 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Depression Detection from Social Media Text Using LLM-Derived Embeddings
Jun 07, 2025Accurate and interpretable detection of depressive language in social media is useful for early interventions of mental health conditions, and has important implications for both clinical practice and broader public health efforts. In this paper, we investigate the performance of large language models (LLMs) and traditional machine learning classifiers across three classification tasks involving social media data: binary depression classification, depression severity classification, and differential diagnosis classification among depression, PTSD, and anxiety. Our study compares zero-shot LLMs with supervised classifiers trained on both conventional text embeddings and LLM-generated summary embeddings. Our experiments reveal that while zero-shot LLMs demonstrate strong generalization capabilities in binary classification, they struggle with fine-grained ordinal classifications. In contrast, classifiers trained on summary embeddings generated by LLMs demonstrate competitive, and in some cases superior, performance on the classification tasks, particularly when compared to models using traditional text embeddings. Our findings demonstrate the strengths of LLMs in mental health prediction, and suggest promising directions for better utilization of their zero-shot capabilities and context-aware summarization techniques.
Dynamic Metasurface-Backed Luneburg Lens for Multiplexed Backscatter Communication
Mar 20, 2025Backscatter communications is attractive for its low power requirements due to the lack of actively radiating components; however, commonly used devices are typically limited in range and functionality. Here, we design and demonstrate a flattened Luneburg lens combined with a spatially-tunable dynamic metasurface to create a low-power backscatter communicator. The Luneburg lens is a spherically-symmetric lens that focuses a collimated beam from any direction, enabling a wide field-of-view with no aberrations. By applying quasi-conformal transformation optics (QCTO), we design a flattened Luneburg lens to facilitate its seamless interface with the planar metasurface. The gradient index of the Luneburg lens is realized through additive manufacturing. We show that the flattened Luneburg lens with a reflective surface at the flattened focal plane is able to achieve diffraction-limited retroreflection, enabling long-range backscatter communication. When an interrogator transmits towards the metasurface-backed Luneburg lens, the device can modulate the reflected signal phase across a wide field of regard to communicate data. We experimentally show that the spatial control over the metasurface allows different bit streams to be simultaneously communicated in different directions. Additionally, we show that the device is able to prevent eavesdroppers from receiving information, thus securing communications.
Work Smarter Not Harder: Simple Imitation Learning with CS-PIBT Outperforms Large Scale Imitation Learning for MAPF
Sep 22, 2024



Multi-Agent Path Finding (MAPF) is the problem of effectively finding efficient collision-free paths for a group of agents in a shared workspace. The MAPF community has largely focused on developing high-performance heuristic search methods. Recently, several works have applied various machine learning (ML) techniques to solve MAPF, usually involving sophisticated architectures, reinforcement learning techniques, and set-ups, but none using large amounts of high-quality supervised data. Our initial objective in this work was to show how simple large scale imitation learning of high-quality heuristic search methods can lead to state-of-the-art ML MAPF performance. However, we find that, at least with our model architecture, simple large scale (700k examples with hundreds of agents per example) imitation learning does \textit{not} produce impressive results. Instead, we find that by using prior work that post-processes MAPF model predictions to resolve 1-step collisions (CS-PIBT), we can train a simple ML MAPF model in minutes that dramatically outperforms existing ML MAPF policies. This has serious implications for all future ML MAPF policies (with local communication) which currently struggle to scale. In particular, this finding implies that future learnt policies should (1) always use smart 1-step collision shields (e.g. CS-PIBT), (2) always include the collision shield with greedy actions as a baseline (e.g. PIBT) and (3) motivates future models to focus on longer horizon / more complex planning as 1-step collisions can be efficiently resolved.
Leveraging Federated Learning for Automatic Detection of Clopidogrel Treatment Failures
Mar 05, 2024The effectiveness of clopidogrel, a widely used antiplatelet medication, varies significantly among individuals, necessitating the development of precise predictive models to optimize patient care. In this study, we leverage federated learning strategies to address clopidogrel treatment failure detection. Our research harnesses the collaborative power of multiple healthcare institutions, allowing them to jointly train machine learning models while safeguarding sensitive patient data. Utilizing the UK Biobank dataset, which encompasses a vast and diverse population, we partitioned the data based on geographic centers and evaluated the performance of federated learning. Our results show that while centralized training achieves higher Area Under the Curve (AUC) values and faster convergence, federated learning approaches can substantially narrow this performance gap. Our findings underscore the potential of federated learning in addressing clopidogrel treatment failure detection, offering a promising avenue for enhancing patient care through personalized treatment strategies while respecting data privacy. This study contributes to the growing body of research on federated learning in healthcare and lays the groundwork for secure and privacy-preserving predictive models for various medical conditions.
