 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOIN: Collaborative Interaction-Aware Multi-Agent Reinforcement Learning for Self-Driving Systems
Mar 26, 2026Multi-Agent Self-Driving (MASD) systems provide an effective solution for coordinating autonomous vehicles to reduce congestion and enhance both safety and operational efficiency in future intelligent transportation systems. Multi-Agent Reinforcement Learning (MARL) has emerged as a promising approach for developing advanced end-to-end MASD systems. However, achieving efficient and safe collaboration in dynamic MASD systems remains a significant challenge in dense scenarios with complex agent interactions. To address this challenge, we propose a novel collaborative(CO-) interaction-aware(-IN) MARL framework, named COIN. Specifically, we develop a new counterfactual individual-global twin delayed deep deterministic policy gradient (CIG-TD3) algorithm, crafted in a "centralized training, decentralized execution" (CTDE) manner, which aims to jointly optimize the individual objectives (navigation) and the global objectives (collaboration) of agents. We further introduce a dual-level interaction-aware centralized critic architecture that captures both local pairwise interactions and global system-level dependencies, enabling more accurate global value estimation and improved credit assignment for collaborative policy learning. We conduct extensive simulation experiments in dense urban traffic environments, which demonstrate that COIN consistently outperforms other advanced baseline methods in both safety and efficiency across various system sizes. These results highlight its superiority in complex and dynamic MASD scenarios, as further validated through real-world robot demonstrations. Supplementary videos are available at https://marmotlab.github.io/COIN/
ImagiNav: Scalable Embodied Navigation via Generative Visual Prediction and Inverse Dynamics
Mar 14, 2026Enabling robots to navigate open-world environments via natural language is critical for general-purpose autonomy. Yet, Vision-Language Navigation has relied on end-to-end policies trained on expensive, embodiment-specific robot data. While recent foundation models trained on vast simulation data show promise, the challenge of scaling and generalizing due to the limited scene diversity and visual fidelity in simulation persists. To address this gap, we propose ImagiNav, a novel modular paradigm that decouples visual planning from robot actuation, enabling the direct utilization of diverse in-the-wild navigation videos. Our framework operates as a hierarchy: a Vision-Language Model first decomposes instructions into textual subgoals; a finetuned generative video model then imagines the future video trajectory towards that subgoal; finally, an inverse dynamics model extracts the trajectory from the imagined video, which can then be tracked via a low-level controller. We additionally develop a scalable data pipeline of in-the-wild navigation videos auto-labeled via inverse dynamics and a pretrained Vision-Language Model. ImagiNav demonstrates strong zero-shot transfer to robot navigation without requiring robot demonstrations, paving the way for generalist robots that learn navigation directly from unlabeled, open-world data.
GPO: Growing Policy Optimization for Legged Robot Locomotion and Whole-Body Control
Jan 28, 2026Training reinforcement learning (RL) policies for legged robots remains challenging due to high-dimensional continuous actions, hardware constraints, and limited exploration. Existing methods for locomotion and whole-body control work well for position-based control with environment-specific heuristics (e.g., reward shaping, curriculum design, and manual initialization), but are less effective for torque-based control, where sufficiently exploring the action space and obtaining informative gradient signals for training is significantly more difficult. We introduce Growing Policy Optimization (GPO), a training framework that applies a time-varying action transformation to restrict the effective action space in the early stage, thereby encouraging more effective data collection and policy learning, and then progressively expands it to enhance exploration and achieve higher expected return. We prove that this transformation preserves the PPO update rule and introduces only bounded, vanishing gradient distortion, thereby ensuring stable training. We evaluate GPO on both quadruped and hexapod robots, including zero-shot deployment of simulation-trained policies on hardware. Policies trained with GPO consistently achieve better performance. These results suggest that GPO provides a general, environment-agnostic optimization framework for learning legged locomotion.
FARE: Fast-Slow Agentic Robotic Exploration
Jan 21, 2026This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a large language model (LLM) for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.
GRATE: a Graph transformer-based deep Reinforcement learning Approach for Time-efficient autonomous robot Exploration
Sep 16, 2025Autonomous robot exploration (ARE) is the process of a robot autonomously navigating and mapping an unknown environment. Recent Reinforcement Learning (RL)-based approaches typically formulate ARE as a sequential decision-making problem defined on a collision-free informative graph. However, these methods often demonstrate limited reasoning ability over graph-structured data. Moreover, due to the insufficient consideration of robot motion, the resulting RL policies are generally optimized to minimize travel distance, while neglecting time efficiency. To overcome these limitations, we propose GRATE, a Deep Reinforcement Learning (DRL)-based approach that leverages a Graph Transformer to effectively capture both local structure patterns and global contextual dependencies of the informative graph, thereby enhancing the model's reasoning capability across the entire environment. In addition, we deploy a Kalman filter to smooth the waypoint outputs, ensuring that the resulting path is kinodynamically feasible for the robot to follow. Experimental results demonstrate that our method exhibits better exploration efficiency (up to 21.5% in distance and 21.3% in time to complete exploration) than state-of-the-art conventional and learning-based baselines in various simulation benchmarks. We also validate our planner in real-world scenarios.
