 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Adaptation for Interactive Object Segmentation by Learning from Corrections
Paper and Code
Nov 28, 2019
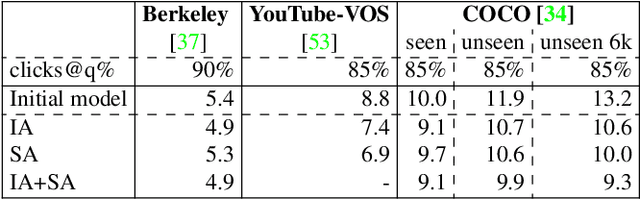

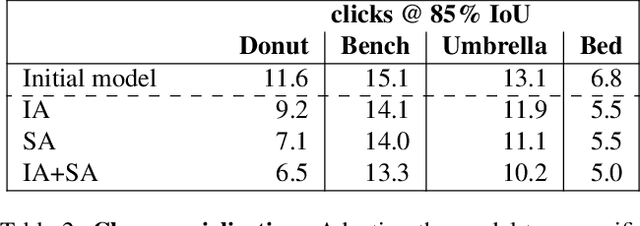
In interactive object segmentation a user collaborates with a computer vision model to segment an object. Recent works rely on convolutional neural networks to predict the segmentation, taking the image and the corrections made by the user as input. By training on large datasets they offer strong performance, but they keep model parameters fixed at test time. Instead, we treat user corrections as training examples to update our model on-the-fly to the data at hand. This enables it to successfully adapt to the appearance of a particular test image, to distributions shifts in the whole test set, and even to large domain changes, where the imaging modality changes between training and testing. We extensively evaluate our method on 8 diverse datasets and improve over a fixed model on all of them. Our method shows the most dramatic improvements when training and testing domains differ, where it produces segmentation masks of the desired quality from 60-70% less user input. Furthermore we achieve state-of-the-art on four standard interactive segmentation datasets: PASCAL VOC12, GrabCut, DAVIS16 and Berkeley.