 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleCL: Self-supervised Learning for Periodic Videos
Nov 13, 2023Analyzing periodic video sequences is a key topic in applications such as automatic production systems, remote sensing, medical applications, or physical training. An example is counting repetitions of a physical exercise. Due to the distinct characteristics of periodic data, self-supervised methods designed for standard image datasets do not capture changes relevant to the progression of the cycle and fail to ignore unrelated noise. They thus do not work well on periodic data. In this paper, we propose CycleCL, a self-supervised learning method specifically designed to work with periodic data. We start from the insight that a good visual representation for periodic data should be sensitive to the phase of a cycle, but be invariant to the exact repetition, i.e. it should generate identical representations for a specific phase throughout all repetitions. We exploit the repetitions in videos to design a novel contrastive learning method based on a triplet loss that optimizes for these desired properties. Our method uses pre-trained features to sample pairs of frames from approximately the same phase and negative pairs of frames from different phases. Then, we iterate between optimizing a feature encoder and resampling triplets, until convergence. By optimizing a model this way, we are able to learn features that have the mentioned desired properties. We evaluate CycleCL on an industrial and multiple human actions datasets, where it significantly outperforms previous video-based self-supervised learning methods on all tasks.
Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
Mar 24, 2021
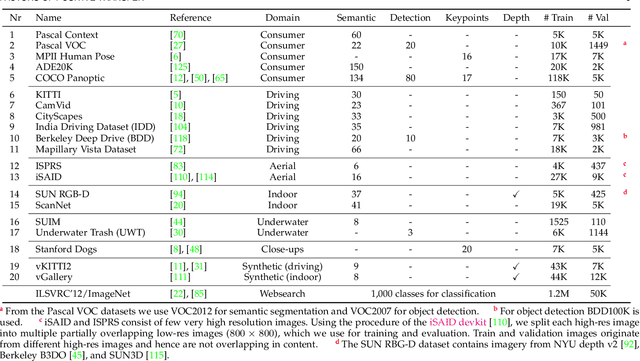


Transfer learning enables to re-use knowledge learned on a source task to help learning a target task. A simple form of transfer learning is common in current state-of-the-art computer vision models, i.e. pre-training a model for image classification on the ILSVRC dataset, and then fine-tune on any target task. However, previous systematic studies of transfer learning have been limited and the circumstances in which it is expected to work are not fully understood. In this paper we carry out an extensive experimental exploration of transfer learning across vastly different image domains (consumer photos, autonomous driving, aerial imagery, underwater, indoor scenes, synthetic, close-ups) and task types (semantic segmentation, object detection, depth estimation, keypoint detection). Importantly, these are all complex, structured output tasks types relevant to modern computer vision applications. In total we carry out over 1200 transfer experiments, including many where the source and target come from different image domains, task types, or both. We systematically analyze these experiments to understand the impact of image domain, task type, and dataset size on transfer learning performance. Our study leads to several insights and concrete recommendations for practitioners.
Training Neural Networks to Produce Compatible Features
Apr 08, 2020



This paper makes a first step towards compatible and hence reusable network components. Rather than training networks for different tasks independently, we adapt the training process to produce network components that are compatible across tasks. We propose and compare several different approaches to accomplish compatibility. Our experiments on CIFAR-10 show that: (i) we can train networks to produce compatible features, without degrading task accuracy compared to training networks independently; (ii) the degree of compatibility is highly dependent on where we split the network into a feature extractor and a classification head; (iii) random initialization has a large effect on compatibility; (iv) we can train incrementally: given previously trained components, we can train new ones which are also compatible with them. This work is part of a larger goal to increase network reusability: we envision that compatibility will enable solving new tasks by mixing and matching suitable components.
Continuous Adaptation for Interactive Object Segmentation by Learning from Corrections
Nov 28, 2019
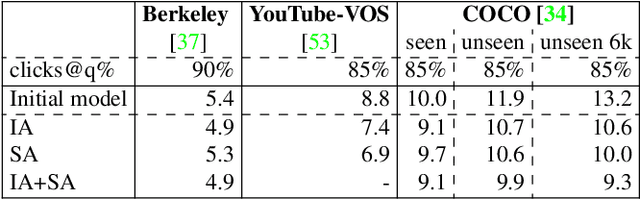

