 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions
Oct 22, 2022



The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn't work. We enable these capabilities in autonomous agents by proposing "Hypothesize, Simulate, Act, Update, and Repeat" (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations, captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
InSeGAN: A Generative Approach to Segmenting Identical Instances in Depth Images
Aug 31, 2021
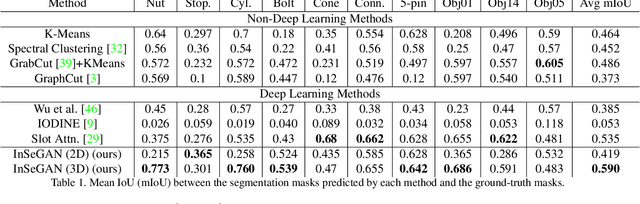
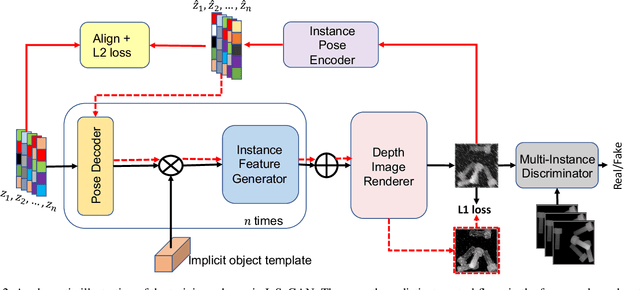
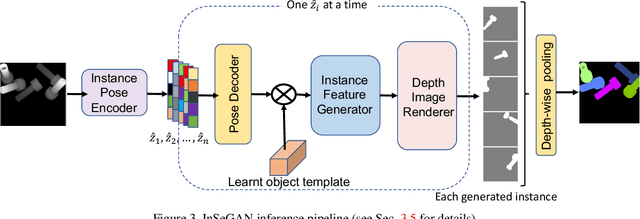
In this paper, we present InSeGAN, an unsupervised 3D generative adversarial network (GAN) for segmenting (nearly) identical instances of rigid objects in depth images. Using an analysis-by-synthesis approach, we design a novel GAN architecture to synthesize a multiple-instance depth image with independent control over each instance. InSeGAN takes in a set of code vectors (e.g., random noise vectors), each encoding the 3D pose of an object that is represented by a learned implicit object template. The generator has two distinct modules. The first module, the instance feature generator, uses each encoded pose to transform the implicit template into a feature map representation of each object instance. The second module, the depth image renderer, aggregates all of the single-instance feature maps output by the first module and generates a multiple-instance depth image. A discriminator distinguishes the generated multiple-instance depth images from the distribution of true depth images. To use our model for instance segmentation, we propose an instance pose encoder that learns to take in a generated depth image and reproduce the pose code vectors for all of the object instances. To evaluate our approach, we introduce a new synthetic dataset, "Insta-10", consisting of 100,000 depth images, each with 5 instances of an object from one of 10 classes. Our experiments on Insta-10, as well as on real-world noisy depth images, show that InSeGAN achieves state-of-the-art performance, often outperforming prior methods by large margins.