Data augmentation method for modeling health records with applications to clopidogrel treatment failure detection
Feb 28, 2024We present a novel data augmentation method to address the challenge of data scarcity in modeling longitudinal patterns in Electronic Health Records (EHR) of patients using natural language processing (NLP) algorithms. The proposed method generates augmented data by rearranging the orders of medical records within a visit where the order of elements are not obvious, if any. Applying the proposed method to the clopidogrel treatment failure detection task enabled up to 5.3% absolute improvement in terms of ROC-AUC (from 0.908 without augmentation to 0.961 with augmentation) when it was used during the pre-training procedure. It was also shown that the augmentation helped to improve performance during fine-tuning procedures, especially when the amount of labeled training data is limited.
Automatic prediction of mortality in patients with mental illness using electronic health records
Oct 18, 2023Mental disorders impact the lives of millions of people globally, not only impeding their day-to-day lives but also markedly reducing life expectancy. This paper addresses the persistent challenge of predicting mortality in patients with mental diagnoses using predictive machine-learning models with electronic health records (EHR). Data from patients with mental disease diagnoses were extracted from the well-known clinical MIMIC-III data set utilizing demographic, prescription, and procedural information. Four machine learning algorithms (Logistic Regression, Random Forest, Support Vector Machine, and K-Nearest Neighbors) were used, with results indicating that Random Forest and Support Vector Machine models outperformed others, with AUC scores of 0.911. Feature importance analysis revealed that drug prescriptions, particularly Morphine Sulfate, play a pivotal role in prediction. We applied a variety of machine learning algorithms to predict 30-day mortality followed by feature importance analysis. This study can be used to assist hospital workers in identifying at-risk patients to reduce excess mortality.
Why Do Students Drop Out? University Dropout Prediction and Associated Factor Analysis Using Machine Learning Techniques
Oct 17, 2023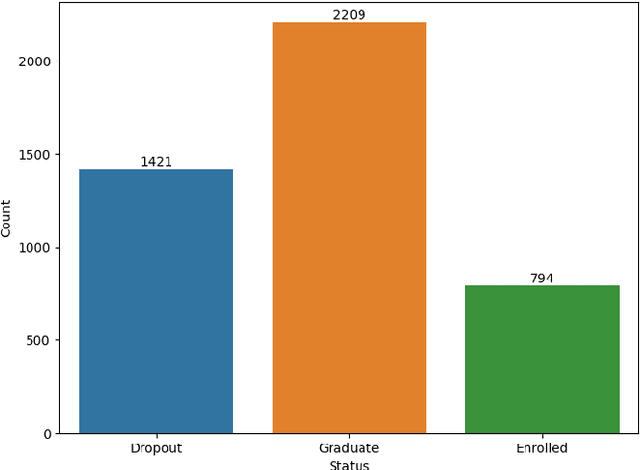
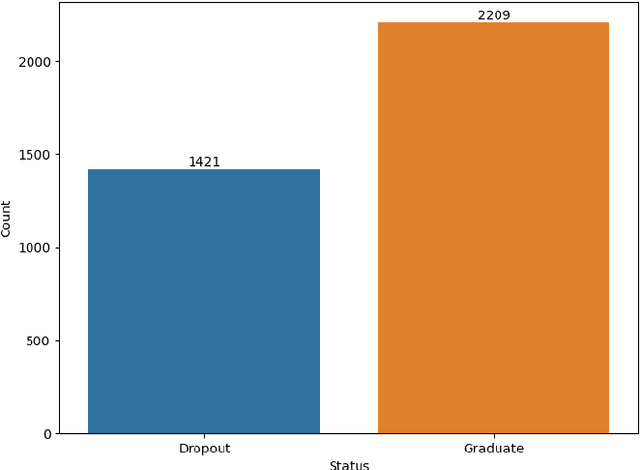
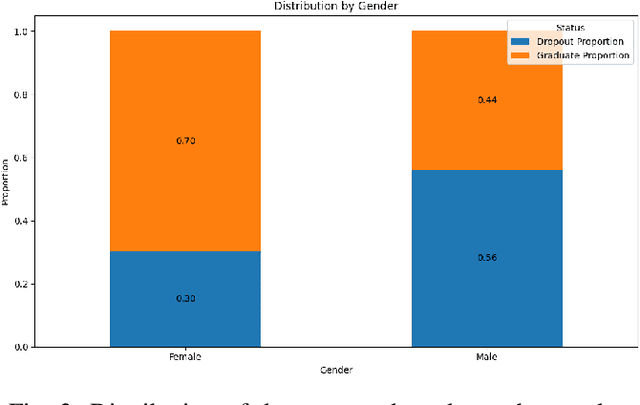
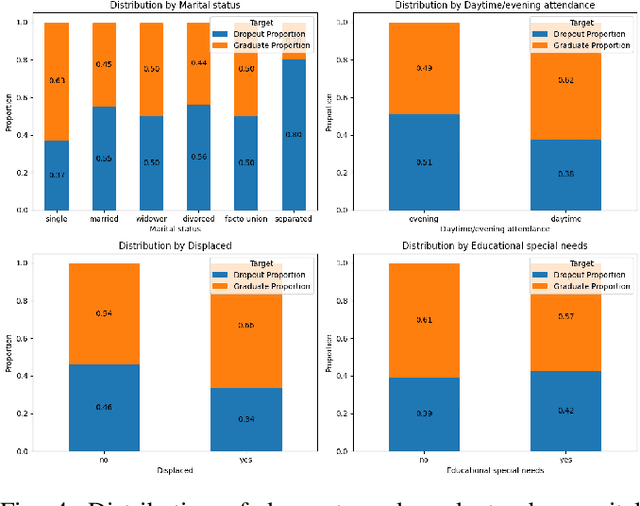
