 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFront-to-Attractors: Modifying the Front-to-Front Heuristic in Bidirectional Search
Jun 05, 2026Heuristics play a central role in the performance of bidirectional search algorithms, which commonly rely on two main classes. Front-to-end (F2E) heuristics estimate the distance from a state s to the target of the search (the goal for forward search or the start for backward search). In contrast, front-to-front (F2F) heuristics estimate the distance from s to the opposite search frontier using a pairwise function h(s, s'), where s' ranges over frontier states. Although F2F heuristics are typically more informative and therefore reduce the number of node expansions, their reliance on extensive pairwise evaluations incurs substantial computational overhead. To address this limitation, we introduce a new heuristic class, front-to-attractors (F2A), that preserves much of the informativeness of F2F while dramatically reducing its computational cost. Rather than evaluating distances to all states on the opposite frontier, F2A estimates the distance from s to a small, dynamically maintained set of attractors in the opposite search direction. These attractors serve as a surrogate for the full frontier, enabling rich heuristic guidance at a fraction of the computational expense while maintaining the optimality guarantees offered by F2F. We evaluate F2A across multiple domains and show that it reduces the number of pairwise evaluations by up to 11.2x compared to F2F, while achieving 4.8x fewer node expansions than F2E on average.
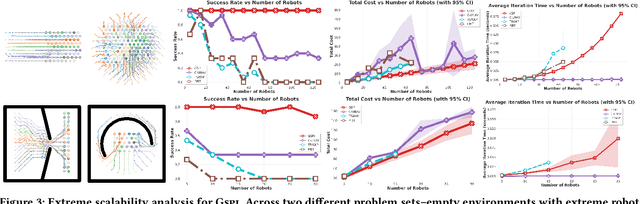
Multi Graph Search for High-Dimensional Robot Motion Planning
Feb 12, 2026Efficient motion planning for high-dimensional robotic systems, such as manipulators and mobile manipulators, is critical for real-time operation and reliable deployment. Although advances in planning algorithms have enhanced scalability to high-dimensional state spaces, these improvements often come at the cost of generating unpredictable, inconsistent motions or requiring excessive computational resources and memory. In this work, we introduce Multi-Graph Search (MGS), a search-based motion planning algorithm that generalizes classical unidirectional and bidirectional search to a multi-graph setting. MGS maintains and incrementally expands multiple implicit graphs over the state space, focusing exploration on high-potential regions while allowing initially disconnected subgraphs to be merged through feasible transitions as the search progresses. We prove that MGS is complete and bounded-suboptimal, and empirically demonstrate its effectiveness on a range of manipulation and mobile manipulation tasks. Demonstrations, benchmarks and code are available at https://multi-graph-search.github.io/.
Collaborative Multi-Robot Non-Prehensile Manipulation via Flow-Matching Co-Generation
Nov 14, 2025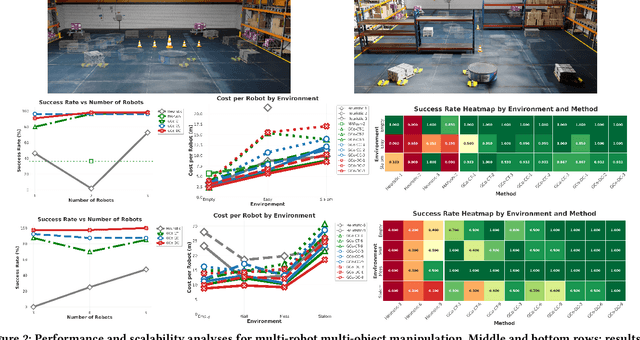


Coordinating a team of robots to reposition multiple objects in cluttered environments requires reasoning jointly about where robots should establish contact, how to manipulate objects once contact is made, and how to navigate safely and efficiently at scale. Prior approaches typically fall into two extremes -- either learning the entire task or relying on privileged information and hand-designed planners -- both of which struggle to handle diverse objects in long-horizon tasks. To address these challenges, we present a unified framework for collaborative multi-robot, multi-object non-prehensile manipulation that integrates flow-matching co-generation with anonymous multi-robot motion planning. Within this framework, a generative model co-generates contact formations and manipulation trajectories from visual observations, while a novel motion planner conveys robots at scale. Crucially, the same planner also supports coordination at the object level, assigning manipulated objects to larger target structures and thereby unifying robot- and object-level reasoning within a single algorithmic framework. Experiments in challenging simulated environments demonstrate that our approach outperforms baselines in both motion planning and manipulation tasks, highlighting the benefits of generative co-design and integrated planning for scaling collaborative manipulation to complex multi-agent, multi-object settings. Visit gco-paper.github.io for code and demonstrations.
Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
Sep 04, 2025Long-horizon planning for robot manipulation is a challenging problem that requires reasoning about the effects of a sequence of actions on a physical 3D scene. While traditional task planning methods are shown to be effective for long-horizon manipulation, they require discretizing the continuous state and action space into symbolic descriptions of objects, object relationships, and actions. Instead, we propose a hybrid learning-and-planning approach that leverages learned models as domain-specific priors to guide search in high-dimensional continuous action spaces. We introduce SPOT: Search over Point cloud Object Transformations, which plans by searching for a sequence of transformations from an initial scene point cloud to a goal-satisfying point cloud. SPOT samples candidate actions from learned suggesters that operate on partially observed point clouds, eliminating the need to discretize actions or object relationships. We evaluate SPOT on multi-object rearrangement tasks, reporting task planning success and task execution success in both simulation and real-world environments. Our experiments show that SPOT generates successful plans and outperforms a policy-learning approach. We also perform ablations that highlight the importance of search-based planning.
A-MHA*: Anytime Multi-Heuristic A*
Aug 29, 2025Designing good heuristic functions for graph search requires adequate domain knowledge. It is often easy to design heuristics that perform well and correlate with the underlying true cost-to-go values in certain parts of the search space but these may not be admissible throughout the domain thereby affecting the optimality guarantees of the search. Bounded suboptimal search using several such partially good but inadmissible heuristics was developed in Multi-Heuristic A* (MHA*). Although MHA* leverages multiple inadmissible heuristics to potentially generate a faster suboptimal solution, the original version does not improve the solution over time. It is a one shot algorithm that requires careful setting of inflation factors to obtain a desired one time solution. In this work, we tackle this issue by extending MHA* to an anytime version that finds a feasible suboptimal solution quickly and continually improves it until time runs out. Our work is inspired from the Anytime Repairing A* (ARA*) algorithm. We prove that our precise adaptation of ARA* concepts in the MHA* framework preserves the original suboptimal and completeness guarantees and enhances MHA* to perform in an anytime fashion. Furthermore, we report the performance of A-MHA* in 3-D path planning domain and sliding tiles puzzle and compare against MHA* and other anytime algorithms.
Optimal Interactive Learning on the Job via Facility Location Planning
May 01, 2025Collaborative robots must continually adapt to novel tasks and user preferences without overburdening the user. While prior interactive robot learning methods aim to reduce human effort, they are typically limited to single-task scenarios and are not well-suited for sustained, multi-task collaboration. We propose COIL (Cost-Optimal Interactive Learning) -- a multi-task interaction planner that minimizes human effort across a sequence of tasks by strategically selecting among three query types (skill, preference, and help). When user preferences are known, we formulate COIL as an uncapacitated facility location (UFL) problem, which enables bounded-suboptimal planning in polynomial time using off-the-shelf approximation algorithms. We extend our formulation to handle uncertainty in user preferences by incorporating one-step belief space planning, which uses these approximation algorithms as subroutines to maintain polynomial-time performance. Simulated and physical experiments on manipulation tasks show that our framework significantly reduces the amount of work allocated to the human while maintaining successful task completion.