Towards Human-Level Learning of Complex Physical Puzzles
Nov 14, 2020
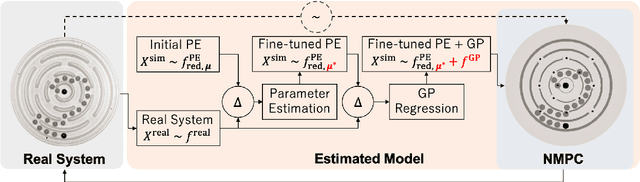
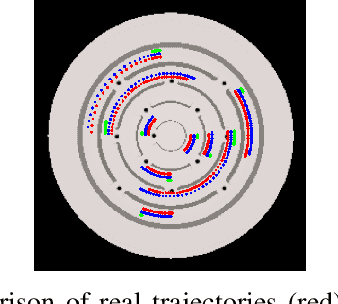
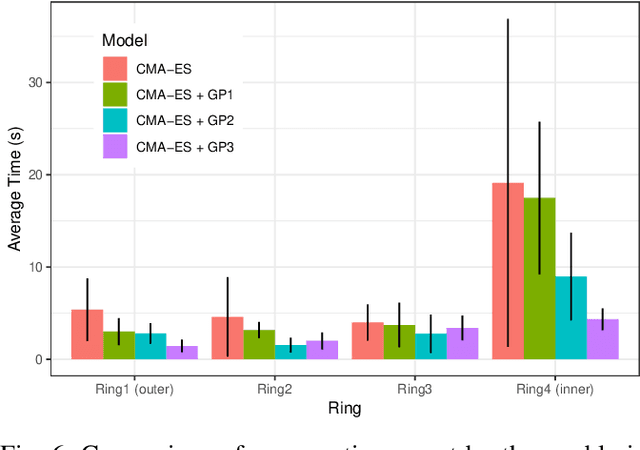
Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine equipped with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. We contrast the learning behavior against the time taken by humans to solve the problem to show comparable behavior. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC). Codes for the simulation environment can be downloaded here https://www.merl.com/research/license/CME . A video describing our method could be found here https://youtu.be/xaxNCXBovpc .
Towards Learning Affine-Invariant Representations via Data-Efficient CNNs
Aug 31, 2019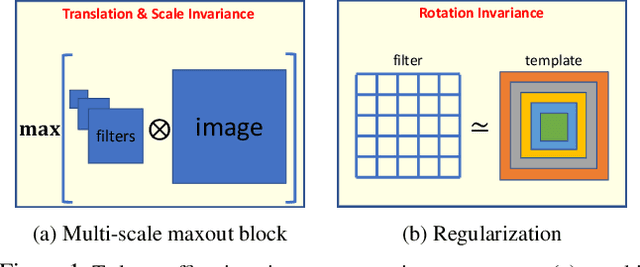
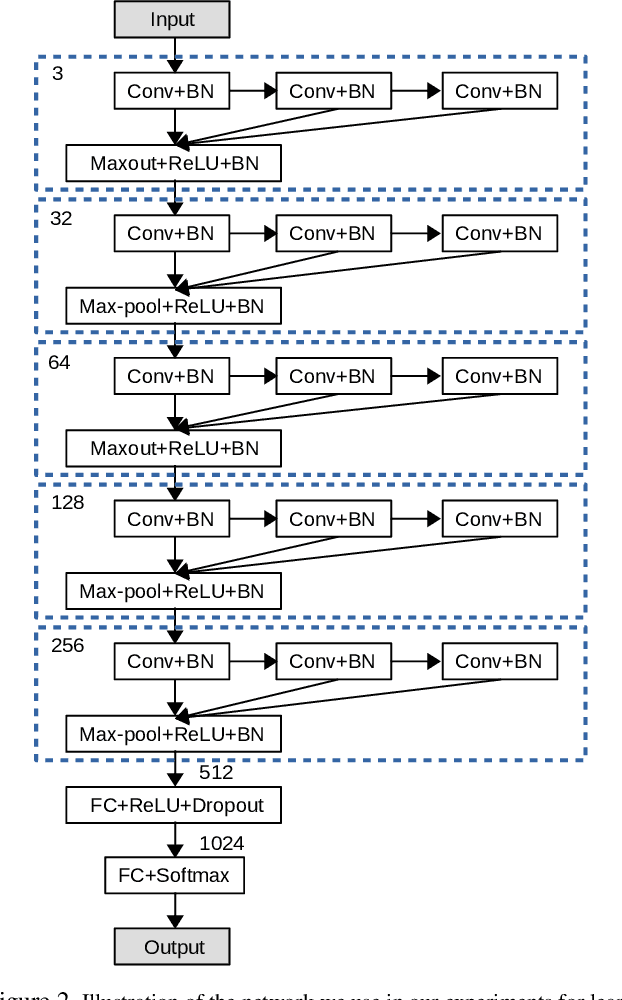
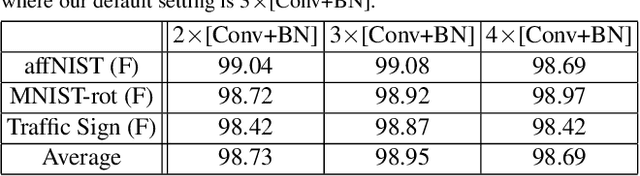

In this paper we propose integrating a priori knowledge into both design and training of convolutional neural networks (CNNs) to learn object representations that are invariant to affine transformations (i.e., translation, scale, rotation). Accordingly we propose a novel multi-scale maxout CNN and train it end-to-end with a novel rotation-invariant regularizer. This regularizer aims to enforce the weights in each 2D spatial filter to approximate circular patterns. In this way, we manage to handle affine transformations in training using convolution, multi-scale maxout, and circular filters. Empirically