 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBTPG-max: Achieving Local Maximal Bidirectional Pairs for Bidirectional Temporal Plan Graphs
Aug 06, 2025Multi-Agent Path Finding (MAPF) requires computing collision-free paths for multiple agents in shared environment. Most MAPF planners assume that each agent reaches a specific location at a specific timestep, but this is infeasible to directly follow on real systems where delays often occur. To address collisions caused by agents deviating due to delays, the Temporal Plan Graph (TPG) was proposed, which converts a MAPF time dependent solution into a time independent set of inter-agent dependencies. Recently, a Bidirectional TPG (BTPG) was proposed which relaxed some dependencies into ``bidirectional pairs" and improved efficiency of agents executing their MAPF solution with delays. Our work improves upon this prior work by designing an algorithm, BPTG-max, that finds more bidirectional pairs. Our main theoretical contribution is in designing the BTPG-max algorithm is locally optimal, i.e. which constructs a BTPG where no additional bidirectional pairs can be added. We also show how in practice BTPG-max leads to BTPGs with significantly more bidirectional edges, superior anytime behavior, and improves robustness to delays.
Anytime Single-Step MAPF Planning with Anytime PIBT
Apr 10, 2025PIBT is a popular Multi-Agent Path Finding (MAPF) method at the core of many state-of-the-art MAPF methods including LaCAM, CS-PIBT, and WPPL. The main utility of PIBT is that it is a very fast and effective single-step MAPF solver and can return a collision-free single-step solution for hundreds of agents in less than a millisecond. However, the main drawback of PIBT is that it is extremely greedy in respect to its priorities and thus leads to poor solution quality. Additionally, PIBT cannot use all the planning time that might be available to it and returns the first solution it finds. We thus develop Anytime PIBT, which quickly finds a one-step solution identically to PIBT but then continuously improves the solution in an anytime manner. We prove that Anytime PIBT converges to the optimal solution given sufficient time. We experimentally validate that Anytime PIBT can rapidly improve single-step solution quality within milliseconds and even find the optimal single-step action. However, we interestingly find that improving the single-step solution quality does not have a significant effect on full-horizon solution costs.
Real-Time LaCAM
Apr 08, 2025The vast majority of Multi-Agent Path Finding (MAPF) methods with completeness guarantees require planning full horizon paths. However, planning full horizon paths can take too long and be impractical in real-world applications. Instead, real-time planning and execution, which only allows the planner a finite amount of time before executing and replanning, is more practical for real world multi-agent systems. Several methods utilize real-time planning schemes but none are provably complete, which leads to livelock or deadlock. Our main contribution is to show the first Real-Time MAPF method with provable completeness guarantees. We do this by leveraging LaCAM (Okumura 2023) in an incremental fashion. Our results show how we can iteratively plan for congested environments with a cutoff time of milliseconds while still maintaining the same success rate as full horizon LaCAM. We also show how it can be used with a single-step learned MAPF policy. The proposed Real-Time LaCAM also provides us with a general mechanism for using iterative constraints for completeness in future real-time MAPF algorithms.
Deploying Ten Thousand Robots: Scalable Imitation Learning for Lifelong Multi-Agent Path Finding
Oct 28, 2024



Lifelong Multi-Agent Path Finding (LMAPF) is a variant of MAPF where agents are continually assigned new goals, necessitating frequent re-planning to accommodate these dynamic changes. Recently, this field has embraced learning-based methods, which reactively generate single-step actions based on individual local observations. However, it is still challenging for them to match the performance of the best search-based algorithms, especially in large-scale settings. This work proposes an imitation-learning-based LMAPF solver that introduces a novel communication module and systematic single-step collision resolution and global guidance techniques. Our proposed solver, Scalable Imitation Learning for LMAPF (SILLM), inherits the fast reasoning speed of learning-based methods and the high solution quality of search-based methods with the help of modern GPUs. Across six large-scale maps with up to 10,000 agents and varying obstacle structures, SILLM surpasses the best learning- and search-based baselines, achieving average throughput improvements of 137.7% and 16.0%, respectively. Furthermore, SILLM also beats the winning solution of the 2023 League of Robot Runners, an international LMAPF competition sponsored by Amazon Robotics. Finally, we validated SILLM with 10 real robots and 100 virtual robots in a mockup warehouse environment.
ANAVI: Audio Noise Awareness using Visuals of Indoor environments for NAVIgation
Oct 24, 2024



