 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFARE: Fast-Slow Agentic Robotic Exploration
Jan 21, 2026This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a large language model (LLM) for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.
Embedded Mean Field Reinforcement Learning for Perimeter-defense Game
May 20, 2025


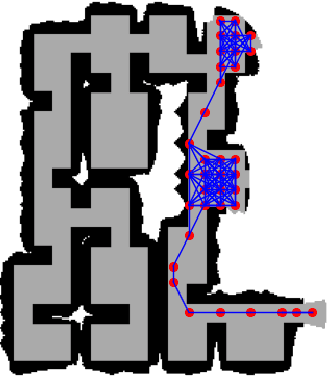
With the rapid advancement of unmanned aerial vehicles (UAVs) and missile technologies, perimeter-defense game between attackers and defenders for the protection of critical regions have become increasingly complex and strategically significant across a wide range of domains. However, existing studies predominantly focus on small-scale, simplified two-dimensional scenarios, often overlooking realistic environmental perturbations, motion dynamics, and inherent heterogeneity--factors that pose substantial challenges to real-world applicability. To bridge this gap, we investigate large-scale heterogeneous perimeter-defense game in a three-dimensional setting, incorporating realistic elements such as motion dynamics and wind fields. We derive the Nash equilibrium strategies for both attackers and defenders, characterize the victory regions, and validate our theoretical findings through extensive simulations. To tackle large-scale heterogeneous control challenges in defense strategies, we propose an Embedded Mean-Field Actor-Critic (EMFAC) framework. EMFAC leverages representation learning to enable high-level action aggregation in a mean-field manner, supporting scalable coordination among defenders. Furthermore, we introduce a lightweight agent-level attention mechanism based on reward representation, which selectively filters observations and mean-field information to enhance decision-making efficiency and accelerate convergence in large-scale tasks. Extensive simulations across varying scales demonstrate the effectiveness and adaptability of EMFAC, which outperforms established baselines in both convergence speed and overall performance. To further validate practicality, we test EMFAC in small-scale real-world experiments and conduct detailed analyses, offering deeper insights into the framework's effectiveness in complex scenarios.
HELM: Human-Preferred Exploration with Language Models
Mar 10, 2025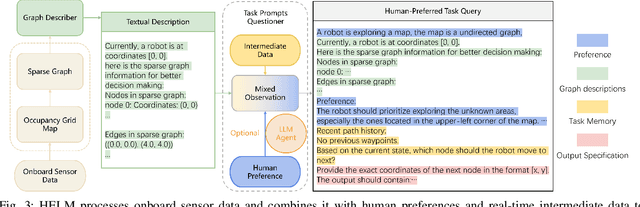
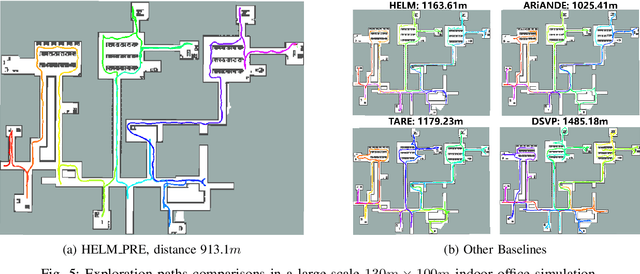
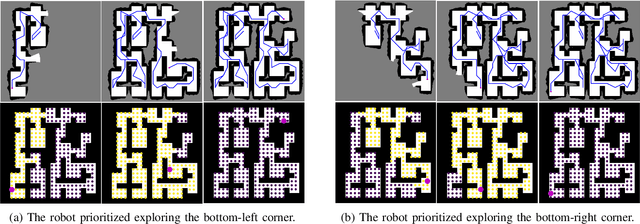
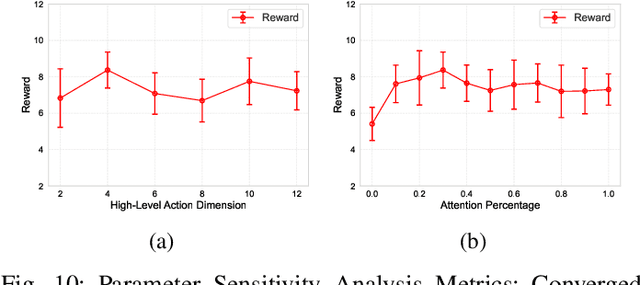
In autonomous exploration tasks, robots are required to explore and map unknown environments while efficiently planning in dynamic and uncertain conditions. Given the significant variability of environments, human operators often have specific preference requirements for exploration, such as prioritizing certain areas or optimizing for different aspects of efficiency. However, existing methods struggle to accommodate these human preferences adaptively, often requiring extensive parameter tuning or network retraining. With the recent advancements in Large Language Models (LLMs), which have been widely applied to text-based planning and complex reasoning, their potential for enhancing autonomous exploration is becoming increasingly promising. Motivated by this, we propose an LLM-based human-preferred exploration framework that seamlessly integrates a mobile robot system with LLMs. By leveraging the reasoning and adaptability of LLMs, our approach enables intuitive and flexible preference control through natural language while maintaining a task success rate comparable to state-of-the-art traditional methods. Experimental results demonstrate that our framework effectively bridges the gap between human intent and policy preference in autonomous exploration, offering a more user-friendly and adaptable solution for real-world robotic applications.