we demonstrate that such knowledge can significantly improve the data-efficiency as well as generalization and robustness of learned models. For instance, on the Traffic Sign data set and trained with only 10 images per class, our method can achieve 84.15% that outperforms the state-of-the-art by 29.80% in terms of test accuracy.
Verification of Very Low-Resolution Faces Using An Identity-Preserving Deep Face Super-Resolution Network
Mar 26, 2019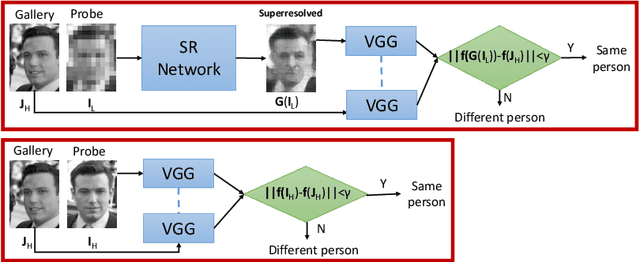
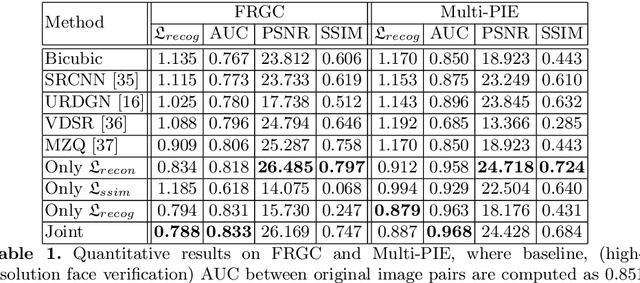
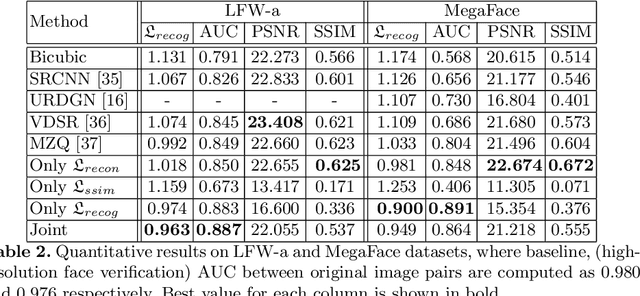
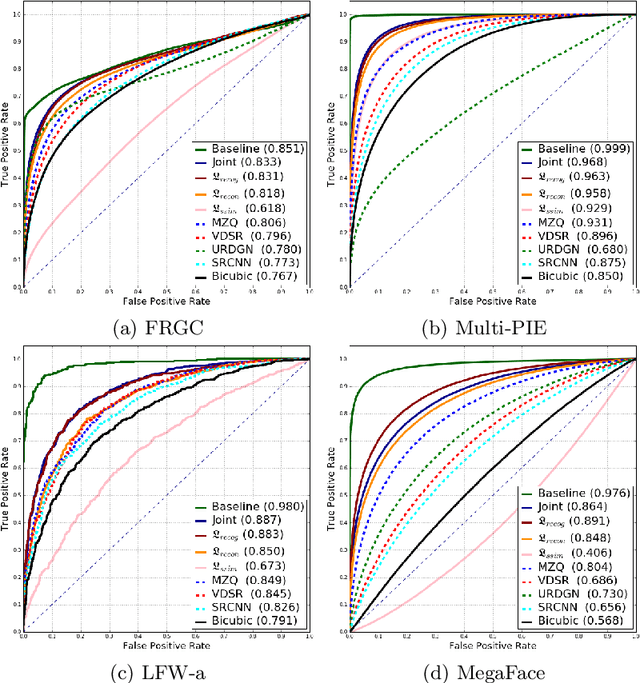
Face super-resolution methods usually aim at producing visually appealing results rather than preserving distinctive features for further face identification. In this work, we propose a deep learning method for face verification on very low-resolution face images that involves identity-preserving face super-resolution. Our framework includes a super-resolution network and a feature extraction network. We train a VGG-based deep face recognition network (Parkhi et al. 2015) to be used as feature extractor. Our super-resolution network is trained to minimize the feature distance between the high resolution ground truth image and the super-resolved image, where features are extracted using our pre-trained feature extraction network. We carry out experiments on FRGC, Multi-PIE, LFW-a, and MegaFace datasets to evaluate our method in controlled and uncontrolled settings. The results show that the presented method outperforms conventional super-resolution methods in low-resolution face verification.
