 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Large ASR Models in the Real World
Aug 19, 2024Federated learning (FL) has shown promising results on training machine learning models with privacy preservation. However, for large models with over 100 million parameters, the training resource requirement becomes an obstacle for FL because common devices do not have enough memory and computation power to finish the FL tasks. Although efficient training methods have been proposed, it is still a challenge to train the large models like Conformer based ASR. This paper presents a systematic solution to train the full-size ASR models of 130M parameters with FL. To our knowledge, this is the first real-world FL application of the Conformer model, which is also the largest model ever trained with FL so far. And this is the first paper showing FL can improve the ASR model quality with a set of proposed methods to refine the quality of data and labels of clients. We demonstrate both the training efficiency and the model quality improvement in real-world experiments.
Parameter-Efficient Transfer Learning under Federated Learning for Automatic Speech Recognition
Aug 19, 2024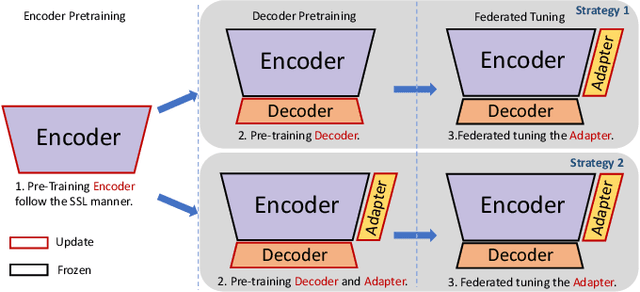
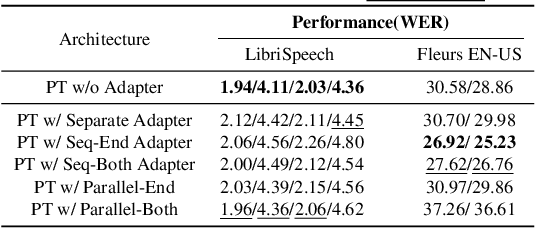
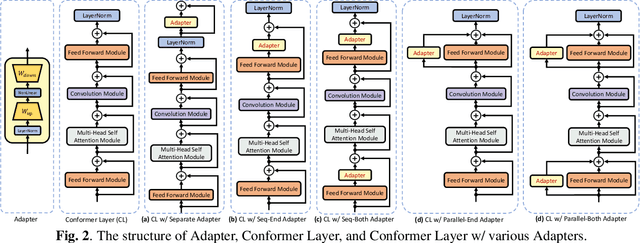
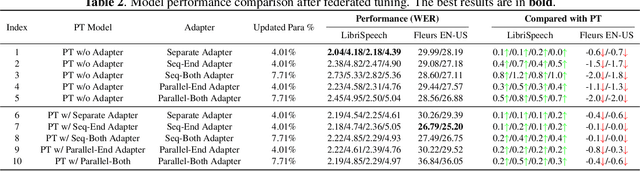
This work explores the challenge of enhancing Automatic Speech Recognition (ASR) model performance across various user-specific domains while preserving user data privacy. We employ federated learning and parameter-efficient domain adaptation methods to solve the (1) massive data requirement of ASR models from user-specific scenarios and (2) the substantial communication cost between servers and clients during federated learning. We demonstrate that when equipped with proper adapters, ASR models under federated tuning can achieve similar performance compared with centralized tuning ones, thus providing a potential direction for future privacy-preserved ASR services. Besides, we investigate the efficiency of different adapters and adapter incorporation strategies under the federated learning setting.
