 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Extrinsic Contact and In-Hand Pose Estimation via Distributed Tactile Sensing
Dec 29, 2025Prehensile autonomous manipulation, such as peg insertion, tool use, or assembly, require precise in-hand understanding of the object pose and the extrinsic contacts made during interactions. Providing accurate estimation of pose and contacts is challenging. Tactile sensors can provide local geometry at the sensor and force information about the grasp, but the locality of sensing means resolving poses and contacts from tactile alone is often an ill-posed problem, as multiple configurations can be consistent with the observations. Adding visual feedback can help resolve ambiguities, but can suffer from noise and occlusions. In this work, we propose a method that pairs local observations from sensing with the physical constraints of contact. We propose a set of factors that ensure local consistency with tactile observations as well as enforcing physical plausibility, namely, that the estimated pose and contacts must respect the kinematic and force constraints of quasi-static rigid body interactions. We formalize our problem as a factor graph, allowing for efficient estimation. In our experiments, we demonstrate that our method outperforms existing geometric and contact-informed estimation pipelines, especially when only tactile information is available. Video results can be found at https://tacgraph.github.io/.
Analytic Conditions for Differentiable Collision Detection in Trajectory Optimization
Sep 30, 2025Optimization-based methods are widely used for computing fast, diverse solutions for complex tasks such as collision-free movement or planning in the presence of contacts. However, most of these methods require enforcing non-penetration constraints between objects, resulting in a non-trivial and computationally expensive problem. This makes the use of optimization-based methods for planning and control challenging. In this paper, we present a method to efficiently enforce non-penetration of sets while performing optimization over their configuration, which is directly applicable to problems like collision-aware trajectory optimization. We introduce novel differentiable conditions with analytic expressions to achieve this. To enforce non-collision between non-smooth bodies using these conditions, we introduce a method to approximate polytopes as smooth semi-algebraic sets. We present several numerical experiments to demonstrate the performance of the proposed method and compare the performance with other baseline methods recently proposed in the literature.
Modality Selection and Skill Segmentation via Cross-Modality Attention
Apr 20, 2025Incorporating additional sensory modalities such as tactile and audio into foundational robotic models poses significant challenges due to the curse of dimensionality. This work addresses this issue through modality selection. We propose a cross-modality attention (CMA) mechanism to identify and selectively utilize the modalities that are most informative for action generation at each timestep. Furthermore, we extend the application of CMA to segment primitive skills from expert demonstrations and leverage this segmentation to train a hierarchical policy capable of solving long-horizon, contact-rich manipulation tasks.
FlowLoss: Dynamic Flow-Conditioned Loss Strategy for Video Diffusion Models
Apr 20, 2025Video Diffusion Models (VDMs) can generate high-quality videos, but often struggle with producing temporally coherent motion. Optical flow supervision is a promising approach to address this, with prior works commonly employing warping-based strategies that avoid explicit flow matching. In this work, we explore an alternative formulation, FlowLoss, which directly compares flow fields extracted from generated and ground-truth videos. To account for the unreliability of flow estimation under high-noise conditions in diffusion, we propose a noise-aware weighting scheme that modulates the flow loss across denoising steps. Experiments on robotic video datasets suggest that FlowLoss improves motion stability and accelerates convergence in early training stages. Our findings offer practical insights for incorporating motion-based supervision into noise-conditioned generative models.
