 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoCap: Video Object Captioning and Segmentation from Any Prompt
Aug 29, 2025Understanding objects in videos in terms of fine-grained localization masks and detailed semantic properties is a fundamental task in video understanding. In this paper, we propose VoCap, a flexible video model that consumes a video and a prompt of various modalities (text, box or mask), and produces a spatio-temporal masklet with a corresponding object-centric caption. As such our model addresses simultaneously the tasks of promptable video object segmentation, referring expression segmentation, and object captioning. Since obtaining data for this task is tedious and expensive, we propose to annotate an existing large-scale segmentation dataset (SAV) with pseudo object captions. We do so by preprocessing videos with their ground-truth masks to highlight the object of interest and feed this to a large Vision Language Model (VLM). For an unbiased evaluation, we collect manual annotations on the validation set. We call the resulting dataset SAV-Caption. We train our VoCap model at scale on a SAV-Caption together with a mix of other image and video datasets. Our model yields state-of-the-art results on referring expression video object segmentation, is competitive on semi-supervised video object segmentation, and establishes a benchmark for video object captioning. Our dataset will be made available at https://github.com/google-deepmind/vocap.
VQA Training Sets are Self-play Environments for Generating Few-shot Pools
May 30, 2024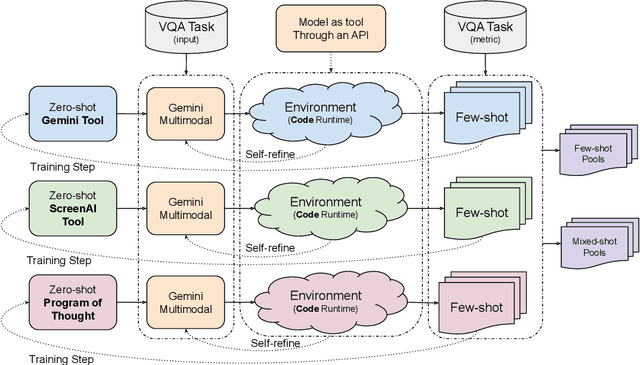

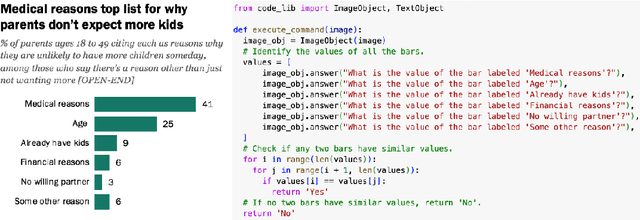
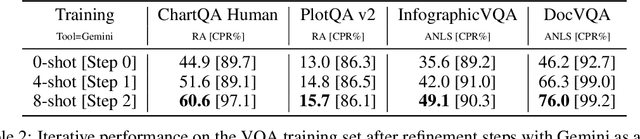
Large-language models and large-vision models are increasingly capable of solving compositional reasoning tasks, as measured by breakthroughs in visual-question answering benchmarks. However, state-of-the-art solutions often involve careful construction of large pre-training and fine-tuning datasets, which can be expensive. The use of external tools, whether other ML models, search engines, or APIs, can significantly improve performance by breaking down high-level reasoning questions into sub-questions that are answerable by individual tools, but this approach has similar dataset construction costs to teach fine-tuned models how to use the available tools. We propose a technique in which existing training sets can be directly used for constructing computational environments with task metrics as rewards. This enables a model to autonomously teach itself to use itself or another model as a tool. By doing so, we augment training sets by integrating external signals. The proposed method starts with zero-shot prompts and iteratively refines them by selecting few-shot examples that maximize the task metric on the training set. Our experiments showcase how Gemini learns how to use itself, or another smaller and specialized model such as ScreenAI, to iteratively improve performance on training sets. Our approach successfully generalizes and improves upon zeroshot performance on charts, infographics, and document visual question-answering datasets
HAMMR: HierArchical MultiModal React agents for generic VQA
Apr 08, 2024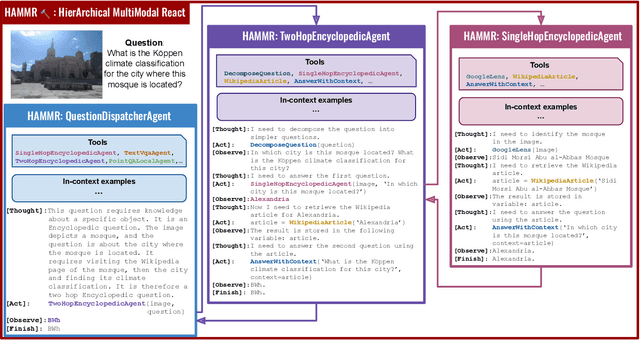
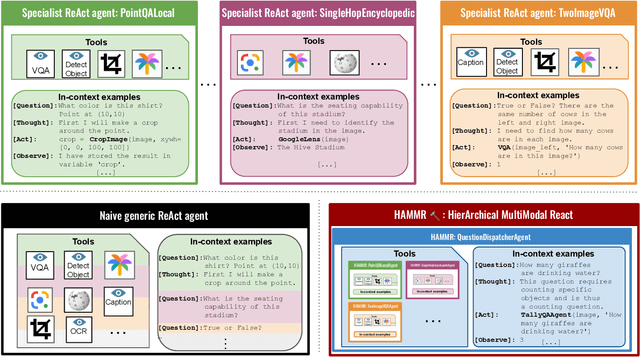


