 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA Training Sets are Self-play Environments for Generating Few-shot Pools
Paper and Code
May 30, 2024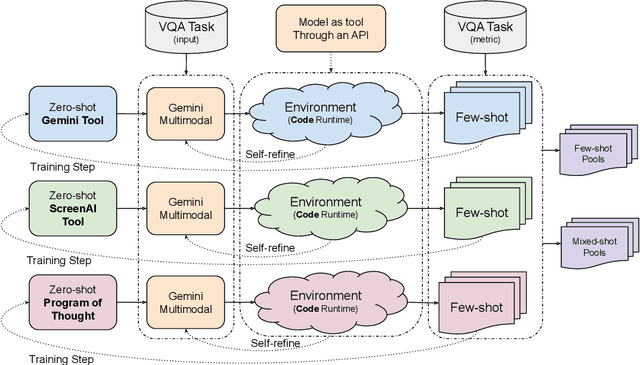

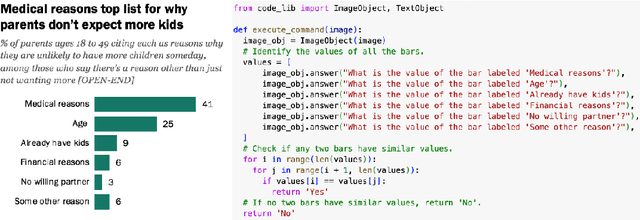
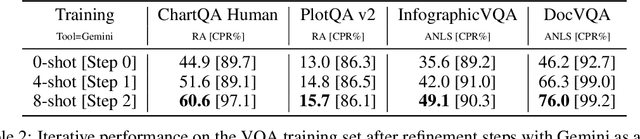
Large-language models and large-vision models are increasingly capable of solving compositional reasoning tasks, as measured by breakthroughs in visual-question answering benchmarks. However, state-of-the-art solutions often involve careful construction of large pre-training and fine-tuning datasets, which can be expensive. The use of external tools, whether other ML models, search engines, or APIs, can significantly improve performance by breaking down high-level reasoning questions into sub-questions that are answerable by individual tools, but this approach has similar dataset construction costs to teach fine-tuned models how to use the available tools. We propose a technique in which existing training sets can be directly used for constructing computational environments with task metrics as rewards. This enables a model to autonomously teach itself to use itself or another model as a tool. By doing so, we augment training sets by integrating external signals. The proposed method starts with zero-shot prompts and iteratively refines them by selecting few-shot examples that maximize the task metric on the training set. Our experiments showcase how Gemini learns how to use itself, or another smaller and specialized model such as ScreenAI, to iteratively improve performance on training sets. Our approach successfully generalizes and improves upon zeroshot performance on charts, infographics, and document visual question-answering datasets