 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPGuide: Steering Diffusion Policies with Performance Predictive Guidance
Mar 11, 2026Diffusion policies have shown to be very efficient at learning complex, multi-modal behaviors for robotic manipulation. However, errors in generated action sequences can compound over time which can potentially lead to failure. Some approaches mitigate this by augmenting datasets with expert demonstrations or learning predictive world models which might be computationally expensive. We introduce Performance Predictive Guidance (PPGuide), a lightweight, classifier-based framework that steers a pre-trained diffusion policy away from failure modes at inference time. PPGuide makes use of a novel self-supervised process: it uses attention-based multiple instance learning to automatically estimate which observation-action chunks from the policy's rollouts are relevant to success or failure. We then train a performance predictor on this self-labeled data. During inference, this predictor provides a real-time gradient to guide the policy toward more robust actions. We validated our proposed PPGuide across a diverse set of tasks from the Robomimic and MimicGen benchmarks, demonstrating consistent improvements in performance.
Learning global control of underactuated systems with Model-Based Reinforcement Learning
Apr 09, 2025



This short paper describes our proposed solution for the third edition of the "AI Olympics with RealAIGym" competition, held at ICRA 2025. We employed Monte-Carlo Probabilistic Inference for Learning Control (MC-PILCO), an MBRL algorithm recognized for its exceptional data efficiency across various low-dimensional robotic tasks, including cart-pole, ball \& plate, and Furuta pendulum systems. MC-PILCO optimizes a system dynamics model using interaction data, enabling policy refinement through simulation rather than direct system data optimization. This approach has proven highly effective in physical systems, offering greater data efficiency than Model-Free (MF) alternatives. Notably, MC-PILCO has previously won the first two editions of this competition, demonstrating its robustness in both simulated and real-world environments. Besides briefly reviewing the algorithm, we discuss the most critical aspects of the MC-PILCO implementation in the tasks at hand: learning a global policy for the pendubot and acrobot systems.
Reinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
User-Preference Meets Pareto-Optimality: Multi-Objective Bayesian Optimization with Local Gradient Search
Feb 10, 2025


Incorporating user preferences into multi-objective Bayesian optimization (MOBO) allows for personalization of the optimization procedure. Preferences are often abstracted in the form of an unknown utility function, estimated through pairwise comparisons of potential outcomes. However, utility-driven MOBO methods can yield solutions that are dominated by nearby solutions, as non-dominance is not enforced. Additionally, classical MOBO commonly relies on estimating the entire Pareto-front to identify the Pareto-optimal solutions, which can be expensive and ignore user preferences. Here, we present a new method, termed preference-utility-balanced MOBO (PUB-MOBO), that allows users to disambiguate between near-Pareto candidate solutions. PUB-MOBO combines utility-based MOBO with local multi-gradient descent to refine user-preferred solutions to be near-Pareto-optimal. To this end, we propose a novel preference-dominated utility function that concurrently preserves user-preferences and dominance amongst candidate solutions. A key advantage of PUB-MOBO is that the local search is restricted to a (small) region of the Pareto-front directed by user preferences, alleviating the need to estimate the entire Pareto-front. PUB-MOBO is tested on three synthetic benchmark problems: DTLZ1, DTLZ2 and DH1, as well as on three real-world problems: Vehicle Safety, Conceptual Marine Design, and Car Side Impact. PUB-MOBO consistently outperforms state-of-the-art competitors in terms of proximity to the Pareto-front and utility regret across all the problems.
FDPP: Fine-tune Diffusion Policy with Human Preference
Jan 14, 2025