We propose Audio Noise Awareness using Visuals of Indoors for NAVIgation for quieter robot path planning. While humans are naturally aware of the noise they make and its impact on those around them, robots currently lack this awareness. A key challenge in achieving audio awareness for robots is estimating how loud will the robot's actions be at a listener's location? Since sound depends upon the geometry and material composition of rooms, we train the robot to passively perceive loudness using visual observations of indoor environments. To this end, we generate data on how loud an 'impulse' sounds at different listener locations in simulated homes, and train our Acoustic Noise Predictor (ANP). Next, we collect acoustic profiles corresponding to different actions for navigation. Unifying ANP with action acoustics, we demonstrate experiments with wheeled (Hello Robot Stretch) and legged (Unitree Go2) robots so that these robots adhere to the noise constraints of the environment. See code and data at https://anavi-corl24.github.io/
Windowed MAPF with Completeness Guarantees
Oct 02, 2024



Traditional multi-agent path finding (MAPF) methods try to compute entire start-goal paths which are collision free. However, computing an entire path can take too long for MAPF systems where agents need to replan fast. Methods that address this typically employ a "windowed" approach and only try to find collision free paths for a small windowed timestep horizon. This adaptation comes at the cost of incompleteness; all current windowed approaches can become stuck in deadlock or livelock. Our main contribution is to introduce our framework, WinC-MAPF, for Windowed MAPF that enables completeness. Our framework uses heuristic update insights from single-agent real-time heuristic search algorithms as well as agent independence ideas from MAPF algorithms. We also develop Single-Step CBS (SS-CBS), an instantiation of this framework using a novel modification to CBS. We show how SS-CBS, which only plans a single step and updates heuristics, can effectively solve tough scenarios where existing windowed approaches fail.
A POMDP-based hierarchical planning framework for manipulation under pose uncertainty
Sep 27, 2024



Robots often face challenges in domestic environments where visual feedback is ineffective, such as retrieving objects obstructed by occlusions or finding a light switch in the dark. In these cases, utilizing contacts to localize the target object can be effective. We propose an online planning framework using binary contact signals for manipulation tasks with pose uncertainty, formulated as a Partially Observable Markov Decision Process (POMDP). Naively representing the belief as a particle set makes planning infeasible due to the large uncertainties in domestic settings, as identifying the best sequence of actions requires rolling out thousands of actions across millions of particles, taking significant compute time. To address this, we propose a hierarchical belief representation. Initially, we represent the uncertainty coarsely in a 3D volumetric space. Policies that refine uncertainty in this space are computed and executed, and once uncertainty is sufficiently reduced, the problem is translated back into the particle space for further refinement before task completion. We utilize a closed-loop planning and execution framework with a heuristic-search-based anytime solver that computes partial policies within a limited time budget. The performance of the framework is demonstrated both in real world and in simulation on the high-precision task of inserting a plug into a port using a UR10e manipulator, resolving positional uncertainties up to 50 centimeters and angular uncertainties close to $2\pi$. Experimental results highlight the framework's effectiveness, achieving a 93\% success rate in the real world and over 50\% improvement in solution quality compared to greedy baselines, significantly accelerating planning and enabling real-time solutions for complex problems.
Work Smarter Not Harder: Simple Imitation Learning with CS-PIBT Outperforms Large Scale Imitation Learning for MAPF
Sep 22, 2024



