 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomer-Agent: Overcoming Context Limitations in Ultra-Long Shopping Trajectories via Tool-Augmented Agents and RLVR
Jun 06, 2026Understanding customer shopping trajectories is essential for enabling personalized shopping experiences. However, shopping records (i.e., customer's search, clicks, purchases, etc.) often span long time horizons over multiple years, resulting in extremely long trajectories that pose significant challenges for existing large language models (LLMs). Despite the importance of this problem, existing benchmarks are limited to short customer trajectories, while real-world trajectories from large e-commerce platforms are rarely accessible due to data privacy constraints. To address this gap, we introduce ShopTrajQA, a long-context evaluation benchmark constructed from real-world product information and simulated shopping trajectories. The dataset includes variants of up to 32k and 64k tokens, enabling systematic evaluation of model robustness under varying context lengths. Through comprehensive benchmarking of frontier LLMs, we identify critical performance gaps in reasoning over long shopping trajectory data. To address these challenges, we propose a Customer Agent Framework for ultra-long context management. Leveraging a Reinforcement Learning with Verifiable Rewards (RLVR) agentic training paradigm, our approach stores trajectories as external local files and trains the agent to autonomously retrieve and parse them through code-interpreter interactions (e.g., SQL queries), effectively bypassing the fixed in-context window constraints of LLMs. Experimental results demonstrate that our framework achieves strong performance for ShopTrajQA and shows generalization to other complex reasoning tasks.
Stepwise Penalization for Length-Efficient Chain-of-Thought Reasoning
Feb 27, 2026Large reasoning models improve with more test-time computation, but often overthink, producing unnecessarily long chains-of-thought that raise cost without improving accuracy. Prior reinforcement learning approaches typically rely on a single outcome reward with trajectory-level length penalties, which cannot distinguish essential from redundant reasoning steps and therefore yield blunt compression. Although recent work incorporates step-level signals, such as offline pruning, supervised data construction, or verifier-based intermediate rewards, reasoning length is rarely treated as an explicit step-level optimization objective during RL. We propose Step-wise Adaptive Penalization (SWAP), a fine-grained framework