Time-Delay Momentum: A Regularization Perspective on the Convergence and Generalization of Stochastic Momentum for Deep Learning
Mar 02, 2019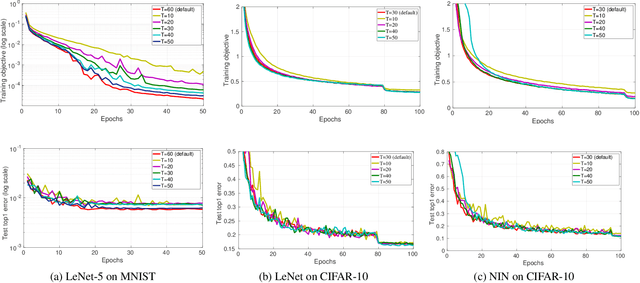
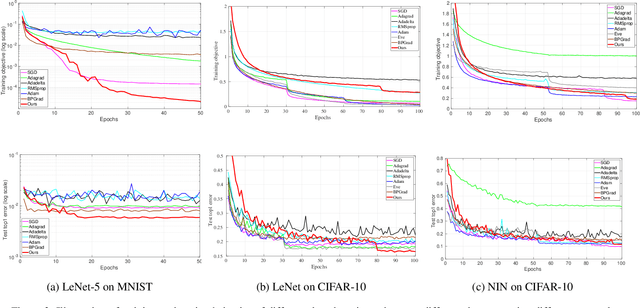
In this paper we study the problem of convergence and generalization error bound of stochastic momentum for deep learning from the perspective of regularization. To do so, we first interpret momentum as solving an $\ell_2$-regularized minimization problem to learn the offsets between arbitrary two successive model parameters. We call this {\em time-delay momentum} because the model parameter is updated after a few iterations towards finding the minimizer. We then propose our learning algorithm, \ie stochastic gradient descent (SGD) with time-delay momentum. We show that our algorithm can be interpreted as solving a sequence of strongly convex optimization problems using SGD. We prove that under mild conditions our algorithm can converge to a stationary point with rate of $O(\frac{1}{\sqrt{K}})$ and generalization error bound of $O(\frac{1}{\sqrt{n\delta}})$ with probability at least $1-\delta$, where $K,n$ are the numbers of model updates and training samples, respectively. We demonstrate the empirical superiority of our algorithm in deep learning in comparison with the state-of-the-art deep learning solvers.