Multi-Agent Path Finding (MAPF) is the problem of effectively finding efficient collision-free paths for a group of agents in a shared workspace. The MAPF community has largely focused on developing high-performance heuristic search methods. Recently, several works have applied various machine learning (ML) techniques to solve MAPF, usually involving sophisticated architectures, reinforcement learning techniques, and set-ups, but none using large amounts of high-quality supervised data. Our initial objective in this work was to show how simple large scale imitation learning of high-quality heuristic search methods can lead to state-of-the-art ML MAPF performance. However, we find that, at least with our model architecture, simple large scale (700k examples with hundreds of agents per example) imitation learning does \textit{not} produce impressive results. Instead, we find that by using prior work that post-processes MAPF model predictions to resolve 1-step collisions (CS-PIBT), we can train a simple ML MAPF model in minutes that dramatically outperforms existing ML MAPF policies. This has serious implications for all future ML MAPF policies (with local communication) which currently struggle to scale. In particular, this finding implies that future learnt policies should (1) always use smart 1-step collision shields (e.g. CS-PIBT), (2) always include the collision shield with greedy actions as a baseline (e.g. PIBT) and (3) motivates future models to focus on longer horizon / more complex planning as 1-step collisions can be efficiently resolved.
A preprocessing-based planning framework for utilizing contacts in high-precision insertion tasks
Jun 08, 2024

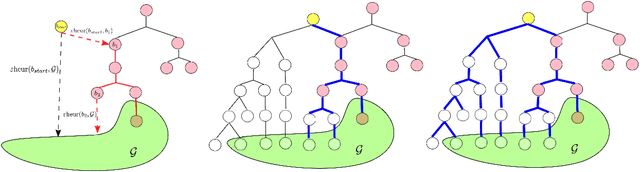
In manipulation tasks like plug insertion or assembly that have low tolerance to errors in pose estimation (errors of the order of 2mm can cause task failure), the utilization of touch/contact modality can aid in accurately localizing the object of interest. Motivated by this, in this work we model high-precision insertion tasks as planning problems under pose uncertainty, where we effectively utilize the occurrence of contacts (or the lack thereof) as observations to reduce uncertainty and reliably complete the task. We present a preprocessing-based planning framework for high-precision insertion in repetitive and time-critical settings, where the set of initial pose distributions (identified by a perception system) is finite. The finite set allows us to enumerate the possible planning problems that can be encountered online and preprocess a database of policies. Due to the computational complexity of constructing this database, we propose a general experience-based POMDP solver, E-RTDP-Bel, that uses the solutions of similar planning problems as experience to speed up planning queries and use it to efficiently construct the database. We show that the developed algorithm speeds up database creation by over a factor of 100, making the process computationally tractable. We demonstrate the effectiveness of the proposed framework in a real-world plug insertion task in the presence of port position uncertainty and a pipe assembly task in simulation in the presence of pipe pose uncertainty.
* \c{opyright} 2023 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Unconstraining Multi-Robot Manipulation: Enabling Arbitrary Constraints in ECBS with Bounded Sub-Optimality
May 07, 2024



Multi-Robot-Arm Motion Planning (M-RAMP) is a challenging problem featuring complex single-agent planning and multi-agent coordination. Recent advancements in extending the popular Conflict-Based Search (CBS) algorithm have made large strides in solving Multi-Agent Path Finding (MAPF) problems. However, fundamental challenges remain in applying CBS to M-RAMP. A core challenge is the existing reliance of the CBS framework on conservative "complete" constraints. These constraints ensure solution guarantees but often result in slow pruning of the search space -- causing repeated expensive single-agent planning calls. Therefore, even though it is possible to leverage domain knowledge and design incomplete M-RAMP-specific CBS constraints to more efficiently prune the search, using these constraints would render the algorithm itself incomplete. This forces practitioners to choose between efficiency and completeness. In light of these challenges, we propose a novel algorithm, Generalized ECBS, aimed at removing the burden of choice between completeness and efficiency in MAPF algorithms. Our approach enables the use of arbitrary constraints in conflict-based algorithms while preserving completeness and bounding sub-optimality. This enables practitioners to capitalize on the benefits of arbitrary constraints and opens a new space for constraint design in MAPF that has not been explored. We provide a theoretical analysis of our algorithms, propose new "incomplete" constraints, and demonstrate their effectiveness through experiments in M-RAMP.