 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFARE: Fast-Slow Agentic Robotic Exploration
Jan 21, 2026This work advances autonomous robot exploration by integrating agent-level semantic reasoning with fast local control. We introduce FARE, a hierarchical autonomous exploration framework that integrates a large language model (LLM) for global reasoning with a reinforcement learning (RL) policy for local decision making. FARE follows a fast-slow thinking paradigm. The slow-thinking LLM module interprets a concise textual description of the unknown environment and synthesizes an agent-level exploration strategy, which is then grounded into a sequence of global waypoints through a topological graph. To further improve reasoning efficiency, this module employs a modularity-based pruning mechanism that reduces redundant graph structures. The fast-thinking RL module executes exploration by reacting to local observations while being guided by the LLM-generated global waypoints. The RL policy is additionally shaped by a reward term that encourages adherence to the global waypoints, enabling coherent and robust closed-loop behavior. This architecture decouples semantic reasoning from geometric decision, allowing each module to operate in its appropriate temporal and spatial scale. In challenging simulated environments, our results show that FARE achieves substantial improvements in exploration efficiency over state-of-the-art baselines. We further deploy FARE on hardware and validate it in complex, large scale $200m\times130m$ building environment.
GRATE: a Graph transformer-based deep Reinforcement learning Approach for Time-efficient autonomous robot Exploration
Sep 16, 2025Autonomous robot exploration (ARE) is the process of a robot autonomously navigating and mapping an unknown environment. Recent Reinforcement Learning (RL)-based approaches typically formulate ARE as a sequential decision-making problem defined on a collision-free informative graph. However, these methods often demonstrate limited reasoning ability over graph-structured data. Moreover, due to the insufficient consideration of robot motion, the resulting RL policies are generally optimized to minimize travel distance, while neglecting time efficiency. To overcome these limitations, we propose GRATE, a Deep Reinforcement Learning (DRL)-based approach that leverages a Graph Transformer to effectively capture both local structure patterns and global contextual dependencies of the informative graph, thereby enhancing the model's reasoning capability across the entire environment. In addition, we deploy a Kalman filter to smooth the waypoint outputs, ensuring that the resulting path is kinodynamically feasible for the robot to follow. Experimental results demonstrate that our method exhibits better exploration efficiency (up to 21.5% in distance and 21.3% in time to complete exploration) than state-of-the-art conventional and learning-based baselines in various simulation benchmarks. We also validate our planner in real-world scenarios.
DARE: Diffusion Policy for Autonomous Robot Exploration
Oct 22, 2024



Autonomous robot exploration requires a robot to efficiently explore and map unknown environments. Compared to conventional methods that can only optimize paths based on the current robot belief, learning-based methods show the potential to achieve improved performance by drawing on past experiences to reason about unknown areas. In this paper, we propose DARE, a novel generative approach that leverages diffusion models trained on expert demonstrations, which can explicitly generate an exploration path through one-time inference. We build DARE upon an attention-based encoder and a diffusion policy model, and introduce ground truth optimal demonstrations for training to learn better patterns for exploration. The trained planner can reason about the partial belief to recognize the potential structure in unknown areas and consider these areas during path planning. Our experiments demonstrate that DARE achieves on-par performance with both conventional and learning-based state-of-the-art exploration planners, as well as good generalizability in both simulations and real-life scenarios.
IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity
Sep 07, 2024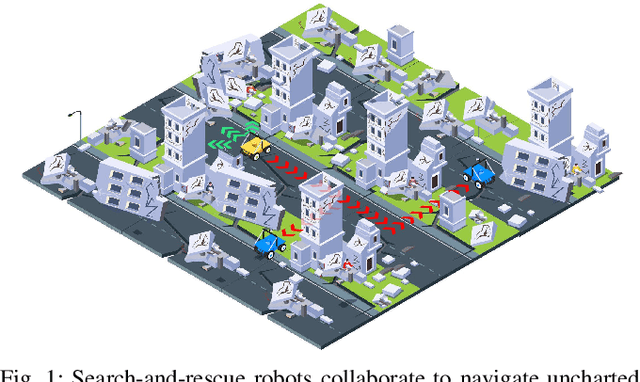

