge-enhanced Pre-trained Model for Legal Case Encoding
May 09, 2023Legal case retrieval is a critical process for modern legal information systems. While recent studies have utilized pre-trained language models (PLMs) based on the general domain self-supervised pre-training paradigm to build models for legal case retrieval, there are limitations in using general domain PLMs as backbones. Specifically, these models may not fully capture the underlying legal features in legal case documents. To address this issue, we propose CaseEncoder, a legal document encoder that leverages fine-grained legal knowledge in both the data sampling and pre-training phases. In the data sampling phase, we enhance the quality of the training data by utilizing fine-grained law article information to guide the selection of positive and negative examples. In the pre-training phase, we design legal-specific pre-training tasks that align with the judging criteria of relevant legal cases. Based on these tasks, we introduce an innovative loss function called Biased Circle Loss to enhance the model's ability to recognize case relevance in fine grains. Experimental results on multiple benchmarks demonstrate that CaseEncoder significantly outperforms both existing general pre-training models and legal-specific pre-training models in zero-shot legal case retrieval.