 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-TTA: A Multimodal Test-Time Adaptation Framework for Visual Search in the Wild
May 16, 2025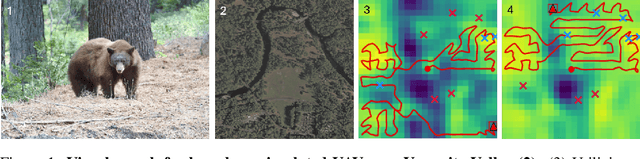

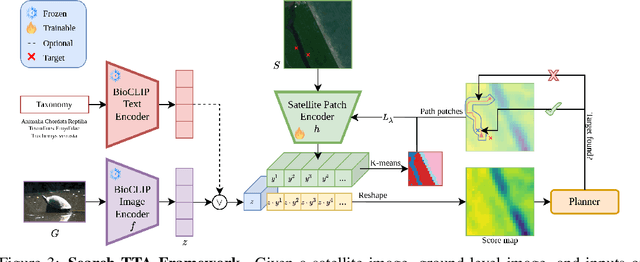
To perform autonomous visual search for environmental monitoring, a robot may leverage satellite imagery as a prior map. This can help inform coarse, high-level search and exploration strategies, even when such images lack sufficient resolution to allow fine-grained, explicit visual recognition of targets. However, there are some challenges to overcome with using satellite images to direct visual search. For one, targets that are unseen in satellite images are underrepresented (compared to ground images) in most existing datasets, and thus vision models trained on these datasets fail to reason effectively based on indirect visual cues. Furthermore, approaches which leverage large Vision Language Models (VLMs) for generalization may yield inaccurate outputs due to hallucination, leading to inefficient search. To address these challenges, we introduce Search-TTA, a multimodal test-time adaptation framework that can accept text and/or image input. First, we pretrain a remote sensing image encoder to align with CLIP's visual encoder to output probability distributions of target presence used for visual search. Second, our framework dynamically refines CLIP's predictions during search using a test-time adaptation mechanism. Through a feedback loop inspired by Spatial Poisson Point Processes, gradient updates (weighted by uncertainty) are used to correct (potentially inaccurate) predictions and improve search performance. To validate Search-TTA's performance, we curate a visual search dataset based on internet-scale ecological data. We find that Search-TTA improves planner performance by up to 9.7%, particularly in cases with poor initial CLIP predictions. It also achieves comparable performance to state-of-the-art VLMs. Finally, we deploy Search-TTA on a real UAV via hardware-in-the-loop testing, by simulating its operation within a large-scale simulation that provides onboard sensing.
HMR-ODTA: Online Diverse Task Allocation for a Team of Heterogeneous Mobile Robots
May 13, 2025
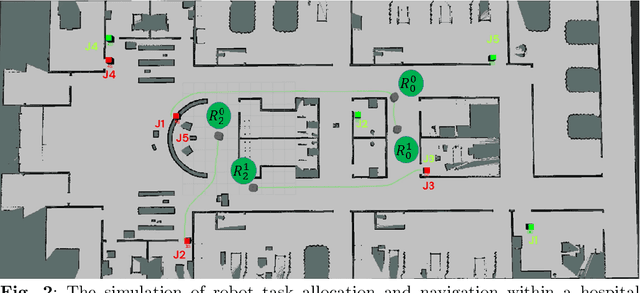

Coordinating time-sensitive deliveries in environments like hospitals poses a complex challenge, particularly when managing multiple online pickup and delivery requests within strict time windows using a team of heterogeneous robots. Traditional approaches fail to address dynamic rescheduling or diverse service requirements, typically restricting robots to single-task types. This paper tackles the Multi-Pickup and Delivery Problem with Time Windows (MPDPTW), where autonomous mobile robots are capable of handling varied service requests. The objective is to minimize late delivery penalties while maximizing task completion rates. To achieve this, we propose a novel framework leveraging a heterogeneous robot team and an efficient dynamic scheduling algorithm that supports dynamic task rescheduling. Users submit requests with specific time constraints, and our decentralized algorithm, Heterogeneous Mobile Robots Online Diverse Task Allocation (HMR-ODTA), optimizes task assignments to ensure timely service while addressing delays or task rejections. Extensive simulations validate the algorithm's effectiveness. For smaller task sets (40-160 tasks), penalties were reduced by nearly 63%, while for larger sets (160-280 tasks), penalties decreased by approximately 50%. These results highlight the algorithm's effectiveness in improving task scheduling and coordination in multi-robot systems, offering a robust solution for enhancing delivery performance in structured, time-critical environments.
Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
Oct 28, 2024