Equilibrated Recurrent Neural Network: Neuronal Time-Delayed Self-Feedback Improves Accuracy and Stability
Mar 02, 2019
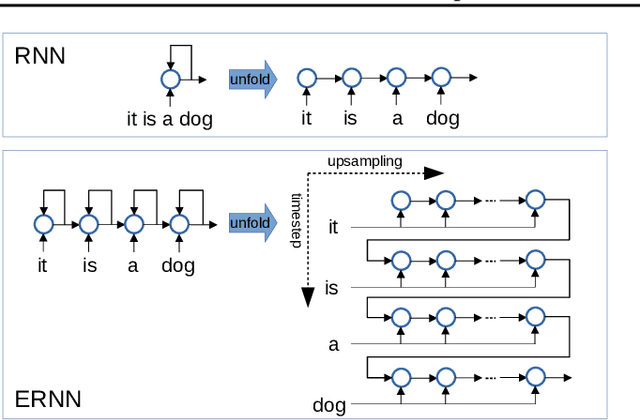
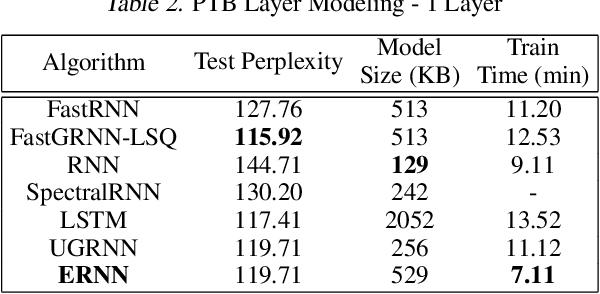
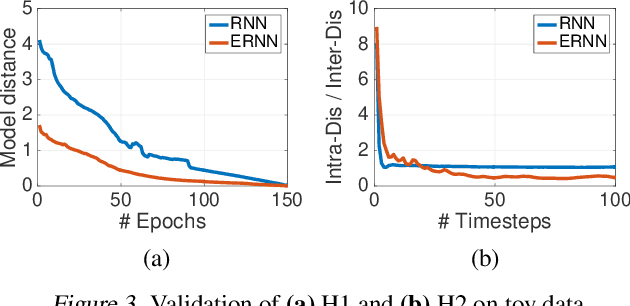
We propose a novel {\it Equilibrated Recurrent Neural Network} (ERNN) to combat the issues of inaccuracy and instability in conventional RNNs. Drawing upon the concept of autapse in neuroscience, we propose augmenting an RNN with a time-delayed self-feedback loop. Our sole purpose is to modify the dynamics of each internal RNN state and, at any time, enforce it to evolve close to the equilibrium point associated with the input signal at that time. We show that such self-feedback helps stabilize the hidden state transitions leading to fast convergence during training while efficiently learning discriminative latent features that result in state-of-the-art results on several benchmark datasets at test-time. We propose a novel inexact Newton method to solve fixed-point conditions given model parameters for generating the latent features at each hidden state. We prove that our inexact Newton method converges locally with linear rate (under mild conditions). We leverage this result for efficient training of ERNNs based on backpropagation.