Combining Large Language Models (LLMs) with external specialized tools (LLMs+tools) is a recent paradigm to solve multimodal tasks such as Visual Question Answering (VQA). While this approach was demonstrated to work well when optimized and evaluated for each individual benchmark, in practice it is crucial for the next generation of real-world AI systems to handle a broad range of multimodal problems. Therefore we pose the VQA problem from a unified perspective and evaluate a single system on a varied suite of VQA tasks including counting, spatial reasoning, OCR-based reasoning, visual pointing, external knowledge, and more. In this setting, we demonstrate that naively applying the LLM+tools approach using the combined set of all tools leads to poor results. This motivates us to introduce HAMMR: HierArchical MultiModal React. We start from a multimodal ReAct-based system and make it hierarchical by enabling our HAMMR agents to call upon other specialized agents. This enhances the compositionality of the LLM+tools approach, which we show to be critical for obtaining high accuracy on generic VQA. Concretely, on our generic VQA suite, HAMMR outperforms the naive LLM+tools approach by 19.5%. Additionally, HAMMR achieves state-of-the-art results on this task, outperforming the generic standalone PaLI-X VQA model by 5.0%.
How (not) to ensemble LVLMs for VQA
Oct 10, 2023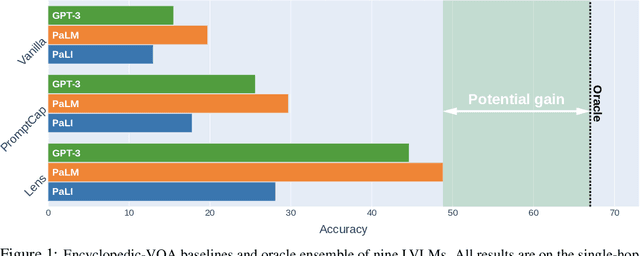


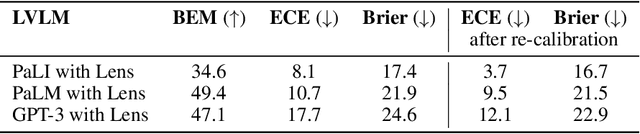
This paper studies ensembling in the era of Large Vision-Language Models (LVLMs). Ensembling is a classical method to combine different models to get increased performance. In the recent work on Encyclopedic-VQA the authors examine a wide variety of models to solve their task: from vanilla LVLMs, to models including the caption as extra context, to models augmented with Lens-based retrieval of Wikipedia pages. Intuitively these models are highly complementary, which should make them ideal for ensembling. Indeed, an oracle experiment shows potential gains from 48.8% accuracy (the best single model) all the way up to 67% (best possible ensemble). So it is a trivial exercise to create an ensemble with substantial real gains. Or is it?
Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories
Jun 15, 2023We propose Encyclopedic-VQA, a large scale visual question answering (VQA) dataset featuring visual questions about detailed properties of fine-grained categories and instances. It contains 221k unique question+answer pairs each matched with (up to) 5 images, resulting in a total of 1M VQA samples. Moreover, our dataset comes with a controlled knowledge base derived from Wikipedia, marking the evidence to support each answer. Empirically, we show that our dataset poses a hard challenge for large vision+language models as they perform poorly on our dataset: PaLI [14] is state-of-the-art on OK-VQA [37], yet it only achieves 13.0% accuracy on our dataset. Moreover, we experimentally show that progress on answering our encyclopedic questions can be achieved by augmenting large models with a mechanism that retrieves relevant information from the knowledge base. An oracle experiment with perfect retrieval achieves 87.0% accuracy on the single-hop portion of our dataset, and an automatic retrieval-augmented prototype yields 48.8%. We believe that our dataset enables future research on retrieval-augmented vision+language models.
The Missing Link: Finding label relations across datasets
Jun 09, 2022