Graduation and dropout rates have always been a serious consideration for educational institutions and students. High dropout rates negatively impact both the lives of individual students and institutions. To address this problem, this study examined university dropout prediction using academic, demographic, socioeconomic, and macroeconomic data types. Additionally, we performed associated factor analysis to analyze which type of data would be most influential on the performance of machine learning models in predicting graduation and dropout status. These features were used to train four binary classifiers to determine if students would graduate or drop out. The overall performance of the classifiers in predicting dropout status had an average ROC-AUC score of 0.935. The data type most influential to the model performance was found to be academic data, with the average ROC-AUC score dropping from 0.935 to 0.811 when excluding all academic-related features from the data set. Preliminary results indicate that a correlation does exist between data types and dropout status.
Detection and prediction of clopidogrel treatment failures using longitudinal structured electronic health records
Oct 12, 2023We propose machine learning algorithms to automatically detect and predict clopidogrel treatment failure using longitudinal structured electronic health records (EHR). By drawing analogies between natural language and structured EHR, we introduce various machine learning algorithms used in natural language processing (NLP) applications to build models for treatment failure detection and prediction. In this regard, we generated a cohort of patients with clopidogrel prescriptions from UK Biobank and annotated if the patients had treatment failure events within one year of the first clopidogrel prescription; out of 502,527 patients, 1,824 patients were identified as treatment failure cases, and 6,859 patients were considered as control cases. From the dataset, we gathered diagnoses, prescriptions, and procedure records together per patient and organized them into visits with the same date to build models. The models were built for two different tasks, i.e., detection and prediction, and the experimental results showed that time series models outperform bag-of-words approaches in both tasks. In particular, a Transformer-based model, namely BERT, could reach 0.928 AUC in detection tasks and 0.729 AUC in prediction tasks. BERT also showed competence over other time series models when there is not enough training data, because it leverages the pre-training procedure using large unlabeled data.