Zero-Shot Peg Insertion: Identifying Mating Holes and Estimating SE(2) Poses with Vision-Language Models
Mar 08, 2025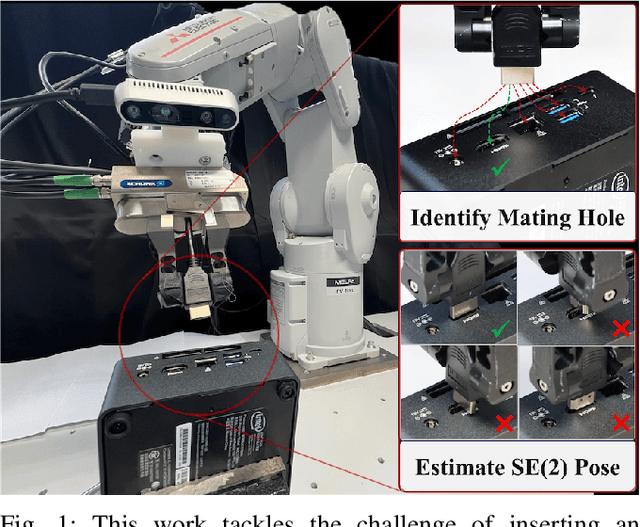
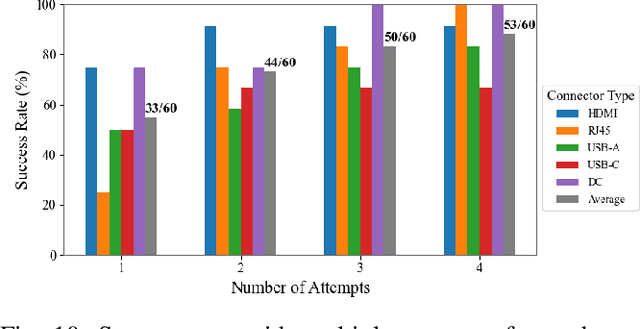
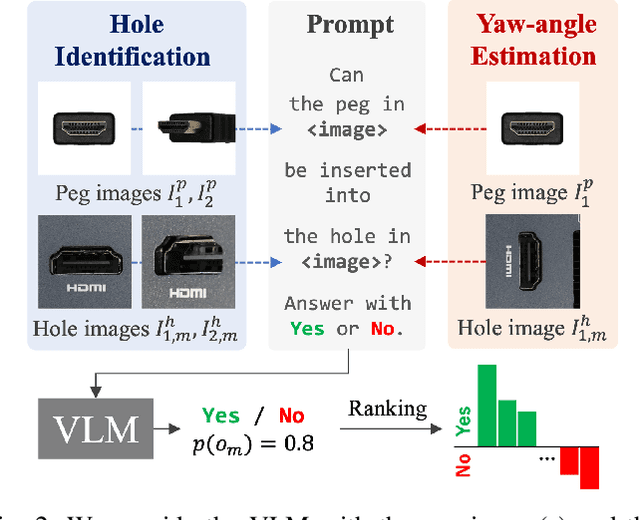
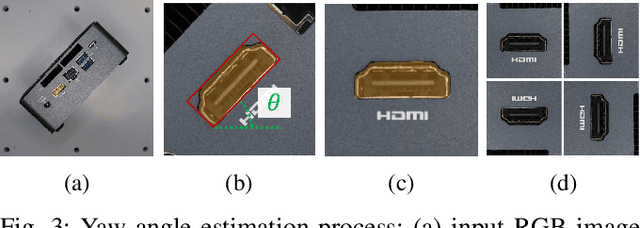
Achieving zero-shot peg insertion, where inserting an arbitrary peg into an unseen hole without task-specific training, remains a fundamental challenge in robotics. This task demands a highly generalizable perception system capable of detecting potential holes, selecting the correct mating hole from multiple candidates, estimating its precise pose, and executing insertion despite uncertainties. While learning-based methods have been applied to peg insertion, they often fail to generalize beyond the specific peg-hole pairs encountered during training. Recent advancements in Vision-Language Models (VLMs) offer a promising alternative, leveraging large-scale datasets to enable robust generalization across diverse tasks. Inspired by their success, we introduce a novel zero-shot peg insertion framework that utilizes a VLM to identify mating holes and estimate their poses without prior knowledge of their geometry. Extensive experiments demonstrate that our method achieves 90.2% accuracy, significantly outperforming baselines in identifying the correct mating hole across a wide range of previously unseen peg-hole pairs, including 3D-printed objects, toy puzzles, and industrial connectors. Furthermore, we validate the effectiveness of our approach in a real-world connector insertion task on a backpanel of a PC, where our system successfully detects holes, identifies the correct mating hole, estimates its pose, and completes the insertion with a success rate of 88.3%. These results highlight the potential of VLM-driven zero-shot reasoning for enabling robust and generalizable robotic assembly.