Imitation learning from human demonstrations enables robots to perform complex manipulation tasks and has recently witnessed huge success. However, these techniques often struggle to adapt behavior to new preferences or changes in the environment. To address these limitations, we propose Fine-tuning Diffusion Policy with Human Preference (FDPP). FDPP learns a reward function through preference-based learning. This reward is then used to fine-tune the pre-trained policy with reinforcement learning (RL), resulting in alignment of pre-trained policy with new human preferences while still solving the original task. Our experiments across various robotic tasks and preferences demonstrate that FDPP effectively customizes policy behavior without compromising performance. Additionally, we show that incorporating Kullback-Leibler (KL) regularization during fine-tuning prevents over-fitting and helps maintain the competencies of the initial policy.
LLMPhy: Complex Physical Reasoning Using Large Language Models and World Models
Nov 12, 2024Physical reasoning is an important skill needed for robotic agents when operating in the real world. However, solving such reasoning problems often involves hypothesizing and reflecting over complex multi-body interactions under the effect of a multitude of physical forces and thus learning all such interactions poses a significant hurdle for state-of-the-art machine learning frameworks, including large language models (LLMs). To study this problem, we propose a new physical reasoning task and a dataset, dubbed TraySim. Our task involves predicting the dynamics of several objects on a tray that is given an external impact -- the domino effect of the ensued object interactions and their dynamics thus offering a challenging yet controlled setup, with the goal of reasoning being to infer the stability of the objects after the impact. To solve this complex physical reasoning task, we present LLMPhy, a zero-shot black-box optimization framework that leverages the physics knowledge and program synthesis abilities of LLMs, and synergizes these abilities with the world models built into modern physics engines. Specifically, LLMPhy uses an LLM to generate code to iteratively estimate the physical hyperparameters of the system (friction, damping, layout, etc.) via an implicit analysis-by-synthesis approach using a (non-differentiable) simulator in the loop and uses the inferred parameters to imagine the dynamics of the scene towards solving the reasoning task. To show the effectiveness of LLMPhy, we present experiments on our TraySim dataset to predict the steady-state poses of the objects. Our results show that the combination of the LLM and the physics engine leads to state-of-the-art zero-shot physical reasoning performance, while demonstrating superior convergence against standard black-box optimization methods and better estimation of the physical parameters.
RecoveryChaining: Learning Local Recovery Policies for Robust Manipulation
Oct 17, 2024



Model-based planners and controllers are commonly used to solve complex manipulation problems as they can efficiently optimize diverse objectives and generalize to long horizon tasks. However, they are limited by the fidelity of their model which oftentimes leads to failures during deployment. To enable a robot to recover from such failures, we propose to use hierarchical reinforcement learning to learn a separate recovery policy. The recovery policy is triggered when a failure is detected based on sensory observations and seeks to take the robot to a state from which it can complete the task using the nominal model-based controllers. Our approach, called RecoveryChaining, uses a hybrid action space, where the model-based controllers are provided as additional \emph{nominal} options which allows the recovery policy to decide how to recover, when to switch to a nominal controller and which controller to switch to even with \emph{sparse rewards}. We evaluate our approach in three multi-step manipulation tasks with sparse rewards, where it learns significantly more robust recovery policies than those learned by baselines. Finally, we successfully transfer recovery policies learned in simulation to a physical robot to demonstrate the feasibility of sim-to-real transfer with our method.
Open Human-Robot Collaboration using Decentralized Inverse Reinforcement Learning
Oct 02, 2024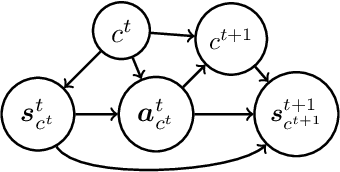
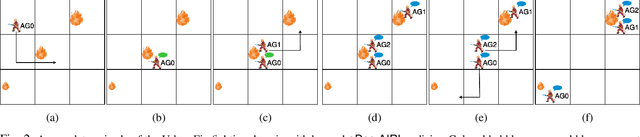