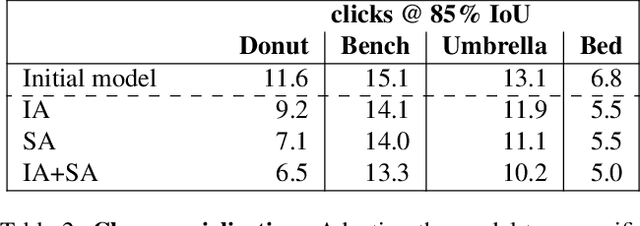
In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works rely on convolutional neural networks to predict the segmentation, taking the image and the corrections made by the user as input. By training on large datasets they offer strong performance, but they keep model parameters fixed at test time. Instead, we treat user corrections as training examples to update our model on-the-fly to the data at hand. This enables it to successfully adapt to the appearance of a particular test image, to distributions shifts in the whole test set, and even to large domain changes, where the imaging modality changes between training and testing. We extensively evaluate our method on 8 diverse datasets and improve over a fixed model on all of them. Our method shows the most dramatic improvements when training and testing domains differ, where it produces segmentation masks of the desired quality from 60-70% less user input. Furthermore we achieve state-of-the-art on four standard interactive segmentation datasets: PASCAL VOC12, GrabCut, DAVIS16 and Berkeley.
Natural Vocabulary Emerges from Free-Form Annotations
Jun 04, 2019
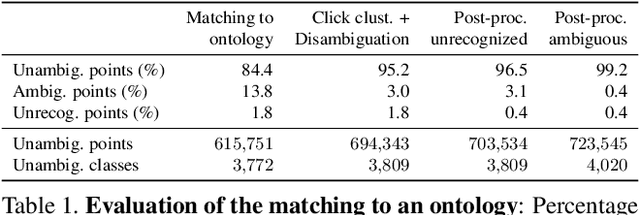
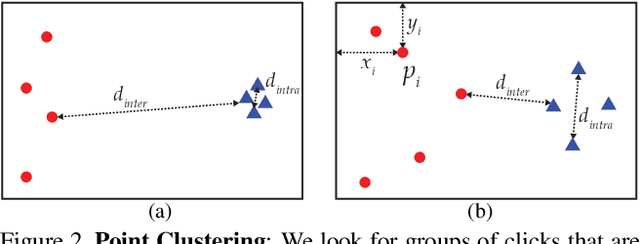

We propose an approach for annotating object classes using free-form text written by undirected and untrained annotators. Free-form labeling is natural for annotators, they intuitively provide very specific and exhaustive labels, and no training stage is necessary. We first collect 729 labels on 15k images using 124 different annotators. Then we automatically enrich the structure of these free-form annotations by discovering a natural vocabulary of 4020 classes within them. This vocabulary represents the natural distribution of objects well and is learned directly from data, instead of being an educated guess done before collecting any labels. Hence, the natural vocabulary emerges from a large mass of free-form annotations. To do so, we (i) map the raw input strings to entities in an ontology of physical objects (which gives them an unambiguous meaning); and (ii) leverage inter-annotator co-occurrences, as well as biases and knowledge specific to individual annotators. Finally, we also automatically extract natural vocabularies of reduced size that have high object coverage while remaining specific. These reduced vocabularies represent the natural distribution of objects much better than commonly used predefined vocabularies. Moreover, they feature more uniform sample distribution over classes.
Efficient Object Annotation via Speaking and Pointing
May 25, 2019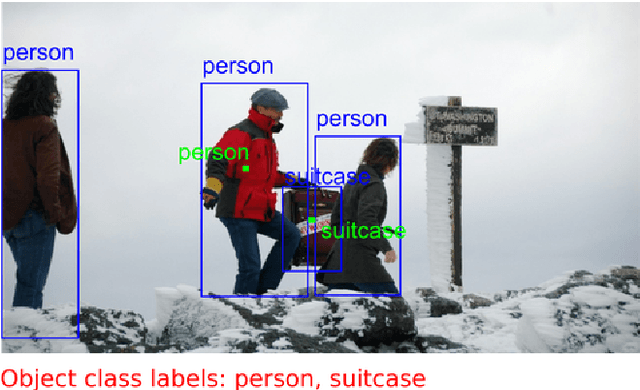



