 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Part Networks
Paper and Code
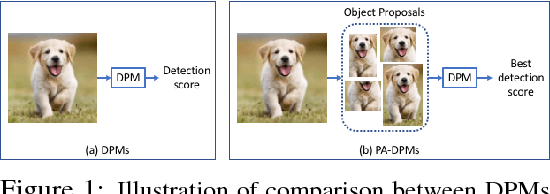
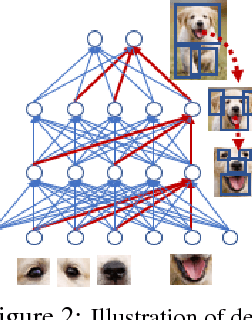
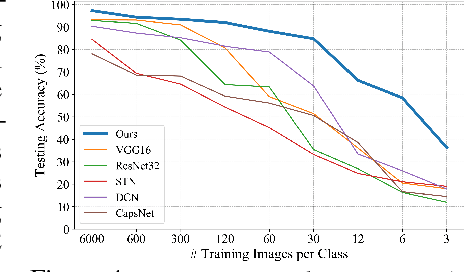
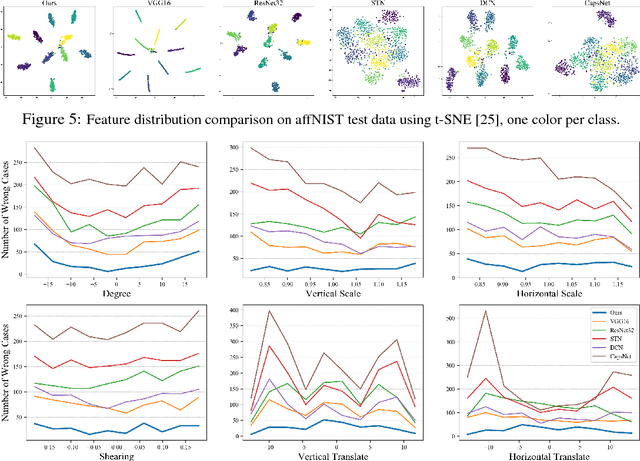
In this paper we propose novel Deformable Part Networks (DPNs) to learn {\em pose-invariant} representations for 2D object recognition. In contrast to the state-of-the-art pose-aware networks such as CapsNet \cite{sabour2017dynamic} and STN \cite{jaderberg2015spatial}, DPNs can be naturally {\em interpreted} as an efficient solver for a challenging detection problem, namely Localized Deformable Part Models (LDPMs) where localization is introduced to DPMs as another latent variable for searching for the best poses of objects over all pixels and (predefined) scales. In particular we construct DPNs as sequences of such LDPM units to model the semantic and spatial relations among the deformable parts as hierarchical composition and spatial parsing trees. Empirically our 17-layer DPN can outperform both CapsNets and STNs significantly on affNIST \cite{sabour2017dynamic}, for instance, by 19.19\% and 12.75\%, respectively, with better generalization and better tolerance to affine transformations.