Sim-to-Real Transfer Learning using Robustified Controllers in Robotic Tasks involving Complex Dynamics
Sep 17, 2018
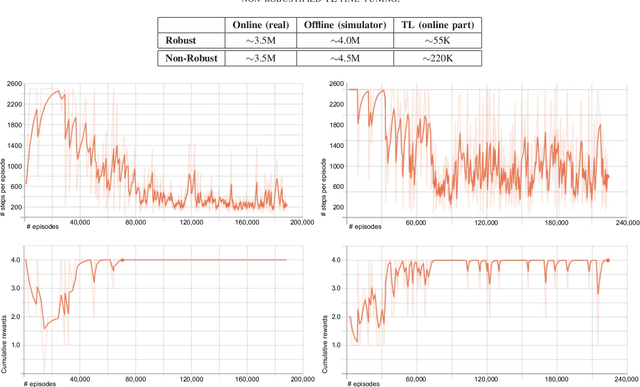
Learning robot tasks or controllers using deep reinforcement learning has been proven effective in simulations. Learning in simulation has several advantages. For example, one can fully control the simulated environment, including halting motions while performing computations. Another advantage when robots are involved, is that the amount of time a robot is occupied learning a task---rather than being productive---can be reduced by transferring the learned task to the real robot. Transfer learning requires some amount of fine-tuning on the real robot. For tasks which involve complex (non-linear) dynamics, the fine-tuning itself may take a substantial amount of time. In order to reduce the amount of fine-tuning we propose to learn robustified controllers in simulation. Robustified controllers are learned by exploiting the ability to change simulation parameters (both appearance and dynamics) for successive training episodes. An additional benefit for this approach is that it alleviates the precise determination of physics parameters for the simulator, which is a non-trivial task. We demonstrate our proposed approach on a real setup in which a robot aims to solve a maze game, which involves complex dynamics due to static friction and potentially large accelerations. We show that the amount of fine-tuning in transfer learning for a robustified controller is substantially reduced compared to a non-robustified controller.
Sem-GAN: Semantically-Consistent Image-to-Image Translation
Jul 12, 2018
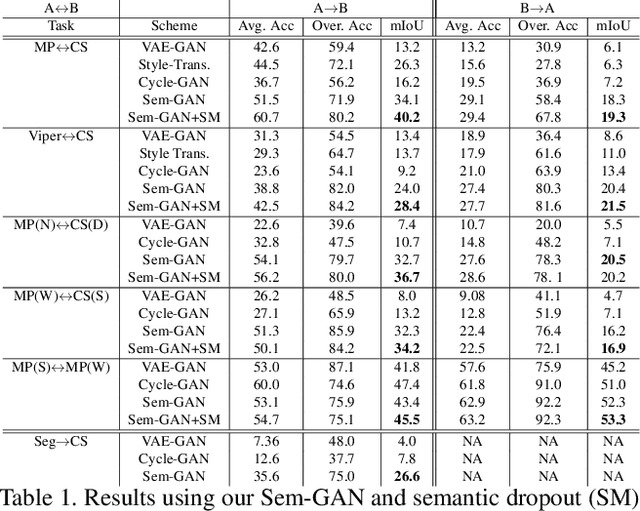
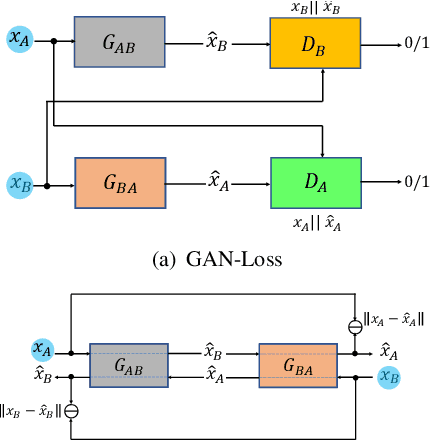
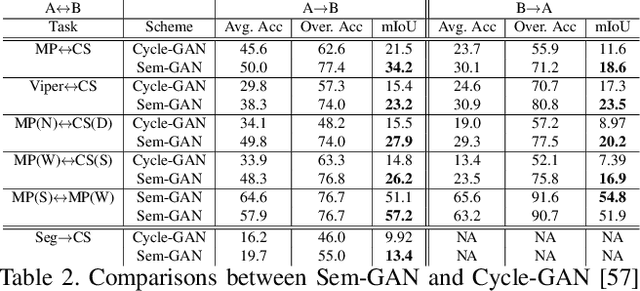
Unpaired image-to-image translation is the problem of mapping an image in the source domain to one in the target domain, without requiring corresponding image pairs. To ensure the translated images are realistically plausible, recent works, such as Cycle-GAN, demands this mapping to be invertible. While, this requirement demonstrates promising results when the domains are unimodal, its performance is unpredictable in a multi-modal scenario such as in an image segmentation task. This is because, invertibility does not necessarily enforce semantic correctness. To this end, we present a semantically-consistent GAN framework, dubbed Sem-GAN, in which the semantics are defined by the class identities of image segments in the source domain as produced by a semantic segmentation algorithm. Our proposed framework includes consistency constraints on the translation task that, together with the GAN loss and the cycle-constraints, enforces that the images when translated will inherit the appearances of the target domain, while (approximately) maintaining their identities from the source domain. We present experiments on several image-to-image translation tasks and demonstrate that Sem-GAN improves the quality of the translated images significantly, sometimes by more than 20% on the FCN score. Further, we show that semantic segmentation models, trained with synthetic images translated via Sem-GAN, leads to significantly better segmentation results than other variants.