Deep neural networks deliver state-of-the-art visual recognition, but they rely on large datasets, which are time-consuming to annotate. These datasets are typically annotated in two stages: (1) determining the presence of object classes at the image level and (2) marking the spatial extent for all objects of these classes. In this work we use speech, together with mouse inputs, to speed up this process. We first improve stage one, by letting annotators indicate object class presence via speech. We then combine the two stages: annotators draw an object bounding box via the mouse and simultaneously provide its class label via speech. Using speech has distinct advantages over relying on mouse inputs alone. First, it is fast and allows for direct access to the class name, by simply saying it. Second, annotators can simultaneously speak and mark an object location. Finally, speech-based interfaces can be kept extremely simple, hence using them requires less mouse movement compared to existing approaches. Through extensive experiments on the COCO and ILSVRC datasets we show that our approach yields high-quality annotations at significant speed gains. Stage one takes 2.3x - 14.9x less annotation time than existing methods based on a hierarchical organization of the classes to be annotated. Moreover, when combining the two stages, we find that object class labels come for free: annotating them at the same time as bounding boxes has zero additional cost. On COCO, this makes the overall process 1.9x faster than the two-stage approach.
Fast Object Class Labelling via Speech
Nov 23, 2018



Object class labelling is the task of annotating images with labels on the presence or absence of objects from a given class vocabulary. Simply asking one yes-no question per class, however, has a cost that is linear in the vocabulary size and is thus inefficient for large vocabularies. Modern approaches rely on a hierarchical organization of the vocabulary to reduce annotation time, but remain expensive (several minutes per image for the 200 classes in ILSVRC). Instead, we propose a new interface where classes are annotated via speech. Speaking is fast and allows for direct access to the class name, without searching through a list or hierarchy. As additional advantages, annotators can simultaneously speak and scan the image for objects, the interface can be kept extremely simple, and using it requires less mouse movement. However, a key challenge is to train annotators to only say words from the given class vocabulary. We present a way to tackle this challenge and show that our method yields high-quality annotations at significant speed gains (2.3 - 14.9x faster than existing methods).
PHD-GIFs: Personalized Highlight Detection for Automatic GIF Creation
Aug 07, 2018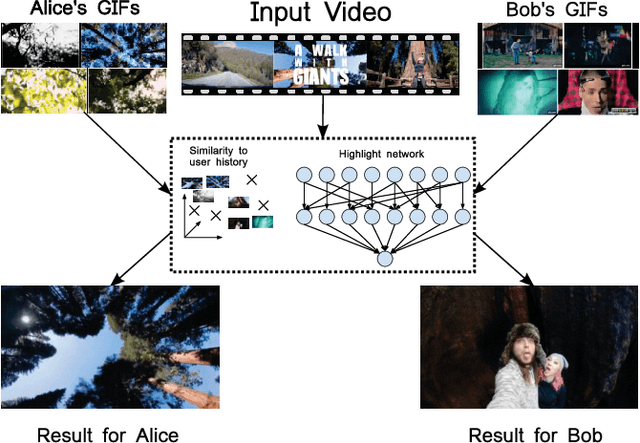
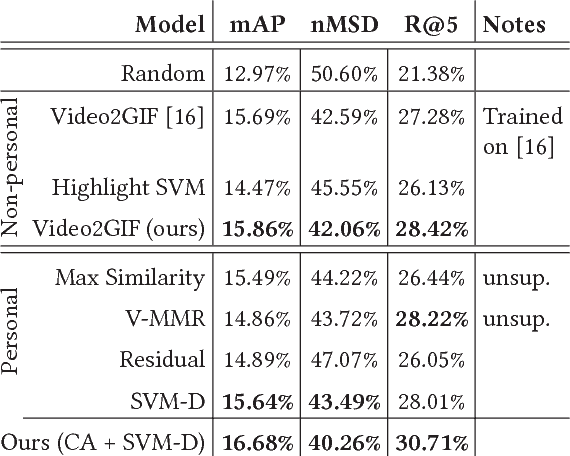

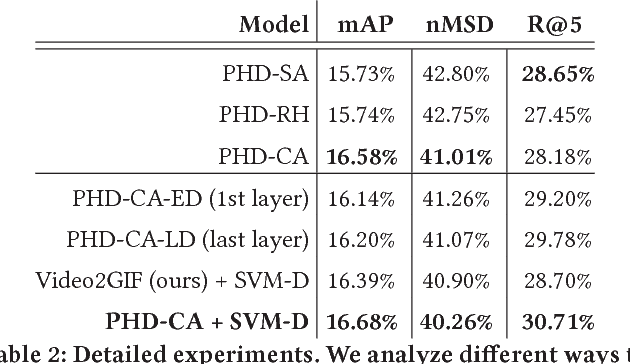
Highlight detection models are typically trained to identify cues that make visual content appealing or interesting for the general public, with the objective of reducing a video to such moments. However, the "interestingness" of a video segment or image is subjective. Thus, such highlight models provide results of limited relevance for the individual user. On the other hand, training one model per user is inefficient and requires large amounts of personal information which is typically not available. To overcome these limitations, we present a global ranking model which conditions on each particular user's interests. Rather than training one model per user, our model is personalized via its inputs, which allows it to effectively adapt its predictions, given only a few user-specific examples. To train this model, we create a large-scale dataset of users and the GIFs they created, giving us an accurate indication of their interests. Our experiments show that using the user history substantially improves the prediction accuracy. On our test set of 850 videos, our model improves the recall by 8% with respect to generic highlight detectors. Furthermore, our method proves more precise than the user-agnostic baselines even with just one person-specific example.
Interactive Video Object Segmentation in the Wild
Dec 31, 2017