Neural Algorithmic Reasoners informed Large Language Model for Multi-Agent Path Finding
Aug 25, 2025The development and application of large language models (LLM) have demonstrated that foundational models can be utilized to solve a wide array of tasks. However, their performance in multi-agent path finding (MAPF) tasks has been less than satisfactory, with only a few studies exploring this area. MAPF is a complex problem requiring both planning and multi-agent coordination. To improve the performance of LLM in MAPF tasks, we propose a novel framework, LLM-NAR, which leverages neural algorithmic reasoners (NAR) to inform LLM for MAPF. LLM-NAR consists of three key components: an LLM for MAPF, a pre-trained graph neural network-based NAR, and a cross-attention mechanism. This is the first work to propose using a neural algorithmic reasoner to integrate GNNs with the map information for MAPF, thereby guiding LLM to achieve superior performance. LLM-NAR can be easily adapted to various LLM models. Both simulation and real-world experiments demonstrate that our method significantly outperforms existing LLM-based approaches in solving MAPF problems.
Attention-based Learning for 3D Informative Path Planning
Jun 10, 2025In this work, we propose an attention-based deep reinforcement learning approach to address the adaptive informative path planning (IPP) problem in 3D space, where an aerial robot equipped with a downward-facing sensor must dynamically adjust its 3D position to balance sensing footprint and accuracy, and finally obtain a high-quality belief of an underlying field of interest over a given domain (e.g., presence of specific plants, hazardous gas, geological structures, etc.). In adaptive IPP tasks, the agent is tasked with maximizing information collected under time/distance constraints, continuously adapting its path based on newly acquired sensor data. To this end, we leverage attention mechanisms for their strong ability to capture global spatial dependencies across large action spaces, allowing the agent to learn an implicit estimation of environmental transitions. Our model builds a contextual belief representation over the entire domain, guiding sequential movement decisions that optimize both short- and long-term search objectives. Comparative evaluations against state-of-the-art planners demonstrate that our approach significantly reduces environmental uncertainty within constrained budgets, thus allowing the agent to effectively balance exploration and exploitation. We further show our model generalizes well to environments of varying sizes, highlighting its potential for many real-world applications.
Search-TTA: A Multimodal Test-Time Adaptation Framework for Visual Search in the Wild
May 16, 2025
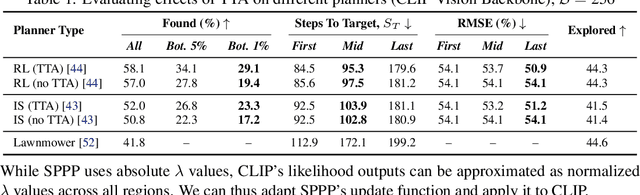

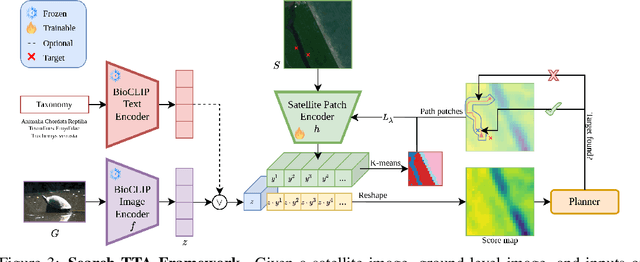
To perform autonomous visual search for environmental monitoring, a robot may leverage satellite imagery as a prior map. This can help inform coarse, high-level search and exploration strategies, even when such images lack sufficient resolution to allow fine-grained, explicit visual recognition of targets. However, there are some challenges to overcome with using satellite images to direct visual search. For one, targets that are unseen in satellite images are underrepresented (compared to ground images) in most existing datasets, and thus vision models trained on these datasets fail to reason effectively based on indirect visual cues. Furthermore, approaches which leverage large Vision Language Models (VLMs) for generalization may yield inaccurate outputs due to hallucination, leading to inefficient search. To address these challenges, we introduce Search-TTA, a multimodal test-time adaptation framework that can accept text and/or image input. First, we pretrain a remote sensing image encoder to align with CLIP's visual encoder to output probability distributions of target presence used for visual search. Second, our framework dynamically refines CLIP's predictions during search using a test-time adaptation mechanism. Through a feedback loop inspired by Spatial Poisson Point Processes, gradient updates (weighted by uncertainty) are used to correct (potentially inaccurate) predictions and improve search performance. To validate Search-TTA's performance, we curate a visual search dataset based on internet-scale ecological data. We find that Search-TTA improves planner performance by up to 9.7%, particularly in cases with poor initial CLIP predictions. It also achieves comparable performance to state-of-the-art VLMs. Finally, we deploy Search-TTA on a real UAV via hardware-in-the-loop testing, by simulating its operation within a large-scale simulation that provides onboard sensing.