Deformable Part Networks
May 22, 2018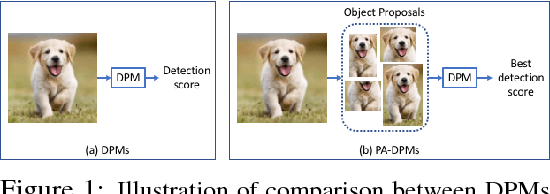
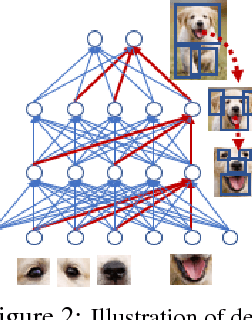
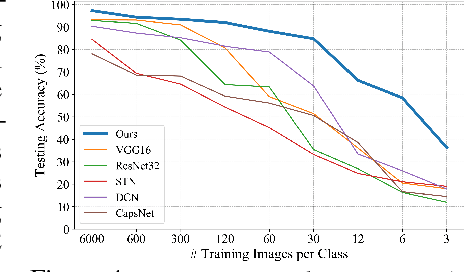
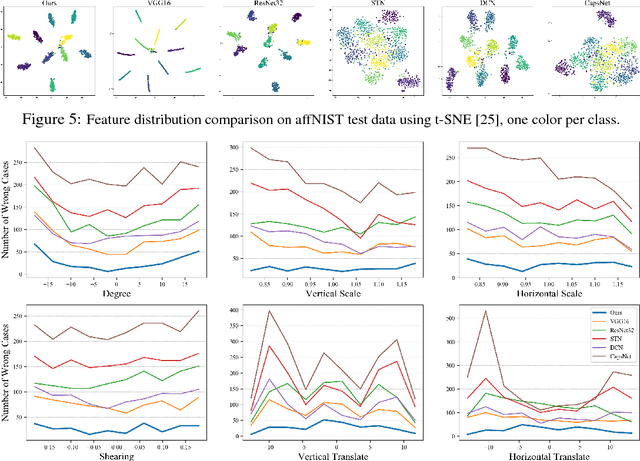
In this paper we propose novel Deformable Part Networks (DPNs) to learn {\em pose-invariant} representations for 2D object recognition. In contrast to the state-of-the-art pose-aware networks such as CapsNet \cite{sabour2017dynamic} and STN \cite{jaderberg2015spatial}, DPNs can be naturally {\em interpreted} as an efficient solver for a challenging detection problem, namely Localized Deformable Part Models (LDPMs) where localization is introduced to DPMs as another latent variable for searching for the best poses of objects over all pixels and (predefined) scales. In particular we construct DPNs as sequences of such LDPM units to model the semantic and spatial relations among the deformable parts as hierarchical composition and spatial parsing trees. Empirically our 17-layer DPN can outperform both CapsNets and STNs significantly on affNIST \cite{sabour2017dynamic}, for instance, by 19.19\% and 12.75\%, respectively, with better generalization and better tolerance to affine transformations.