Lifelong Multi-Agent Path Finding (LMAPF) is a variant of MAPF where agents are continually assigned new goals, necessitating frequent re-planning to accommodate these dynamic changes. Recently, this field has embraced learning-based methods, which reactively generate single-step actions based on individual local observations. However, it is still challenging for them to match the performance of the best search-based algorithms, especially in large-scale settings. This work proposes an imitation-learning-based LMAPF solver that introduces a novel communication module and systematic single-step collision resolution and global guidance techniques. Our proposed solver, Scalable Imitation Learning for LMAPF (SILLM), inherits the fast reasoning speed of learning-based methods and the high solution quality of search-based methods with the help of modern GPUs. Across six large-scale maps with up to 10,000 agents and varying obstacle structures, SILLM surpasses the best learning- and search-based baselines, achieving average throughput improvements of 137.7% and 16.0%, respectively. Furthermore, SILLM also beats the winning solution of the 2023 League of Robot Runners, an international LMAPF competition sponsored by Amazon Robotics. Finally, we validated SILLM with 10 real robots and 100 virtual robots in a mockup warehouse environment.
Social Behavior as a Key to Learning-based Multi-Agent Pathfinding Dilemmas
Aug 06, 2024The Multi-agent Path Finding (MAPF) problem involves finding collision-free paths for a team of agents in a known, static environment, with important applications in warehouse automation, logistics, or last-mile delivery. To meet the needs of these large-scale applications, current learning-based methods often deploy the same fully trained, decentralized network to all agents to improve scalability. However, such parameter sharing typically results in homogeneous behaviors among agents, which may prevent agents from breaking ties around symmetric conflict (e.g., bottlenecks) and might lead to live-/deadlocks. In this paper, we propose SYLPH, a novel learning-based MAPF framework aimed to mitigate the adverse effects of homogeneity by allowing agents to learn and dynamically select different social behaviors (akin to individual, dynamic roles), without affecting the scalability offered by parameter sharing. Specifically, SYLPH agents learn to select their Social Value Orientation (SVO) given the situation at hand, quantifying their own level of selfishness/altruism, as well as an SVO-conditioned MAPF policy dictating their movement actions. To these ends, each agent first determines the most influential other agent in the system by predicting future conflicts/interactions with other agents. Each agent selects its own SVO towards that agent, and trains its decentralized MAPF policy to enact this SVO until another agent becomes more influential. To further allow agents to consider each others' social preferences, each agent gets access to the SVO value of their neighbors. As a result of this hierarchical decision-making and exchange of social preferences, SYLPH endows agents with the ability to reason about the MAPF task through more latent spaces and nuanced contexts, leading to varied responses that can help break ties around symmetric conflicts. [...]
LNS2+RL: Combining Multi-agent Reinforcement Learning with Large Neighborhood Search in Multi-agent Path Finding
May 28, 2024Multi-Agent Path Finding (MAPF) is a critical component of logistics and warehouse management, which focuses on planning collision-free paths for a team of robots in a known environment. Recent work introduced a novel MAPF approach, LNS2, which proposed to repair a quickly-obtainable set of infeasible paths via iterative re-planning, by relying on a fast, yet lower-quality, priority-based planner. At the same time, there has been a recent push for Multi-Agent Reinforcement Learning (MARL) based MAPF algorithms, which let agents learn decentralized policies that exhibit improved cooperation over such priority planning, although inevitably remaining slower. In this paper, we introduce a new MAPF algorithm, LNS2+RL, which combines the distinct yet complementary characteristics of LNS2 and MARL to effectively balance their individual limitations and get the best from both worlds. During early iterations, LNS2+RL relies on MARL for low-level re-planning, which we show eliminates collisions much more than a priority-based planner. There, our MARL-based planner allows agents to reason about past and future/predicted information to gradually learn cooperative decision-making through a finely designed curriculum learning. At later stages of planning, LNS2+RL adaptively switches to priority-based planning to quickly resolve the remaining collisions, naturally trading-off solution quality and computational efficiency. Our comprehensive experiments on challenging tasks across various team sizes, world sizes, and map structures consistently demonstrate the superior performance of LNS2+RL compared to many MAPF algorithms, including LNS2, LaCAM, and EECBS, where LNS2+RL shows significantly better performance in complex scenarios. We finally experimentally validate our algorithm in a hybrid simulation of a warehouse mockup involving a team of 100 (real-world and simulated) robots.
ALPHA: Attention-based Long-horizon Pathfinding in Highly-structured Areas
Oct 12, 2023The multi-agent pathfinding (MAPF) problem seeks collision-free paths for a team of agents from their current positions to their pre-set goals in a known environment, and is an essential problem found at the core of many logistics, transportation, and general robotics applications. Existing learning-based MAPF approaches typically only let each agent make decisions based on a limited field-of-view (FOV) around its position, as a natural means to fix the input dimensions of its policy network. However, this often makes policies short-sighted, since agents lack the ability to perceive and plan for obstacles/agents beyond their FOV. To address this challenge, we propose ALPHA, a new framework combining the use of ground truth proximal (local) information and fuzzy distal (global) information to let agents sequence local decisions based on the full current state of the system, and avoid such myopicity. We further allow agents to make short-term predictions about each others' paths, as a means to reason about each others' path intentions, thereby enhancing the level of cooperation among agents at the whole system level. Our neural structure relies on a Graph Transformer architecture to allow agents to selectively combine these different sources of information and reason about their inter-dependencies at different spatial scales. Our simulation experiments demonstrate that ALPHA outperforms both globally-guided MAPF solvers and communication-learning based ones, showcasing its potential towards scalability in realistic deployments.