that allocates length reduction across steps based on intrinsic contribution. We estimate step importance from the model's on-policy log-probability improvement toward the correct answer, then treat excess length as a penalty mass redistributed to penalize low-importance steps more heavily while preserving high-importance reasoning. We optimize with a unified outcome-process advantage within group-relative policy optimization. Extensive experiments demonstrate that SWAP reduces reasoning length by 64.3% on average while improving accuracy by 5.7% relative to the base model.
PV2TEA: Patching Visual Modality to Textual-Established Information Extraction
Jun 01, 2023

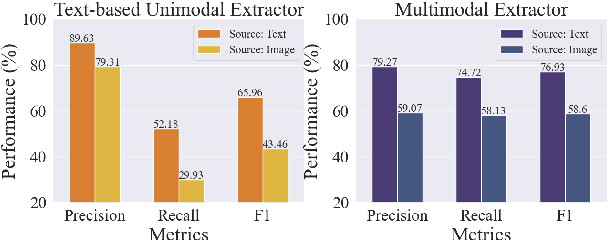
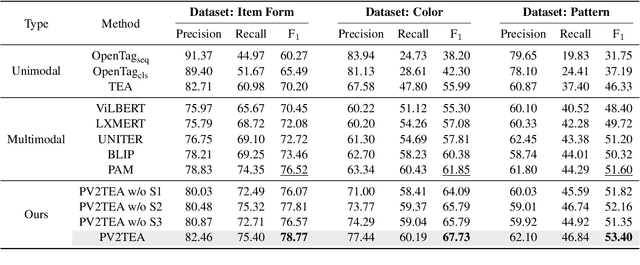
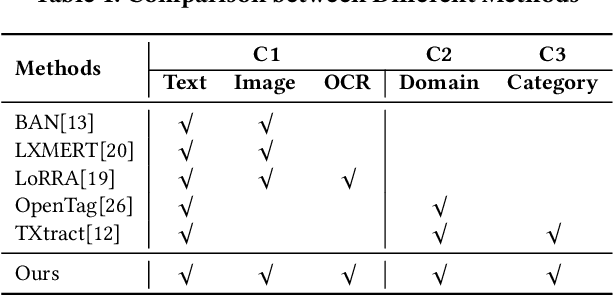
Information extraction, e.g., attribute value extraction, has been extensively studied and formulated based only on text. However, many attributes can benefit from image-based extraction, like color, shape, pattern, among others. The visual modality has long been underutilized, mainly due to multimodal annotation difficulty. In this paper, we aim to patch the visual modality to the textual-established attribute information extractor. The cross-modality integration faces several unique challenges: (C1) images and textual descriptions are loosely paired intra-sample and inter-samples; (C2) images usually contain rich backgrounds that can mislead the prediction; (C3) weakly supervised labels from textual-established extractors are biased for multimodal training. We present PV2TEA, an encoder-decoder architecture equipped with three bias reduction schemes: (S1) Augmented label-smoothed contrast to improve the cross-modality alignment for loosely-paired image and text; (S2) Attention-pruning that adaptively distinguishes the visual foreground; (S3) Two-level neighborhood regularization that mitigates the label textual bias via reliability estimation. Empirical results on real-world e-Commerce datasets demonstrate up to 11.74% absolute (20.97% relatively) F1 increase over unimodal baselines.
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022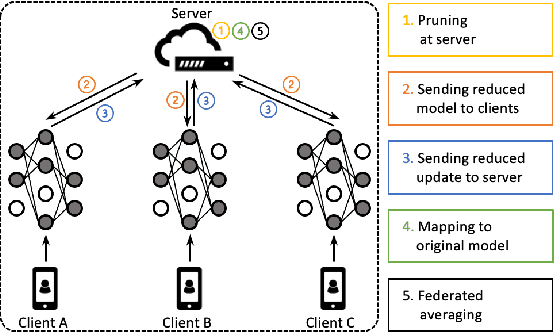
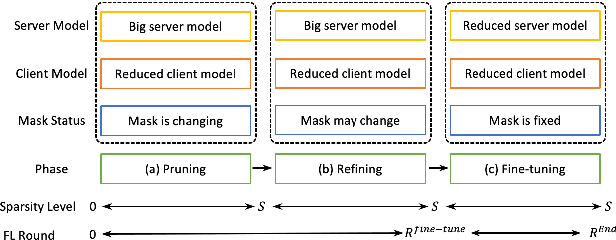
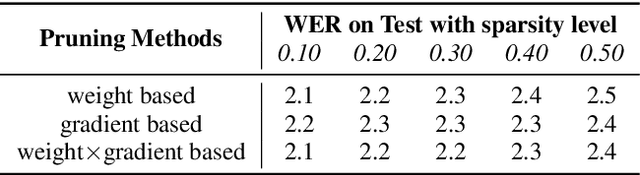
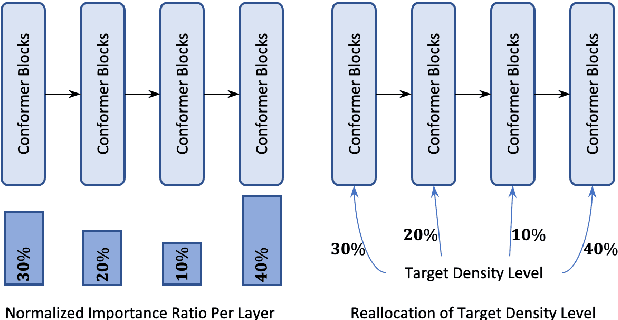
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
PAM: Understanding Product Images in Cross Product Category Attribute Extraction
Jun 08, 2021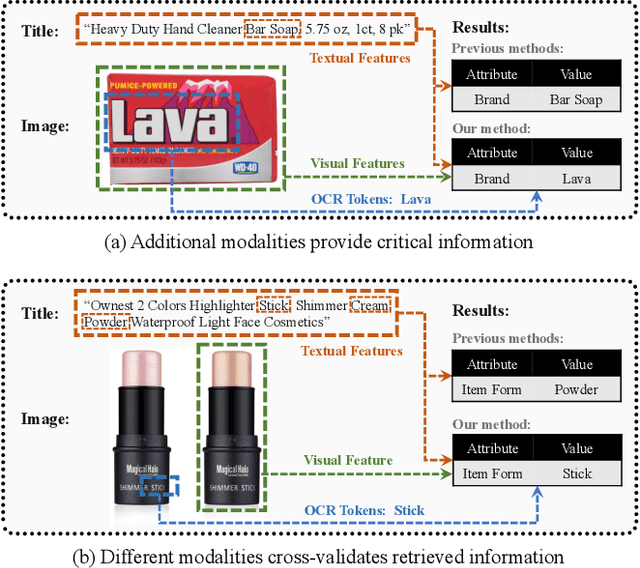

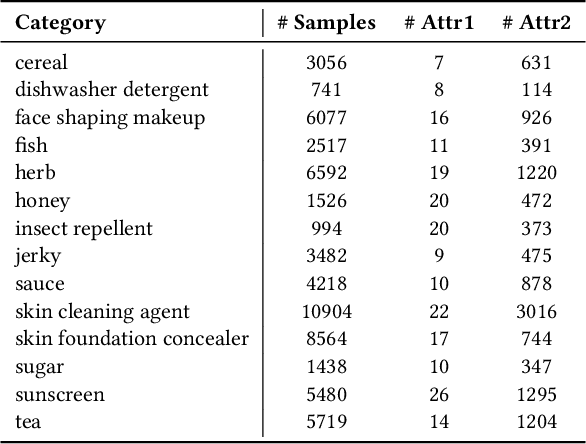
