 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization of End-to-end Speech Recognition On Mobile Devices For Named Entities
Dec 14, 2019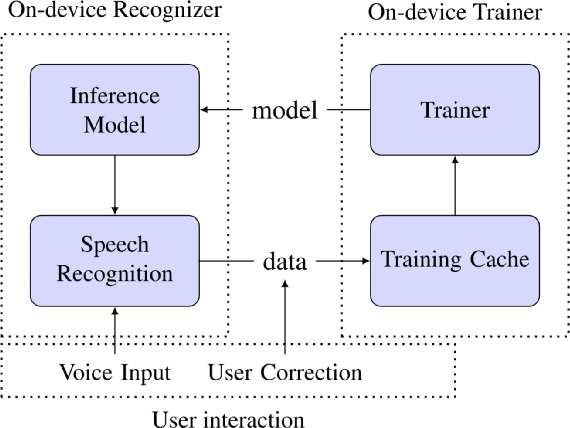
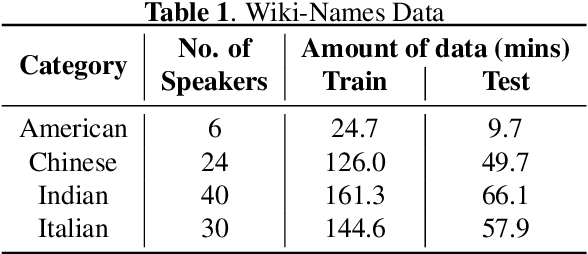
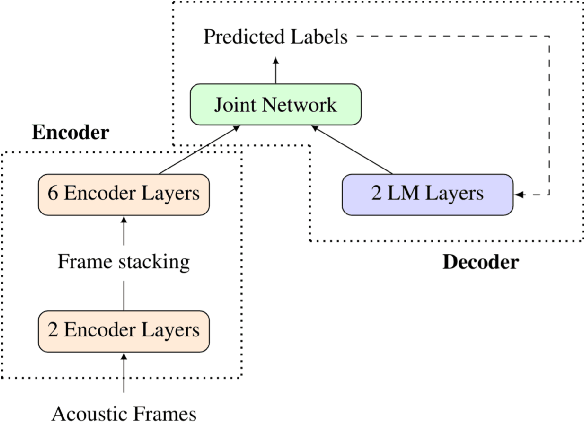
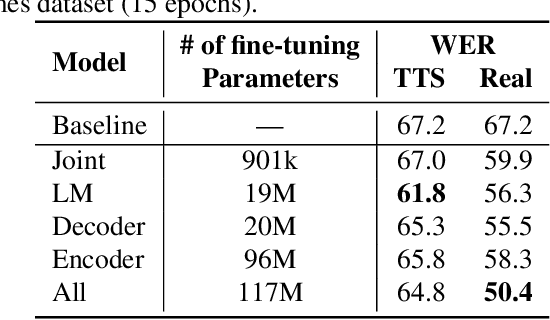
We study the effectiveness of several techniques to personalize end-to-end speech models and improve the recognition of proper names relevant to the user. These techniques differ in the amounts of user effort required to provide supervision, and are evaluated on how they impact speech recognition performance. We propose using keyword-dependent precision and recall metrics to measure vocabulary acquisition performance. We evaluate the algorithms on a dataset that we designed to contain names of persons that are difficult to recognize. Therefore, the baseline recall rate for proper names in this dataset is very low: 2.4%. A data synthesis approach we developed brings it to 48.6%, with no need for speech input from the user. With speech input, if the user corrects only the names, the name recall rate improves to 64.4%. If the user corrects all the recognition errors, we achieve the best recall of 73.5%. To eliminate the need to upload user data and store personalized models on a server, we focus on performing the entire personalization workflow on a mobile device.
Interactive Video Object Segmentation in the Wild
Dec 31, 2017



In this paper we present our system for human-in-the-loop video object segmentation. The backbone of our system is a method for one-shot video object segmentation. While fast, this method requires an accurate pixel-level segmentation of one (or several) frames as input. As manually annotating such a segmentation is impractical, we propose a deep interactive image segmentation method, that can accurately segment objects with only a handful of clicks. On the GrabCut dataset, our method obtains 90% IOU with just 3.8 clicks on average, setting the new state of the art. Furthermore, as our method iteratively refines an initial segmentation, it can effectively correct frames where the video object segmentation fails, thus allowing users to quickly obtain high quality results even on challenging sequences. Finally, we investigate usage patterns and give insights in how many steps users take to annotate frames, what kind of corrections they provide, etc., thus giving important insights for further improving interactive video segmentation.