APEX: Action Priors Enable Efficient Exploration for Skill Imitation on Articulated Robots
May 15, 2025Learning by imitation provides an effective way for robots to develop well-regulated complex behaviors and directly benefit from natural demonstrations. State-of-the-art imitation learning (IL) approaches typically leverage Adversarial Motion Priors (AMP), which, despite their impressive results, suffer from two key limitations. They are prone to mode collapse, which often leads to overfitting to the simulation environment and thus increased sim-to-real gap, and they struggle to learn diverse behaviors effectively. To overcome these limitations, we introduce APEX (Action Priors enable Efficient eXploration): a simple yet versatile imitation learning framework that integrates demonstrations directly into reinforcement learning (RL), maintaining high exploration while grounding behavior with expert-informed priors. We achieve this through a combination of decaying action priors, which initially bias exploration toward expert demonstrations but gradually allow the policy to explore independently. This is complemented by a multi-critic RL framework that effectively balances stylistic consistency with task performance. Our approach achieves sample-efficient imitation learning and enables the acquisition of diverse skills within a single policy. APEX generalizes to varying velocities and preserves reference-like styles across complex tasks such as navigating rough terrain and climbing stairs, utilizing only flat-terrain kinematic motion data as a prior. We validate our framework through extensive hardware experiments on the Unitree Go2 quadruped. There, APEX yields diverse and agile locomotion gaits, inherent gait transitions, and the highest reported speed for the platform to the best of our knowledge (peak velocity of ~3.3 m/s on hardware). Our results establish APEX as a compelling alternative to existing IL methods, offering better efficiency, adaptability, and real-world performance.
HELM: Human-Preferred Exploration with Language Models
Mar 10, 2025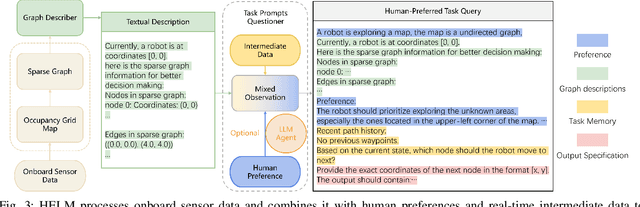
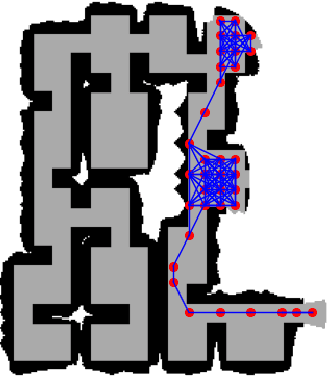
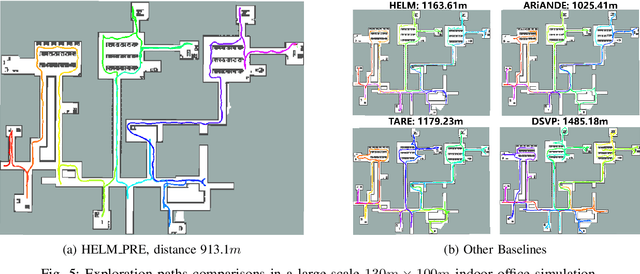
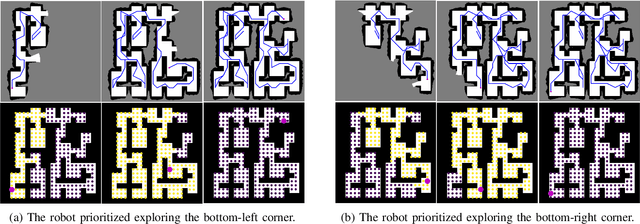
In autonomous exploration tasks, robots are required to explore and map unknown environments while efficiently planning in dynamic and uncertain conditions. Given the significant variability of environments, human operators often have specific preference requirements for exploration, such as prioritizing certain areas or optimizing for different aspects of efficiency. However, existing methods struggle to accommodate these human preferences adaptively, often requiring extensive parameter tuning or network retraining. With the recent advancements in Large Language Models (LLMs), which have been widely applied to text-based planning and complex reasoning, their potential for enhancing autonomous exploration is becoming increasingly promising. Motivated by this, we propose an LLM-based human-preferred exploration framework that seamlessly integrates a mobile robot system with LLMs. By leveraging the reasoning and adaptability of LLMs, our approach enables intuitive and flexible preference control through natural language while maintaining a task success rate comparable to state-of-the-art traditional methods. Experimental results demonstrate that our framework effectively bridges the gap between human intent and policy preference in autonomous exploration, offering a more user-friendly and adaptable solution for real-world robotic applications.