Understanding product attributes plays an important role in improving online shopping experience for customers and serves as an integral part for constructing a product knowledge graph. Most existing methods focus on attribute extraction from text description or utilize visual information from product images such as shape and color. Compared to the inputs considered in prior works, a product image in fact contains more information, represented by a rich mixture of words and visual clues with a layout carefully designed to impress customers. This work proposes a more inclusive framework that fully utilizes these different modalities for attribute extraction. Inspired by recent works in visual question answering, we use a transformer based sequence to sequence model to fuse representations of product text, Optical Character Recognition (OCR) tokens and visual objects detected in the product image. The framework is further extended with the capability to extract attribute value across multiple product categories with a single model, by training the decoder to predict both product category and attribute value and conditioning its output on product category. The model provides a unified attribute extraction solution desirable at an e-commerce platform that offers numerous product categories with a diverse body of product attributes. We evaluated the model on two product attributes, one with many possible values and one with a small set of possible values, over 14 product categories and found the model could achieve 15% gain on the Recall and 10% gain on the F1 score compared to existing methods using text-only features.
Learning with Hyperspherical Uniformity
Mar 02, 2021

Due to the over-parameterization nature, neural networks are a powerful tool for nonlinear function approximation. In order to achieve good generalization on unseen data, a suitable inductive bias is of great importance for neural networks. One of the most straightforward ways is to regularize the neural network with some additional objectives. L2 regularization serves as a standard regularization for neural networks. Despite its popularity, it essentially regularizes one dimension of the individual neuron, which is not strong enough to control the capacity of highly over-parameterized neural networks. Motivated by this, hyperspherical uniformity is proposed as a novel family of relational regularizations that impact the interaction among neurons. We consider several geometrically distinct ways to achieve hyperspherical uniformity. The effectiveness of hyperspherical uniformity is justified by theoretical insights and empirical evaluations.