Autonomous Robotic Assembly: From Part Singulation to Precise Assembly
Jun 11, 2024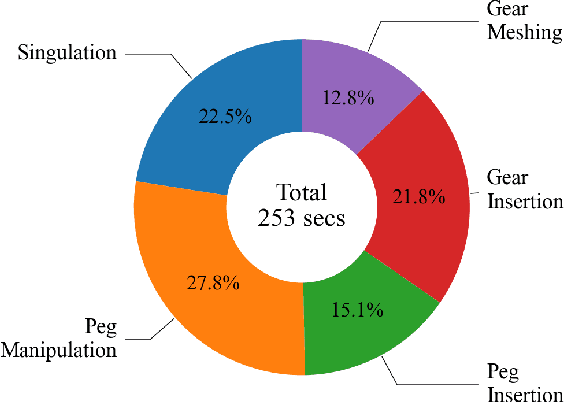
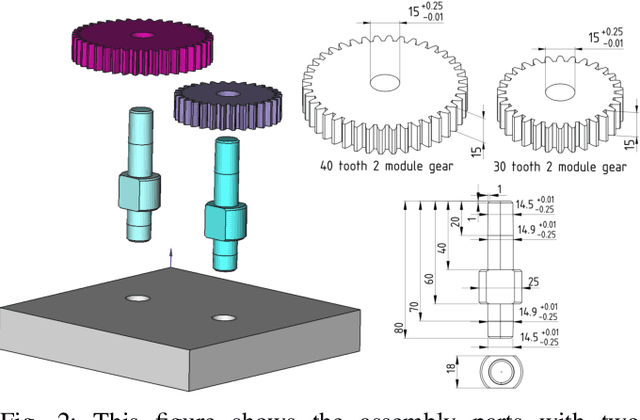


Imagine a robot that can assemble a functional product from the individual parts presented in any configuration to the robot. Designing such a robotic system is a complex problem which presents several open challenges. To bypass these challenges, the current generation of assembly systems is built with a lot of system integration effort to provide the structure and precision necessary for assembly. These systems are mostly responsible for part singulation, part kitting, and part detection, which is accomplished by intelligent system design. In this paper, we present autonomous assembly of a gear box with minimum requirements on structure. The assembly parts are randomly placed in a two-dimensional work environment for the robot. The proposed system makes use of several different manipulation skills such as sliding for grasping, in-hand manipulation, and insertion to assemble the gear box. All these tasks are run in a closed-loop fashion using vision, tactile, and Force-Torque (F/T) sensors. We perform extensive hardware experiments to show the robustness of the proposed methods as well as the overall system. See supplementary video at https://www.youtube.com/watch?v=cZ9M1DQ23OI.
Robust In-Hand Manipulation with Extrinsic Contacts
Mar 27, 2024

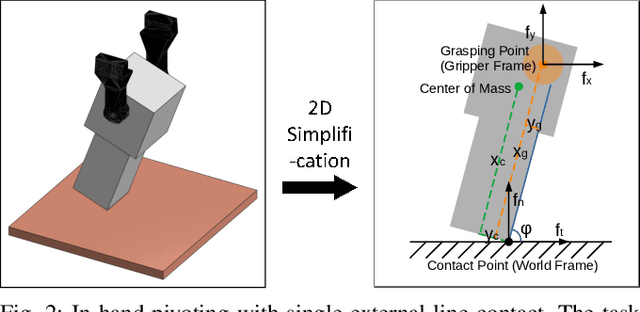
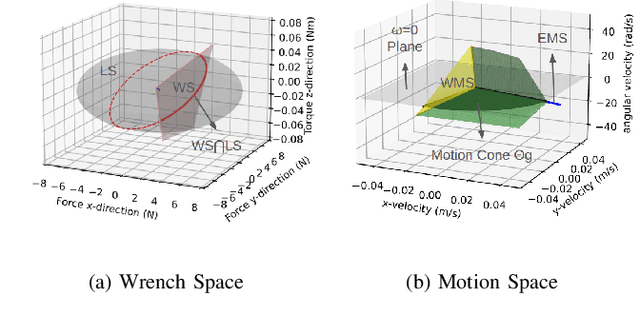
We present in-hand manipulation tasks where a robot moves an object in grasp, maintains its external contact mode with the environment, and adjusts its in-hand pose simultaneously. The proposed manipulation task leads to complex contact interactions which can be very susceptible to uncertainties in kinematic and physical parameters. Therefore, we propose a robust in-hand manipulation method, which consists of two parts. First, an in-gripper mechanics model that computes a na\"ive motion cone assuming all parameters are precise. Then, a robust planning method refines the motion cone to maintain desired contact mode regardless of parametric errors. Real-world experiments were conducted to illustrate the accuracy of the mechanics model and the effectiveness of the robust planning framework in the presence of kinematics parameter errors.
Tactile Estimation of Extrinsic Contact Patch for Stable Placement
Sep 25, 2023Precise perception of contact interactions is essential for the fine-grained manipulation skills for robots. In this paper, we present the design of feedback skills for robots that must learn to stack complex-shaped objects on top of each other. To design such a system, a robot should be able to reason about the stability of placement from very gentle contact interactions. Our results demonstrate that it is possible to infer the stability of object placement based on tactile readings during contact formation between the object and its environment. In particular, we estimate the contact patch between a grasped object and its environment using force and tactile observations to estimate the stability of the object during a contact formation. The contact patch could be used to estimate the stability of the object upon the release of the grasp. The proposed method is demonstrated on various pairs of objects that are used in a very popular board game.