Multi-Site Clinical Federated Learning using Recursive and Attentive Models and NVFlare
Jun 28, 2023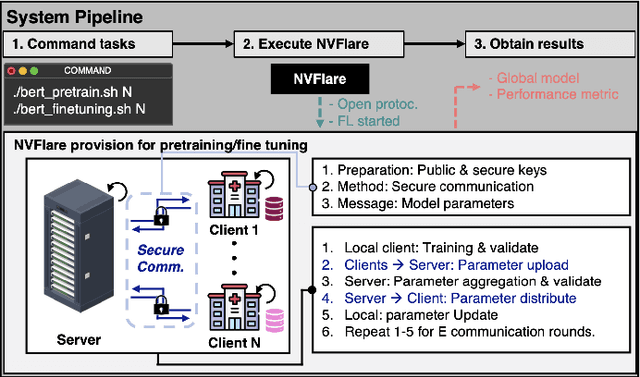
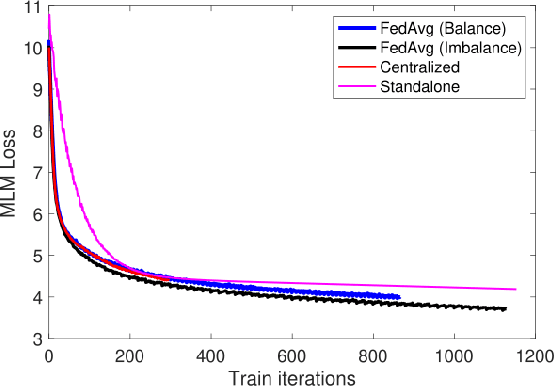
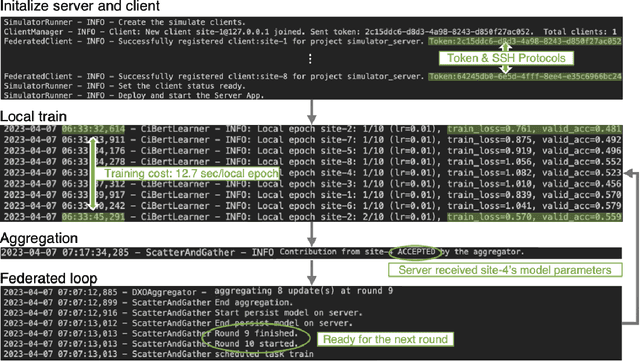
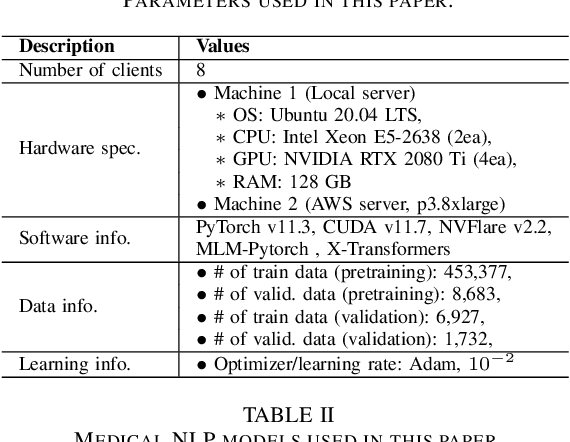
The prodigious growth of digital health data has precipitated a mounting interest in harnessing machine learning methodologies, such as natural language processing (NLP), to scrutinize medical records, clinical notes, and other text-based health information. Although NLP techniques have exhibited substantial potential in augmenting patient care and informing clinical decision-making, data privacy and adherence to regulations persist as critical concerns. Federated learning (FL) emerges as a viable solution, empowering multiple organizations to train machine learning models collaboratively without disseminating raw data. This paper proffers a pragmatic approach to medical NLP by amalgamating FL, NLP models, and the NVFlare framework, developed by NVIDIA. We introduce two exemplary NLP models, the Long-Short Term Memory (LSTM)-based model and Bidirectional Encoder Representations from Transformers (BERT), which have demonstrated exceptional performance in comprehending context and semantics within medical data. This paper encompasses the development of an integrated framework that addresses data privacy and regulatory compliance challenges while maintaining elevated accuracy and performance, incorporating BERT pretraining, and comprehensively substantiating the efficacy of the proposed approach.
Predicting Development of Chronic Obstructive Pulmonary Disease and its Risk Factor Analysis
Feb 06, 2023



Chronic Obstructive Pulmonary Disease (COPD) is an irreversible airway obstruction with a high societal burden. Although smoking is known to be the biggest risk factor, additional components need to be considered. In this study, we aim to identify COPD risk factors by applying machine learning models that integrate sociodemographic, clinical, and genetic data to predict COPD development.