MOSAIC: A Skill-Centric Algorithmic Framework for Long-Horizon Manipulation Planning
Apr 23, 2025Planning long-horizon motions using a set of predefined skills is a key challenge in robotics and AI. Addressing this challenge requires methods that systematically explore skill combinations to uncover task-solving sequences, harness generic, easy-to-learn skills (e.g., pushing, grasping) to generalize across unseen tasks, and bypass reliance on symbolic world representations that demand extensive domain and task-specific knowledge. Despite significant progress, these elements remain largely disjoint in existing approaches, leaving a critical gap in achieving robust, scalable solutions for complex, long-horizon problems. In this work, we present MOSAIC, a skill-centric framework that unifies these elements by using the skills themselves to guide the planning process. MOSAIC uses two families of skills: Generators compute executable trajectories and world configurations, and Connectors link these independently generated skill trajectories by solving boundary value problems, enabling progress toward completing the overall task. By breaking away from the conventional paradigm of incrementally discovering skills from predefined start or goal states--a limitation that significantly restricts exploration--MOSAIC focuses planning efforts on regions where skills are inherently effective. We demonstrate the efficacy of MOSAIC in both simulated and real-world robotic manipulation tasks, showcasing its ability to solve complex long-horizon planning problems using a diverse set of skills incorporating generative diffusion models, motion planning algorithms, and manipulation-specific models. Visit https://skill-mosaic.github.io for demonstrations and examples.
Anytime Single-Step MAPF Planning with Anytime PIBT
Apr 10, 2025PIBT is a popular Multi-Agent Path Finding (MAPF) method at the core of many state-of-the-art MAPF methods including LaCAM, CS-PIBT, and WPPL. The main utility of PIBT is that it is a very fast and effective single-step MAPF solver and can return a collision-free single-step solution for hundreds of agents in less than a millisecond. However, the main drawback of PIBT is that it is extremely greedy in respect to its priorities and thus leads to poor solution quality. Additionally, PIBT cannot use all the planning time that might be available to it and returns the first solution it finds. We thus develop Anytime PIBT, which quickly finds a one-step solution identically to PIBT but then continuously improves the solution in an anytime manner. We prove that Anytime PIBT converges to the optimal solution given sufficient time. We experimentally validate that Anytime PIBT can rapidly improve single-step solution quality within milliseconds and even find the optimal single-step action. However, we interestingly find that improving the single-step solution quality does not have a significant effect on full-horizon solution costs.
Real-Time LaCAM
Apr 08, 2025The vast majority of Multi-Agent Path Finding (MAPF) methods with completeness guarantees require planning full horizon paths. However, planning full horizon paths can take too long and be impractical in real-world applications. Instead, real-time planning and execution, which only allows the planner a finite amount of time before executing and replanning, is more practical for real world multi-agent systems. Several methods utilize real-time planning schemes but none are provably complete, which leads to livelock or deadlock. Our main contribution is to show the first Real-Time MAPF method with provable completeness guarantees. We do this by leveraging LaCAM (Okumura 2023) in an incremental fashion. Our results show how we can iteratively plan for congested environments with a cutoff time of milliseconds while still maintaining the same success rate as full horizon LaCAM. We also show how it can be used with a single-step learned MAPF policy. The proposed Real-Time LaCAM also provides us with a general mechanism for using iterative constraints for completeness in future real-time MAPF algorithms.
RecoveryChaining: Learning Local Recovery Policies for Robust Manipulation
Oct 17, 2024



Model-based planners and controllers are commonly used to solve complex manipulation problems as they can efficiently optimize diverse objectives and generalize to long horizon tasks. However, they are limited by the fidelity of their model which oftentimes leads to failures during deployment. To enable a robot to recover from such failures, we propose to use hierarchical reinforcement learning to learn a separate recovery policy. The recovery policy is triggered when a failure is detected based on sensory observations and seeks to take the robot to a state from which it can complete the task using the nominal model-based controllers. Our approach, called RecoveryChaining, uses a hybrid action space, where the model-based controllers are provided as additional \emph{nominal} options which allows the recovery policy to decide how to recover, when to switch to a nominal controller and which controller to switch to even with \emph{sparse rewards}. We evaluate our approach in three multi-step manipulation tasks with sparse rewards, where it learns significantly more robust recovery policies than those learned by baselines. Finally, we successfully transfer recovery policies learned in simulation to a physical robot to demonstrate the feasibility of sim-to-real transfer with our method.