The growing interest in human-robot collaboration (HRC), where humans and robots cooperate towards shared goals, has seen significant advancements over the past decade. While previous research has addressed various challenges, several key issues remain unresolved. Many domains within HRC involve activities that do not necessarily require human presence throughout the entire task. Existing literature typically models HRC as a closed system, where all agents are present for the entire duration of the task. In contrast, an open model offers flexibility by allowing an agent to enter and exit the collaboration as needed, enabling them to concurrently manage other tasks. In this paper, we introduce a novel multiagent framework called oDec-MDP, designed specifically to model open HRC scenarios where agents can join or leave tasks flexibly during execution. We generalize a recent multiagent inverse reinforcement learning method - Dec-AIRL to learn from open systems modeled using the oDec-MDP. Our method is validated through experiments conducted in both a simplified toy firefighting domain and a realistic dyadic human-robot collaborative assembly. Results show that our framework and learning method improves upon its closed system counterpart.
Learning control of underactuated double pendulum with Model-Based Reinforcement Learning
Sep 09, 2024



This report describes our proposed solution for the second AI Olympics competition held at IROS 2024. Our solution is based on a recent Model-Based Reinforcement Learning algorithm named MC-PILCO. Besides briefly reviewing the algorithm, we discuss the most critical aspects of the MC-PILCO implementation in the tasks at hand.
DECAF: a Discrete-Event based Collaborative Human-Robot Framework for Furniture Assembly
Aug 28, 2024
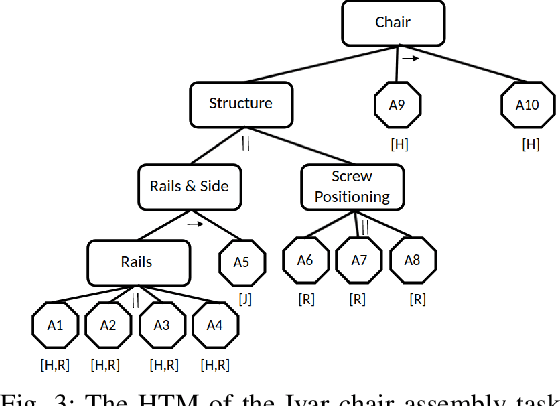
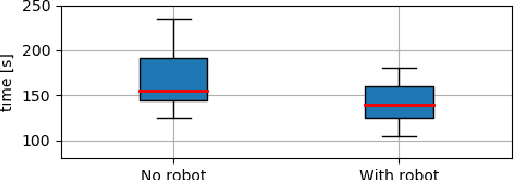
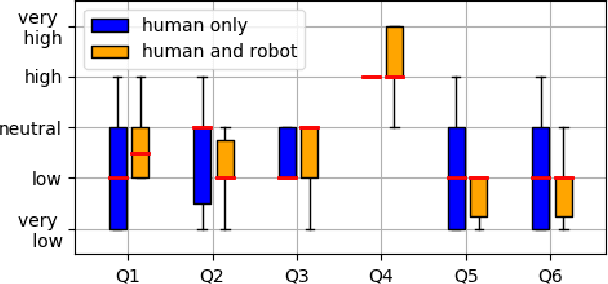
This paper proposes a task planning framework for collaborative Human-Robot scenarios, specifically focused on assembling complex systems such as furniture. The human is characterized as an uncontrollable agent, implying for example that the agent is not bound by a pre-established sequence of actions and instead acts according to its own preferences. Meanwhile, the task planner computes reactively the optimal actions for the collaborative robot to efficiently complete the entire assembly task in the least time possible. We formalize the problem as a Discrete Event Markov Decision Problem (DE-MDP), a comprehensive framework that incorporates a variety of asynchronous behaviors, human change of mind and failure recovery as stochastic events. Although the problem could theoretically be addressed by constructing a graph of all possible actions, such an approach would be constrained by computational limitations. The proposed formulation offers an alternative solution utilizing Reinforcement Learning to derive an optimal policy for the robot. Experiments where conducted both in simulation and on a real system with human subjects assembling a chair in collaboration with a 7-DoF manipulator.