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022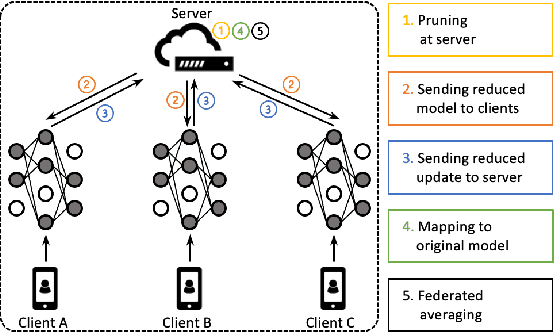
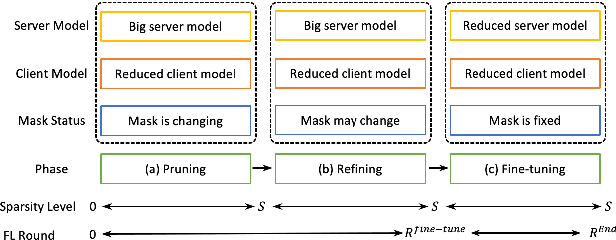
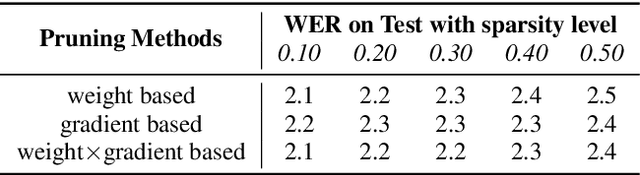
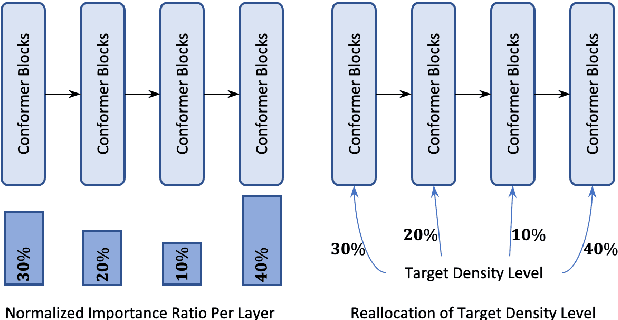
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
Online Model Compression for Federated Learning with Large Models
May 06, 2022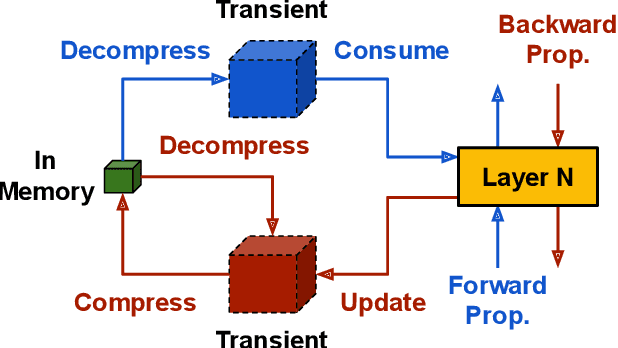
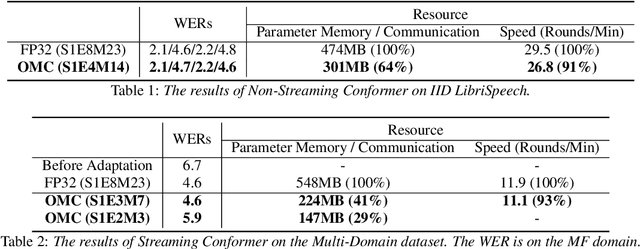
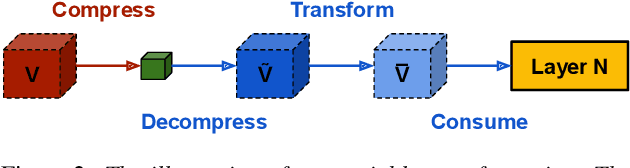
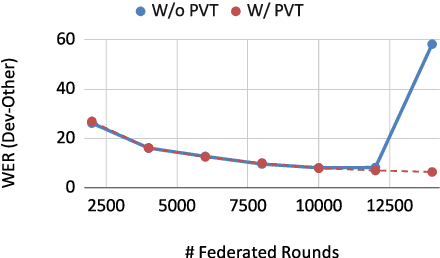
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
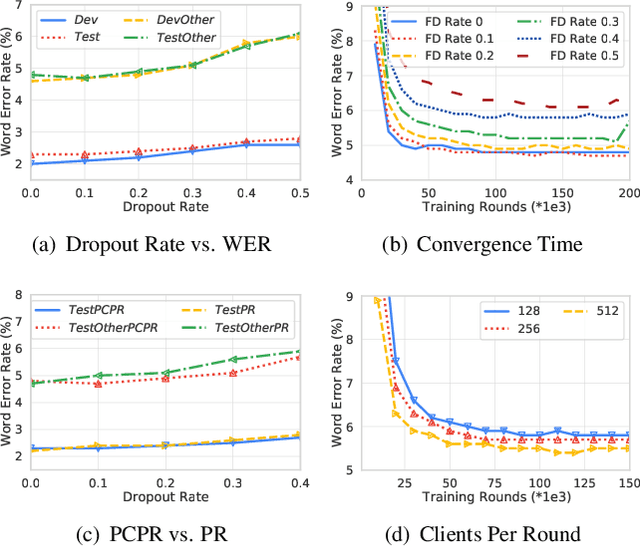

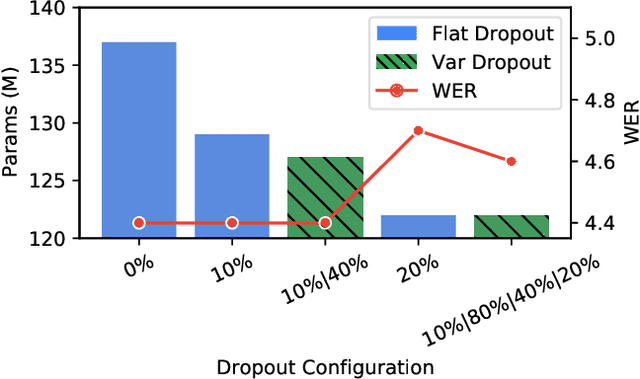
Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.