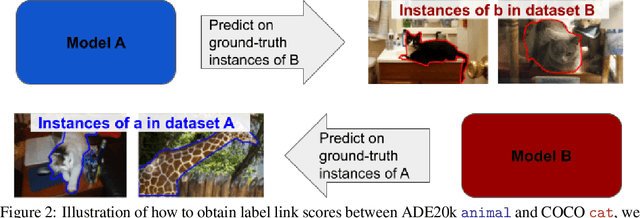

Computer Vision is driven by the many datasets which can be used for training or evaluating novel methods. However, each dataset has different set of class labels, visual definition of classes, images following a specific distribution, annotation protocols, etc. In this paper we explore the automatic discovery of visual-semantic relations between labels across datasets. We want to understand how the instances of a certain class in a dataset relate to the instances of another class in another dataset. Are they in an identity, parent/child, overlap relation? Or is there no link between them at all? To find relations between labels across datasets, we propose methods based on language, on vision, and on a combination of both. Our methods can effectively discover label relations across datasets and the type of the relations. We use these results for a deeper inspection on why instances relate, find missing aspects of a class, and use our relations to create finer-grained annotations. We conclude that label relations cannot be established by looking at the names of classes alone, as they depend strongly on how each of the datasets was constructed.
How stable are Transferability Metrics evaluations?
Apr 11, 2022



Transferability metrics is a maturing field with increasing interest, which aims at providing heuristics for selecting the most suitable source models to transfer to a given target dataset, without fine-tuning them all. However, existing works rely on custom experimental setups which differ across papers, leading to inconsistent conclusions about which transferability metrics work best. In this paper we conduct a large-scale study by systematically constructing a broad range of 715k experimental setup variations. We discover that even small variations to an experimental setup lead to different conclusions about the superiority of a transferability metric over another. Then we propose better evaluations by aggregating across many experiments, enabling to reach more stable conclusions. As a result, we reveal the superiority of LogME at selecting good source datasets to transfer from in a semantic segmentation scenario, NLEEP at selecting good source architectures in an image classification scenario, and GBC at determining which target task benefits most from a given source model. Yet, no single transferability metric works best in all scenarios.
Transferability Metrics for Selecting Source Model Ensembles
Nov 25, 2021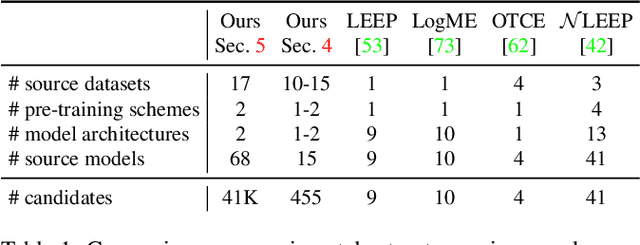
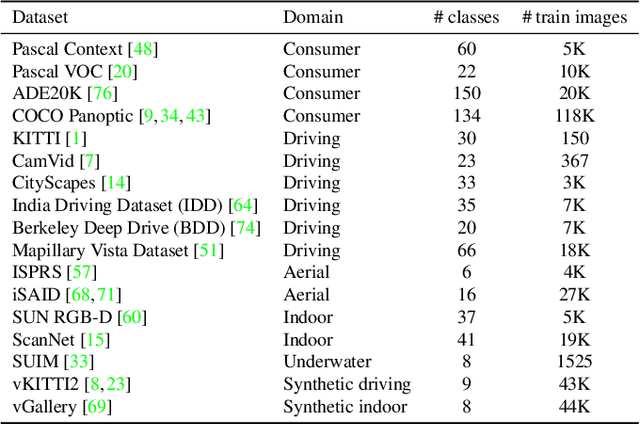
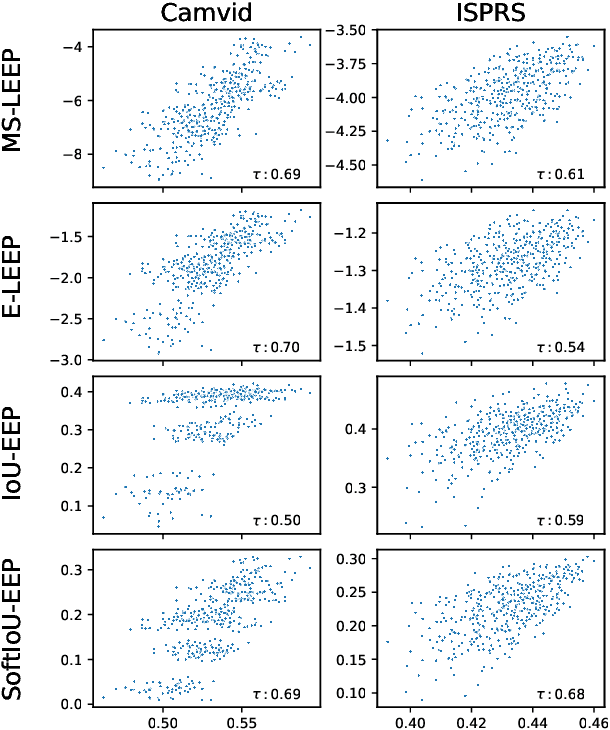

