 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning of Large ASR Models in the Real World
Aug 19, 2024Federated learning (FL) has shown promising results on training machine learning models with privacy preservation. However, for large models with over 100 million parameters, the training resource requirement becomes an obstacle for FL because common devices do not have enough memory and computation power to finish the FL tasks. Although efficient training methods have been proposed, it is still a challenge to train the large models like Conformer based ASR. This paper presents a systematic solution to train the full-size ASR models of 130M parameters with FL. To our knowledge, this is the first real-world FL application of the Conformer model, which is also the largest model ever trained with FL so far. And this is the first paper showing FL can improve the ASR model quality with a set of proposed methods to refine the quality of data and labels of clients. We demonstrate both the training efficiency and the model quality improvement in real-world experiments.
Low-rank Gradient Approximation For Memory-Efficient On-device Training of Deep Neural Network
Jan 24, 2020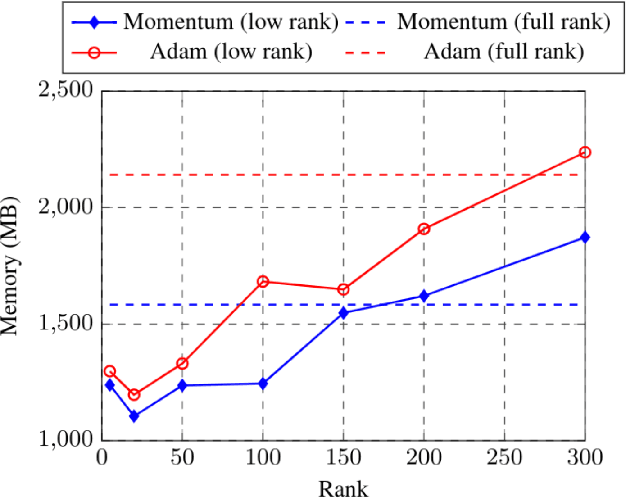
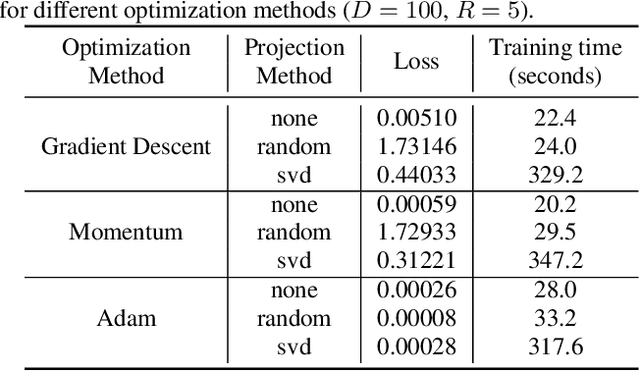
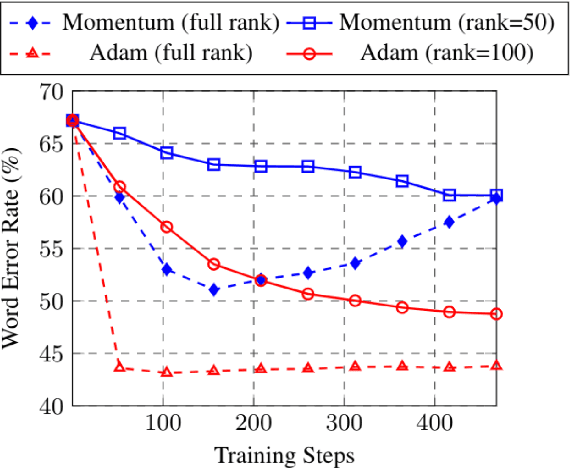
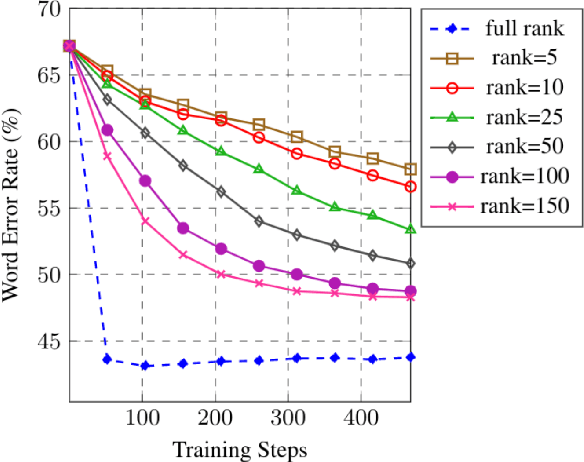
Training machine learning models on mobile devices has the potential of improving both privacy and accuracy of the models. However, one of the major obstacles to achieving this goal is the memory limitation of mobile devices. Reducing training memory enables models with high-dimensional weight matrices, like automatic speech recognition (ASR) models, to be trained on-device. In this paper, we propose approximating the gradient matrices of deep neural networks using a low-rank parameterization as an avenue to save training memory. The low-rank gradient approximation enables more advanced, memory-intensive optimization techniques to be run on device. Our experimental results show that we can reduce the training memory by about 33.0% for Adam optimization. It uses comparable memory to momentum optimization and achieves a 4.5% relative lower word error rate on an ASR personalization task.
Personalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019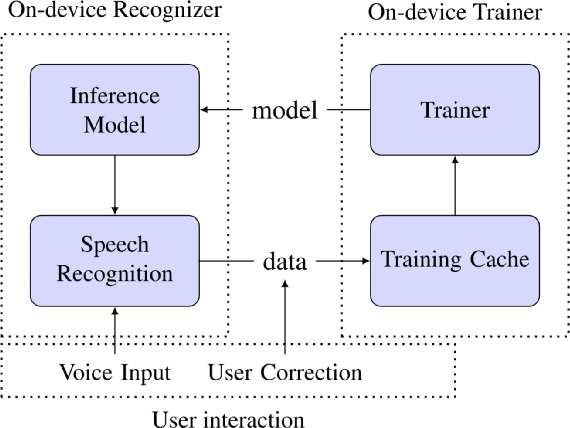
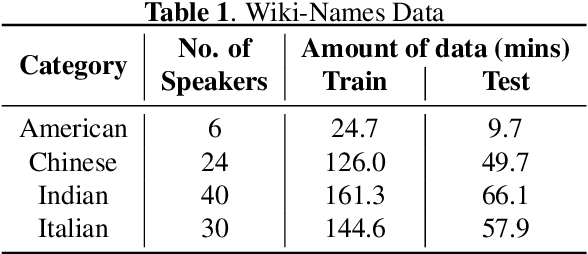
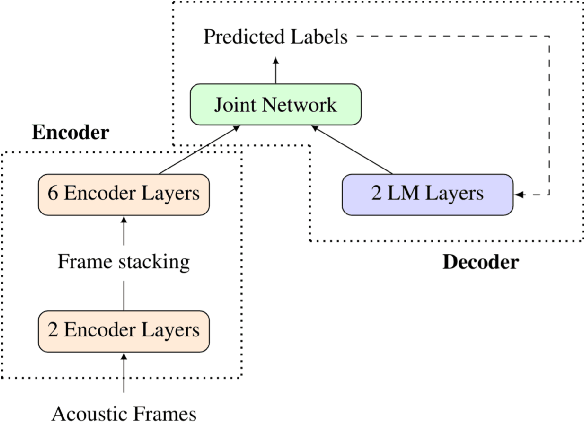
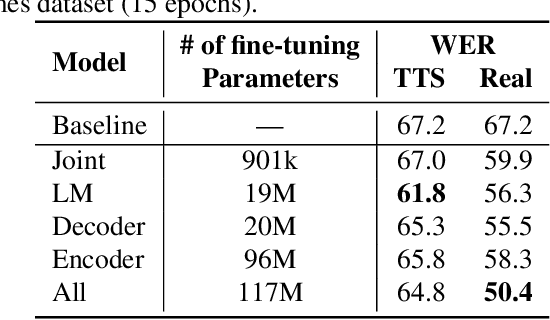
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
An Investigation Into On-device Personalization of End-to-end Automatic Speech Recognition Models
Sep 14, 2019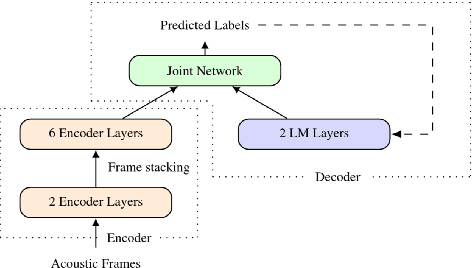
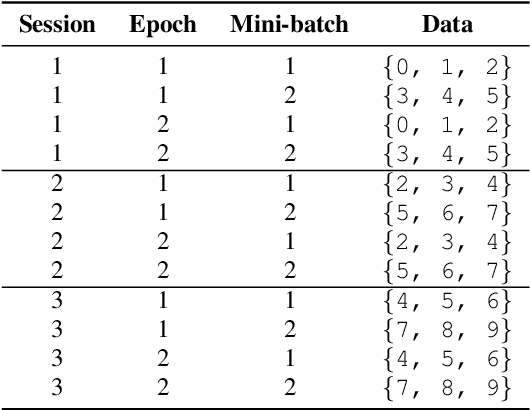
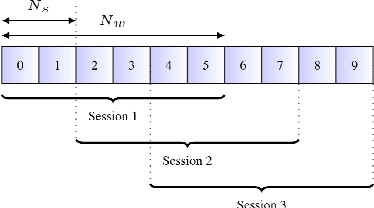
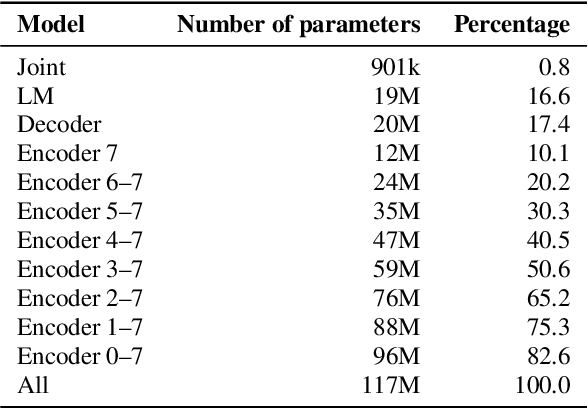
Speaker-independent speech recognition systems trained with data from many users are generally robust against speaker variability and work well for a large population of speakers. However, these systems do not always generalize well for users with very different speech characteristics. This issue can be addressed by building personalized systems that are designed to work well for each specific user. In this paper, we investigate the idea of securely training personalized end-to-end speech recognition models on mobile devices so that user data and models never leave the device and are never stored on a server. We study how the mobile training environment impacts performance by simulating on-device data consumption. We conduct experiments using data collected from speech impaired users for personalization. Our results show that personalization achieved 63.7\% relative word error rate reduction when trained in a server environment and 58.1% in a mobile environment. Moving to on-device personalization resulted in 18.7% performance degradation, in exchange for improved scalability and data privacy. To train the model on device, we split the gradient computation into two and achieved 45% memory reduction at the expense of 42% increase in training time.