Orthogonal Over-Parameterized Training
Apr 09, 2020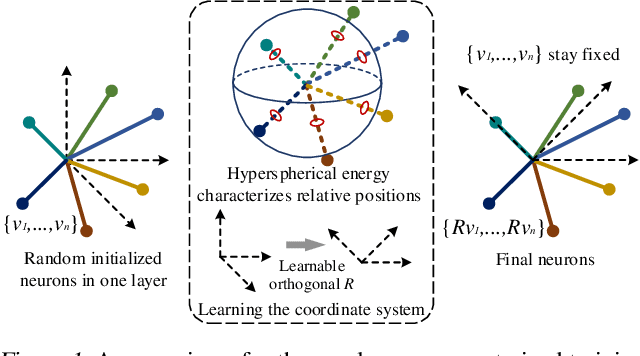

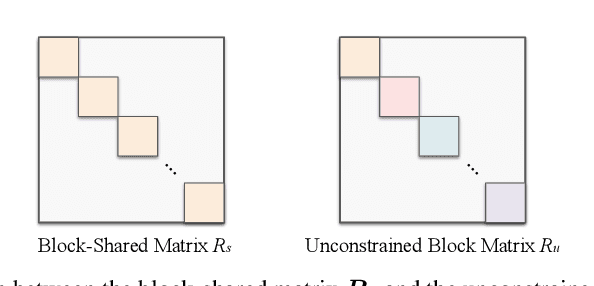
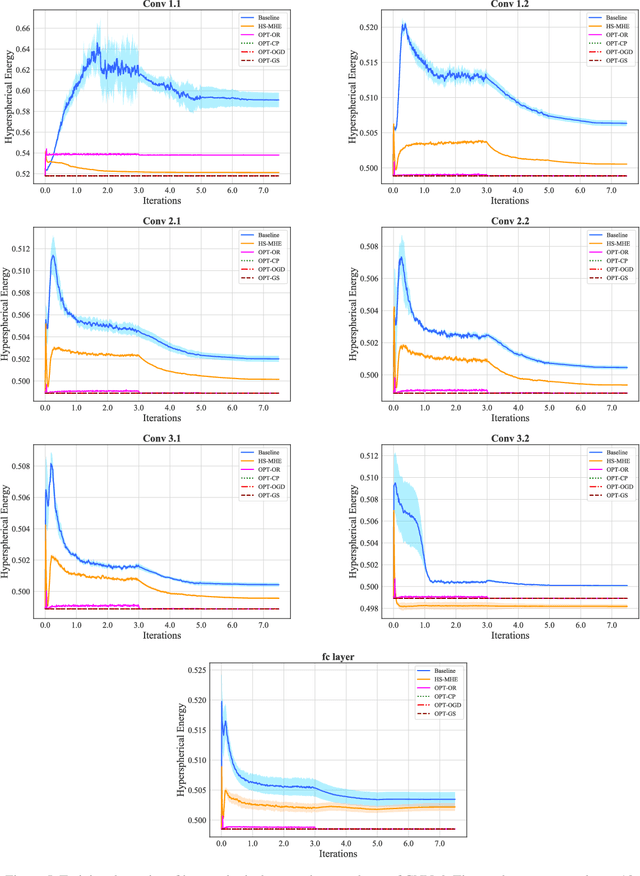
The inductive bias of a neural network is largely determined by the architecture and the training algorithm. To achieve good generalization, how to effectively train a neural network is even more important than designing the architecture. We propose a novel orthogonal over-parameterized training (OPT) framework that can provably minimize the hyperspherical energy which characterizes the diversity of neurons on a hypersphere. By constantly maintaining the minimum hyperspherical energy during training, OPT can greatly improve the network generalization. Specifically, OPT fixes the randomly initialized weights of the neurons and learns an orthogonal transformation that applies to these neurons. We propose multiple ways to learn such an orthogonal transformation, including unrolling orthogonalization algorithms, applying orthogonal parameterization, and designing orthogonality-preserving gradient update. Interestingly, OPT reveals that learning a proper coordinate system for neurons is crucial to generalization and may be more important than learning a specific relative position of neurons. We further provide theoretical insights of why OPT yields better generalization. Extensive experiments validate the superiority of OPT.