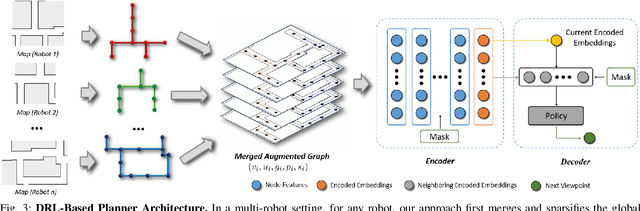
Information sharing is critical in time-sensitive and realistic multi-robot exploration, especially for smaller robotic teams in large-scale environments where connectivity may be sparse and intermittent. Existing methods often overlook such communication constraints by assuming unrealistic global connectivity. Other works account for communication constraints (by maintaining close proximity or line of sight during information exchange), but are often inefficient. For instance, preplanned rendezvous approaches typically involve unnecessary detours resulting from poorly timed rendezvous, while pursuit-based approaches often result in short-sighted decisions due to their greedy nature. We present IR2, a deep reinforcement learning approach to information sharing for multi-robot exploration. Leveraging attention-based neural networks trained via reinforcement and curriculum learning, IR2 allows robots to effectively reason about the longer-term trade-offs between disconnecting for solo exploration and reconnecting for information sharing. In addition, we propose a hierarchical graph formulation to maintain a sparse yet informative graph, enabling our approach to scale to large-scale environments. We present simulation results in three large-scale Gazebo environments, which show that our approach yields 6.6-34.1% shorter exploration paths and significantly improved mapped area consistency among robots when compared to state-of-the-art baselines. Our simulation training and testing code is available at https://github.com/marmotlab/IR2.
HDPlanner: Advancing Autonomous Deployments in Unknown Environments through Hierarchical Decision Networks
Aug 07, 2024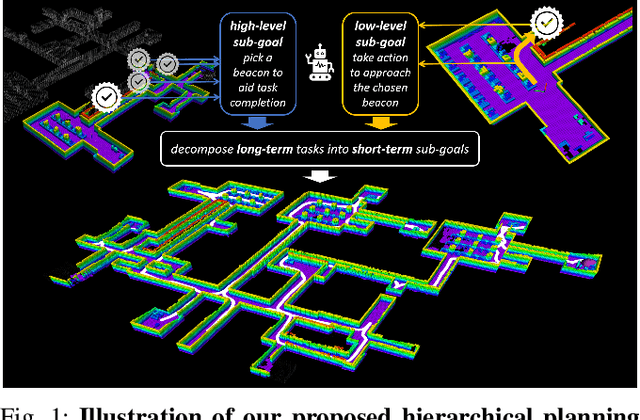
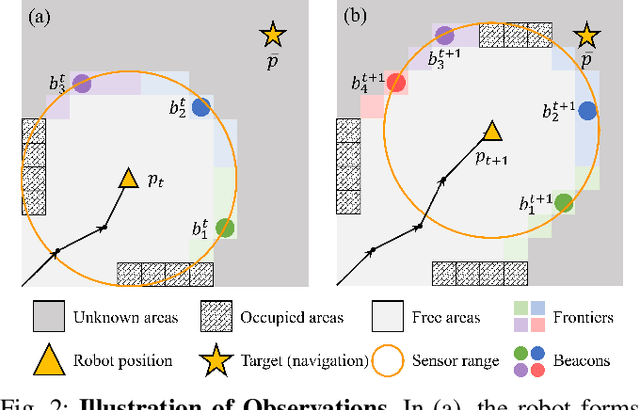
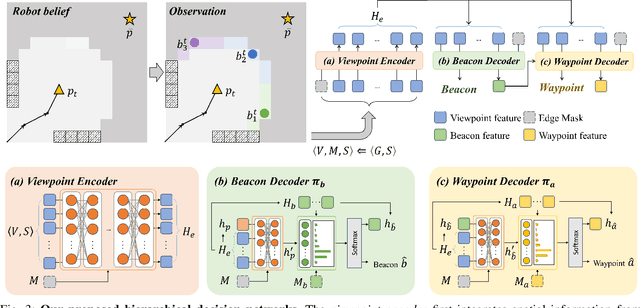
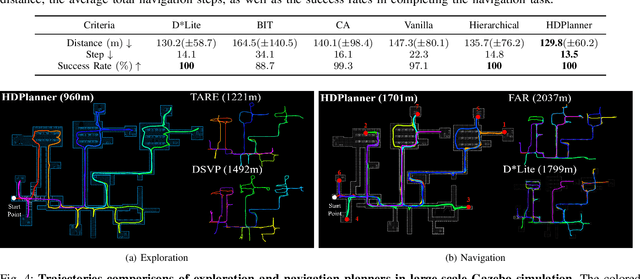
In this paper, we introduce HDPlanner, a deep reinforcement learning (DRL) based framework designed to tackle two core and challenging tasks for mobile robots: autonomous exploration and navigation, where the robot must optimize its trajectory adaptively to achieve the task objective through continuous interactions in unknown environments. Specifically, HDPlanner relies on novel hierarchical attention networks to empower the robot to reason about its belief across multiple spatial scales and sequence collaborative decisions, where our networks decompose long-term objectives into short-term informative task assignments and informative path plannings. We further propose a contrastive learning-based joint optimization to enhance the robustness of HDPlanner. We empirically demonstrate that HDPlanner significantly outperforms state-of-the-art conventional and learning-based baselines on an extensive set of simulations, including hundreds of test maps and large-scale, complex Gazebo environments. Notably, HDPlanner achieves real-time planning with travel distances reduced by up to 35.7% compared to exploration benchmarks and by up to 16.5% than navigation benchmarks. Furthermore, we validate our approach on hardware, where it generates high-quality, adaptive trajectories in both indoor and outdoor environments, highlighting its real-world applicability without additional training.
Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration
Jul 29, 2024



Communication bandwidth is an important consideration in multi-robot exploration, where information exchange among robots is critical. While existing methods typically aim to reduce communication throughput, they either require significant computation or significantly compromise exploration efficiency. In this work, we propose a deep reinforcement learning framework based on communication and privileged reinforcement learning to achieve a significant reduction in bandwidth consumption, while minimally sacrificing exploration efficiency. Specifically, our approach allows robots to learn to embed the most salient information from their individual belief (partial map) over the environment into fixed-sized messages. Robots then reason about their own belief as well as received messages to distributedly explore the environment while avoiding redundant work. In doing so, we employ privileged learning and learned attention mechanisms to endow the critic (i.e., teacher) network with ground truth map knowledge to effectively guide the policy (i.e., student) network during training. Compared to relevant baselines, our model allows the team to reduce communication by up to two orders of magnitude, while only sacrificing a marginal 2.4\% in total travel distance, paving the way for efficient, distributed multi-robot exploration in bandwidth-limited scenarios.