Style-transfer based Speech and Audio-visual Scene Understanding for Robot Action Sequence Acquisition from Videos
Jun 27, 2023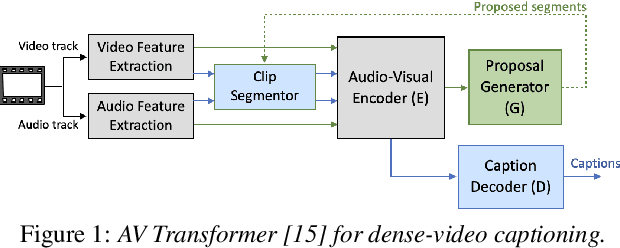

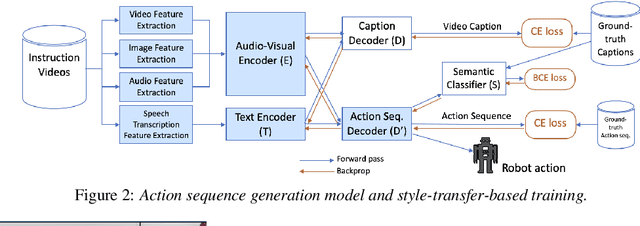
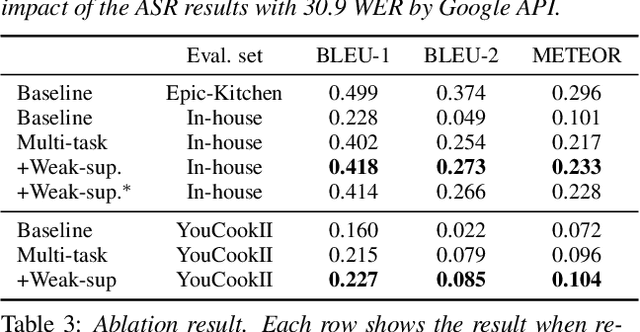
To realize human-robot collaboration, robots need to execute actions for new tasks according to human instructions given finite prior knowledge. Human experts can share their knowledge of how to perform a task with a robot through multi-modal instructions in their demonstrations, showing a sequence of short-horizon steps to achieve a long-horizon goal. This paper introduces a method for robot action sequence generation from instruction videos using (1) an audio-visual Transformer that converts audio-visual features and instruction speech to a sequence of robot actions called dynamic movement primitives (DMPs) and (2) style-transfer-based training that employs multi-task learning with video captioning and weakly-supervised learning with a semantic classifier to exploit unpaired video-action data. We built a system that accomplishes various cooking actions, where an arm robot executes a DMP sequence acquired from a cooking video using the audio-visual Transformer. Experiments with Epic-Kitchen-100, YouCookII, QuerYD, and in-house instruction video datasets show that the proposed method improves the quality of DMP sequences by 2.3 times the METEOR score obtained with a baseline video-to-action Transformer. The model achieved 32% of the task success rate with the task knowledge of the object.
Tactile-Filter: Interactive Tactile Perception for Part Mating
Mar 10, 2023Humans rely on touch and tactile sensing for a lot of dexterous manipulation tasks. Our tactile sensing provides us with a lot of information regarding contact formations as well as geometric information about objects during any interaction. With this motivation, vision-based tactile sensors are being widely used for various robotic perception and control tasks. In this paper, we present a method for interactive perception using vision-based tactile sensors for multi-object assembly. In particular, we are interested in tactile perception during part mating, where a robot can use tactile sensors and a feedback mechanism using particle filter to incrementally improve its estimate of objects that fit together for assembly. To do this, we first train a deep neural network that makes use of tactile images to predict the probabilistic correspondence between arbitrarily shaped objects that fit together. The trained model is used to design a particle filter which is used twofold. First, given one partial (or non-unique) observation of the hole, it incrementally improves the estimate of the correct peg by sampling more tactile observations. Second, it selects the next action for the robot to sample the next touch (and thus image) which results in maximum uncertainty reduction to minimize the number of interactions during the perception task. We evaluate our method on several part-mating tasks for assembly using a robot equipped with a vision-based tactile sensor. We also show the efficiency of the proposed action selection method against a naive method. See supplementary video at https://www.youtube.com/watch?v=jMVBg_e3gLw .