We address the problem of ensemble selection in transfer learning: Given a large pool of source models we want to select an ensemble of models which, after fine-tuning on the target training set, yields the best performance on the target test set. Since fine-tuning all possible ensembles is computationally prohibitive, we aim at predicting performance on the target dataset using a computationally efficient transferability metric. We propose several new transferability metrics designed for this task and evaluate them in a challenging and realistic transfer learning setup for semantic segmentation: we create a large and diverse pool of source models by considering 17 source datasets covering a wide variety of image domain, two different architectures, and two pre-training schemes. Given this pool, we then automatically select a subset to form an ensemble performing well on a given target dataset. We compare the ensemble selected by our method to two baselines which select a single source model, either (1) from the same pool as our method; or (2) from a pool containing large source models, each with similar capacity as an ensemble. Averaged over 17 target datasets, we outperform these baselines by 6.0% and 2.5% relative mean IoU, respectively.
Transferability Estimation using Bhattacharyya Class Separability
Nov 24, 2021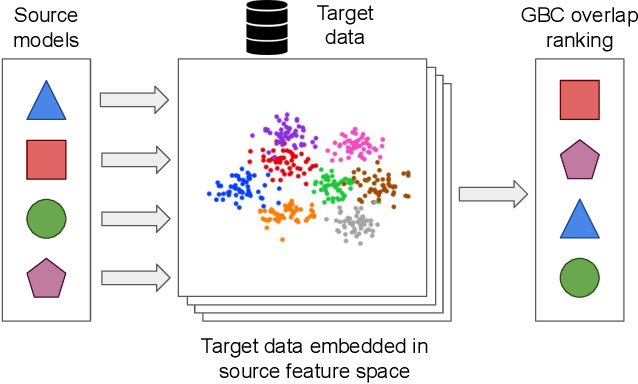



Transfer learning has become a popular method for leveraging pre-trained models in computer vision. However, without performing computationally expensive fine-tuning, it is difficult to quantify which pre-trained source models are suitable for a specific target task, or, conversely, to which tasks a pre-trained source model can be easily adapted to. In this work, we propose Gaussian Bhattacharyya Coefficient (GBC), a novel method for quantifying transferability between a source model and a target dataset. In a first step we embed all target images in the feature space defined by the source model, and represent them with per-class Gaussians. Then, we estimate their pairwise class separability using the Bhattacharyya coefficient, yielding a simple and effective measure of how well the source model transfers to the target task. We evaluate GBC on image classification tasks in the context of dataset and architecture selection. Further, we also perform experiments on the more complex semantic segmentation transferability estimation task. We demonstrate that GBC outperforms state-of-the-art transferability metrics on most evaluation criteria in the semantic segmentation settings, matches the performance of top methods for dataset transferability in image classification, and performs best on architecture selection problems for image classification.
Factors of Influence for Transfer Learning across Diverse Appearance Domains and Task Types
Mar 24, 2021
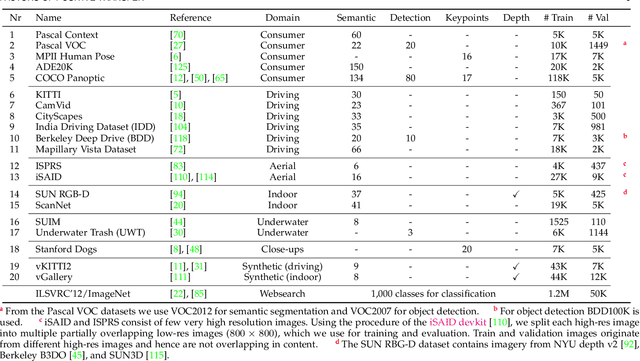


Transfer learning enables to re-use knowledge learned on a source task to help learning a target task. A simple form of transfer learning is common in current state-of-the-art computer vision models, i.e. pre-training a model for image classification on the ILSVRC dataset, and then fine-tune on any target task. However, previous systematic studies of transfer learning have been limited and the circumstances in which it is expected to work are not fully understood. In this paper we carry out an extensive experimental exploration of transfer learning across vastly different image domains (consumer photos, autonomous driving, aerial imagery, underwater, indoor scenes, synthetic, close-ups) and task types (semantic segmentation, object detection, depth estimation, keypoint detection). Importantly, these are all complex, structured output tasks types relevant to modern computer vision applications. In total we carry out over 1200 transfer experiments, including many where the source and target come from different image domains, task types, or both. We systematically analyze these experiments to understand the impact of image domain, task type, and dataset size on transfer learning performance. Our study leads to several insights and concrete recommendations for practitioners.