Compressive Hyperspherical Energy Minimization
Jun 12, 2019
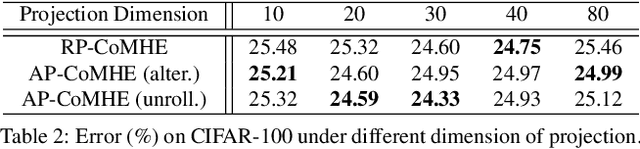
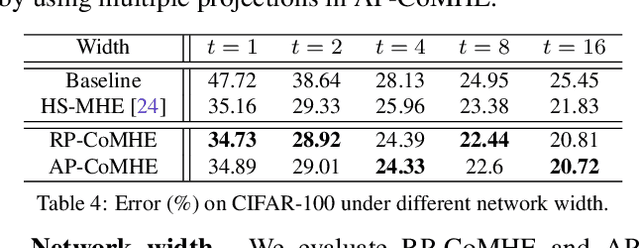
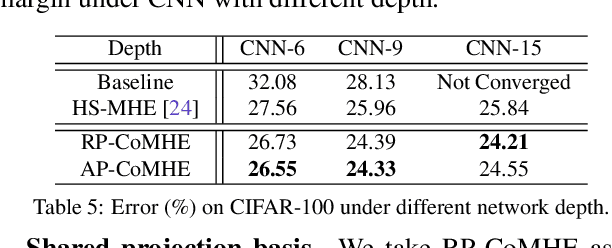
Recent work on minimum hyperspherical energy (MHE) has demonstrated its potential in regularizing neural networks and improving their generalization. MHE was inspired by the Thomson problem in physics, where the distribution of multiple propelling electrons on a unit sphere can be modeled via minimizing some potential energy. Despite the practical effectiveness, MHE suffers from local minima as their number increases dramatically in high dimensions, limiting MHE from unleashing its full potential in improving network generalization. To address this issue, we propose compressive minimum hyperspherical energy (CoMHE) as an alternative regularization for neural networks. Specifically, CoMHE utilizes a projection mapping to reduce the dimensionality of neurons and minimizes their hyperspherical energy. According to different constructions for the projection matrix, we propose two major variants: random projection CoMHE and angle-preserving CoMHE. Furthermore, we provide theoretical insights to justify its effectiveness. We show that CoMHE consistently outperforms MHE by a significant margin in comprehensive experiments, and demonstrate its diverse applications to a variety of tasks such as image recognition and point cloud recognition.
Learning towards Minimum Hyperspherical Energy
Oct 27, 2018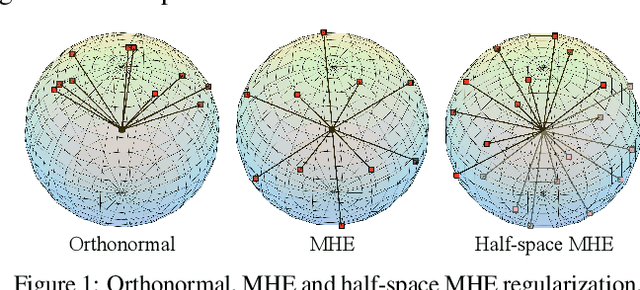
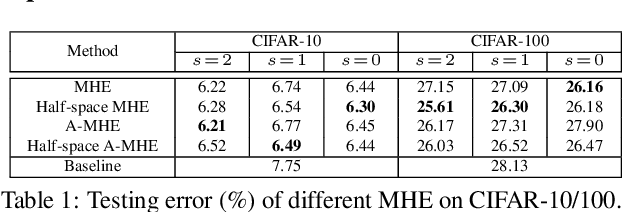
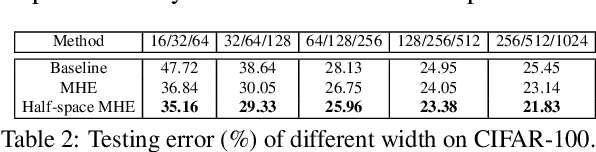
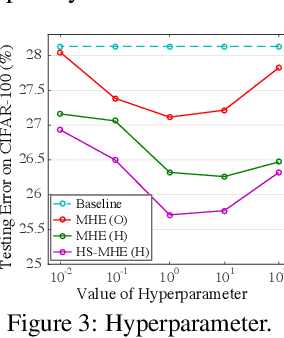
Neural networks are a powerful class of nonlinear functions that can be trained end-to-end on various applications. While the over-parametrization nature in many neural networks renders the ability to fit complex functions and the strong representation power to handle challenging tasks, it also leads to highly correlated neurons that can hurt the generalization ability and incur unnecessary computation cost. As a result, how to regularize the network to avoid undesired representation redundancy becomes an important issue. To this end, we draw inspiration from a well-known problem in physics -- Thomson problem, where one seeks to find a state that distributes N electrons on a unit sphere as evenly as possible with minimum potential energy. In light of this intuition, we reduce the redundancy regularization problem to generic energy minimization, and propose a minimum hyperspherical energy (MHE) objective as generic regularization for neural networks. We also propose a few novel variants of MHE, and provide some insights from a theoretical point of view. Finally, we apply neural networks with MHE regularization to several challenging tasks. Extensive experiments demonstrate the effectiveness of our intuition, by showing the superior performance with MHE regularization.
