 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-TTA: A Multimodal Test-Time Adaptation Framework for Visual Search in the Wild
May 16, 2025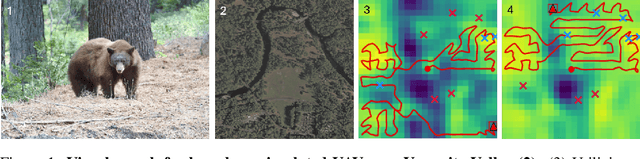
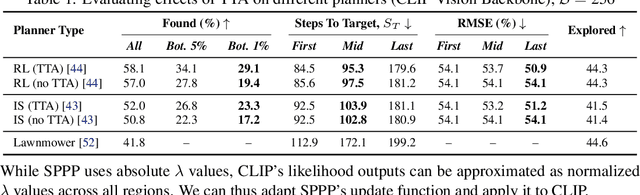

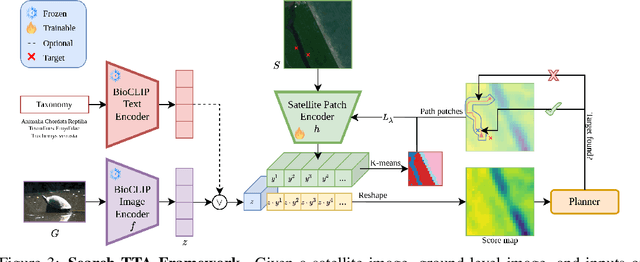
To perform autonomous visual search for environmental monitoring, a robot may leverage satellite imagery as a prior map. This can help inform coarse, high-level search and exploration strategies, even when such images lack sufficient resolution to allow fine-grained, explicit visual recognition of targets. However, there are some challenges to overcome with using satellite images to direct visual search. For one, targets that are unseen in satellite images are underrepresented (compared to ground images) in most existing datasets, and thus vision models trained on these datasets fail to reason effectively based on indirect visual cues. Furthermore, approaches which leverage large Vision Language Models (VLMs) for generalization may yield inaccurate outputs due to hallucination, leading to inefficient search. To address these challenges, we introduce Search-TTA, a multimodal test-time adaptation framework that can accept text and/or image input. First, we pretrain a remote sensing image encoder to align with CLIP's visual encoder to output probability distributions of target presence used for visual search. Second, our framework dynamically refines CLIP's predictions during search using a test-time adaptation mechanism. Through a feedback loop inspired by Spatial Poisson Point Processes, gradient updates (weighted by uncertainty) are used to correct (potentially inaccurate) predictions and improve search performance. To validate Search-TTA's performance, we curate a visual search dataset based on internet-scale ecological data. We find that Search-TTA improves planner performance by up to 9.7%, particularly in cases with poor initial CLIP predictions. It also achieves comparable performance to state-of-the-art VLMs. Finally, we deploy Search-TTA on a real UAV via hardware-in-the-loop testing, by simulating its operation within a large-scale simulation that provides onboard sensing.
IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity
Sep 07, 2024

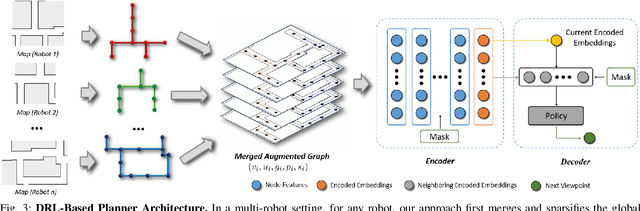
Information sharing is critical in time-sensitive and realistic multi-robot exploration, especially for smaller robotic teams in large-scale environments where connectivity may be sparse and intermittent. Existing methods often overlook such communication constraints by assuming unrealistic global connectivity. Other works account for communication constraints (by maintaining close proximity or line of sight during information exchange), but are often inefficient. For instance, preplanned rendezvous approaches typically involve unnecessary detours resulting from poorly timed rendezvous, while pursuit-based approaches often result in short-sighted decisions due to their greedy nature. We present IR2, a deep reinforcement learning approach to information sharing for multi-robot exploration. Leveraging attention-based neural networks trained via reinforcement and curriculum learning, IR2 allows robots to effectively reason about the longer-term trade-offs between disconnecting for solo exploration and reconnecting for information sharing. In addition, we propose a hierarchical graph formulation to maintain a sparse yet informative graph, enabling our approach to scale to large-scale environments. We present simulation results in three large-scale Gazebo environments, which show that our approach yields 6.6-34.1% shorter exploration paths and significantly improved mapped area consistency among robots when compared to state-of-the-art baselines. Our simulation training and testing code is available at https://github.com/marmotlab/IR2.
Privileged Reinforcement and Communication Learning for Distributed, Bandwidth-limited Multi-robot Exploration
Jul 29, 2024



Communication bandwidth is an important consideration in multi-robot exploration, where information exchange among robots is critical. While existing methods typically aim to reduce communication throughput, they either require significant computation or significantly compromise exploration efficiency. In this work, we propose a deep reinforcement learning framework based on communication and privileged reinforcement learning to achieve a significant reduction in bandwidth consumption, while minimally sacrificing exploration efficiency. Specifically, our approach allows robots to learn to embed the most salient information from their individual belief (partial map) over the environment into fixed-sized messages. Robots then reason about their own belief as well as received messages to distributedly explore the environment while avoiding redundant work. In doing so, we employ privileged learning and learned attention mechanisms to endow the critic (i.e., teacher) network with ground truth map knowledge to effectively guide the policy (i.e., student) network during training. Compared to relevant baselines, our model allows the team to reduce communication by up to two orders of magnitude, while only sacrificing a marginal 2.4\% in total travel distance, paving the way for efficient, distributed multi-robot exploration in bandwidth-limited scenarios.