In this paper we present our system for human-in-the-loop video object segmentation. The backbone of our system is a method for one-shot video object segmentation. While fast, this method requires an accurate pixel-level segmentation of one (or several) frames as input. As manually annotating such a segmentation is impractical, we propose a deep interactive image segmentation method, that can accurately segment objects with only a handful of clicks. On the GrabCut dataset, our method obtains 90% IOU with just 3.8 clicks on average, setting the new state of the art. Furthermore, as our method iteratively refines an initial segmentation, it can effectively correct frames where the video object segmentation fails, thus allowing users to quickly obtain high quality results even on challenging sequences. Finally, we investigate usage patterns and give insights in how many steps users take to annotate frames, what kind of corrections they provide, etc., thus giving important insights for further improving interactive video segmentation.
Query-adaptive Video Summarization via Quality-aware Relevance Estimation
Sep 28, 2017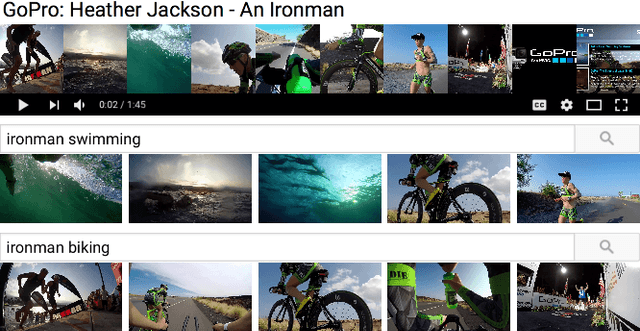
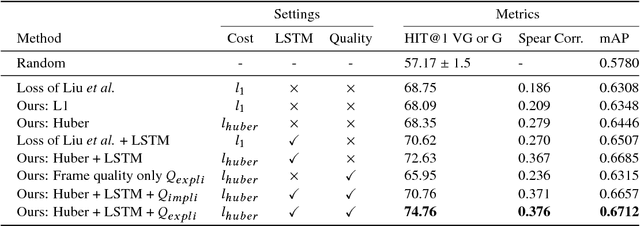
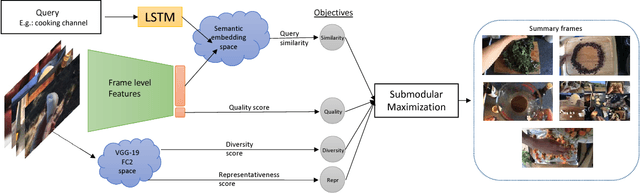
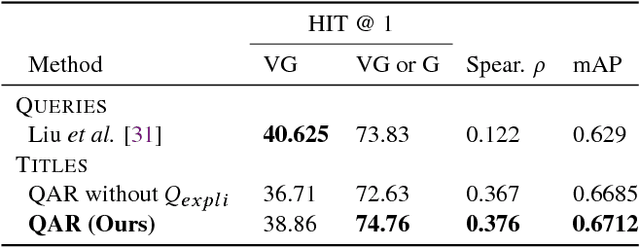
Although the problem of automatic video summarization has recently received a lot of attention, the problem of creating a video summary that also highlights elements relevant to a search query has been less studied. We address this problem by posing query-relevant summarization as a video frame subset selection problem, which lets us optimise for summaries which are simultaneously diverse, representative of the entire video, and relevant to a text query. We quantify relevance by measuring the distance between frames and queries in a common textual-visual semantic embedding space induced by a neural network. In addition, we extend the model to capture query-independent properties, such as frame quality. We compare our method against previous state of the art on textual-visual embeddings for thumbnail selection and show that our model outperforms them on relevance prediction. Furthermore, we introduce a new dataset, annotated with diversity and query-specific relevance labels. On this dataset, we train and test our complete model for video summarization and show that it outperforms standard baselines such as Maximal Marginal Relevance.