Deformable Part Networks
May 22, 2018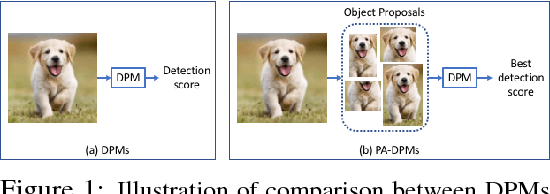
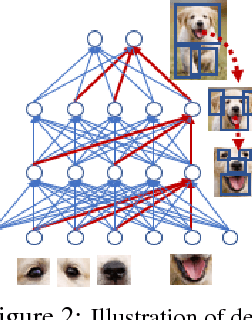
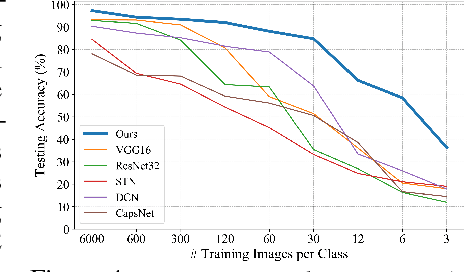
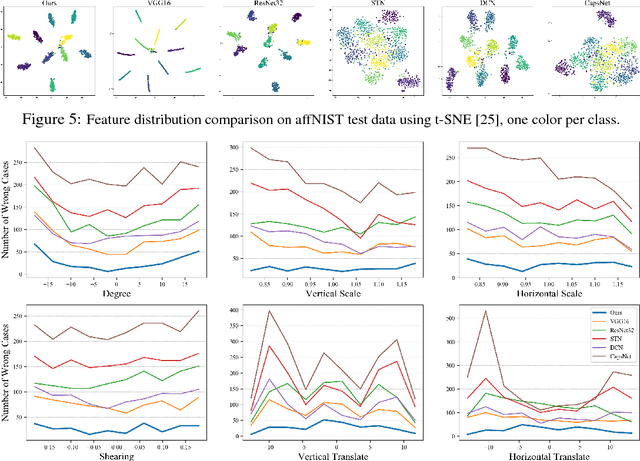
In this paper we propose novel Deformable Part Networks (DPNs) to learn {\em pose-invariant} representations for 2D object recognition. In contrast to the state-of-the-art pose-aware networks such as CapsNet \cite{sabour2017dynamic} and STN \cite{jaderberg2015spatial}, DPNs can be naturally {\em interpreted} as an efficient solver for a challenging detection problem, namely Localized Deformable Part Models (LDPMs) where localization is introduced to DPMs as another latent variable for searching for the best poses of objects over all pixels and (predefined) scales. In particular we construct DPNs as sequences of such LDPM units to model the semantic and spatial relations among the deformable parts as hierarchical composition and spatial parsing trees. Empirically our 17-layer DPN can outperform both CapsNets and STNs significantly on affNIST \cite{sabour2017dynamic}, for instance, by 19.19\% and 12.75\%, respectively, with better generalization and better tolerance to affine transformations.