 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA Training Sets are Self-play Environments for Generating Few-shot Pools
May 30, 2024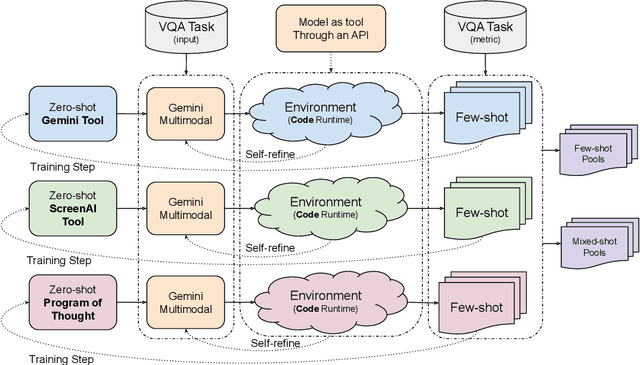

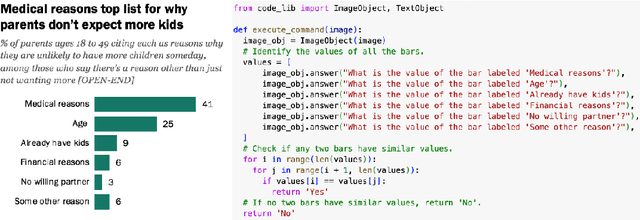
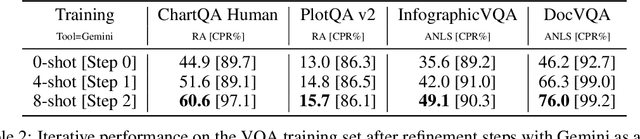
Large-language models and large-vision models are increasingly capable of solving compositional reasoning tasks, as measured by breakthroughs in visual-question answering benchmarks. However, state-of-the-art solutions often involve careful construction of large pre-training and fine-tuning datasets, which can be expensive. The use of external tools, whether other ML models, search engines, or APIs, can significantly improve performance by breaking down high-level reasoning questions into sub-questions that are answerable by individual tools, but this approach has similar dataset construction costs to teach fine-tuned models how to use the available tools. We propose a technique in which existing training sets can be directly used for constructing computational environments with task metrics as rewards. This enables a model to autonomously teach itself to use itself or another model as a tool. By doing so, we augment training sets by integrating external signals. The proposed method starts with zero-shot prompts and iteratively refines them by selecting few-shot examples that maximize the task metric on the training set. Our experiments showcase how Gemini learns how to use itself, or another smaller and specialized model such as ScreenAI, to iteratively improve performance on training sets. Our approach successfully generalizes and improves upon zeroshot performance on charts, infographics, and document visual question-answering datasets
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024



Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
Towards Better Evaluation of Instruction-Following: A Case-Study in Summarization
Oct 20, 2023Despite recent advances, evaluating how well large language models (LLMs) follow user instructions remains an open problem. While evaluation methods of language models have seen a rise in prompt-based approaches, limited work on the correctness of these methods has been conducted. In this work, we perform a meta-evaluation of a variety of metrics to quantify how accurately they measure the instruction-following abilities of LLMs. Our investigation is performed on grounded query-based summarization by collecting a new short-form, real-world dataset riSum, containing 300 document-instruction pairs with 3 answers each. All 900 answers are rated by 3 human annotators. Using riSum, we analyze the agreement between evaluation methods and human judgment. Finally, we propose new LLM-based reference-free evaluation methods that improve upon established baselines and perform on par with costly reference-based metrics that require high-quality summaries.
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Sep 01, 2023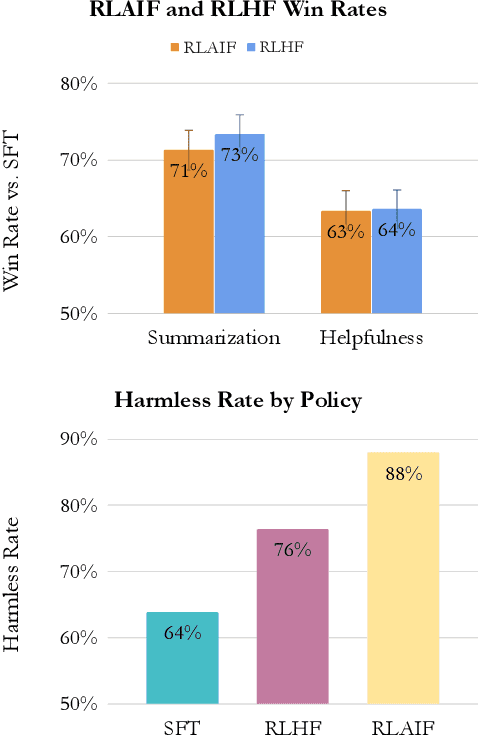
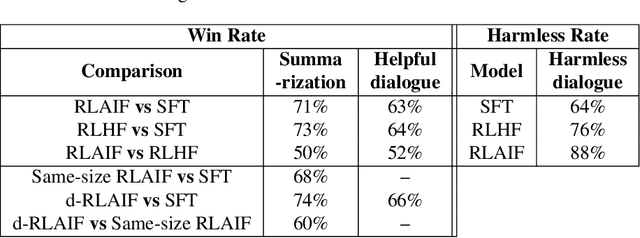
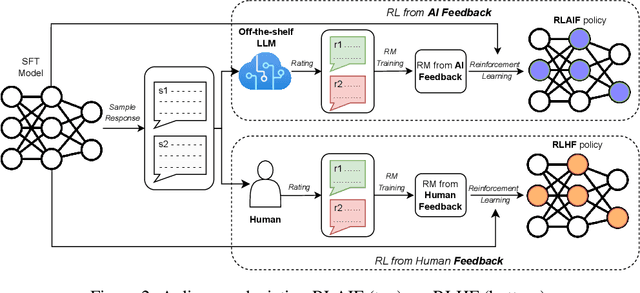

Reinforcement learning from human feedback (RLHF) is effective at aligning large language models (LLMs) to human preferences, but gathering high quality human preference labels is a key bottleneck. We conduct a head-to-head comparison of RLHF vs. RL from AI Feedback (RLAIF) - a technique where preferences are labeled by an off-the-shelf LLM in lieu of humans, and we find that they result in similar improvements. On the task of summarization, human evaluators prefer generations from both RLAIF and RLHF over a baseline supervised fine-tuned model in ~70% of cases. Furthermore, when asked to rate RLAIF vs. RLHF summaries, humans prefer both at equal rates. These results suggest that RLAIF can yield human-level performance, offering a potential solution to the scalability limitations of RLHF.
Fast Multi-language LSTM-based Online Handwriting Recognition
Feb 22, 2019
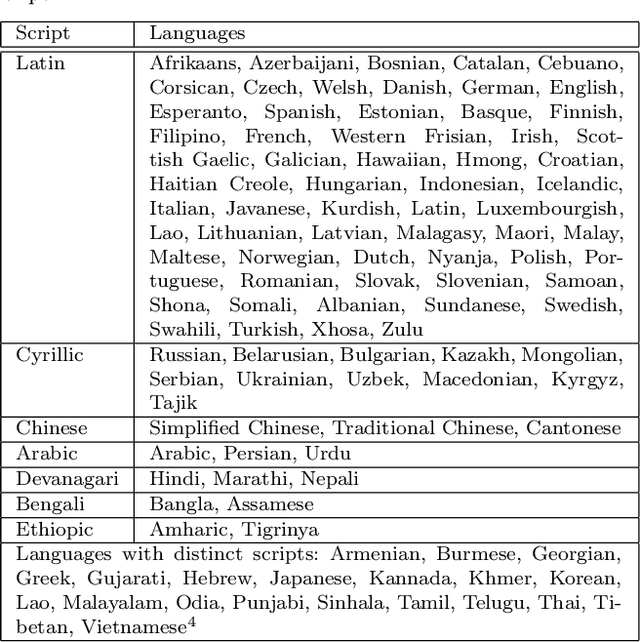
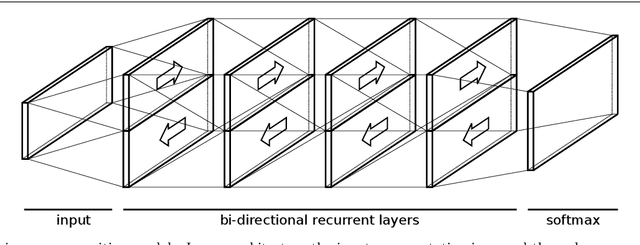
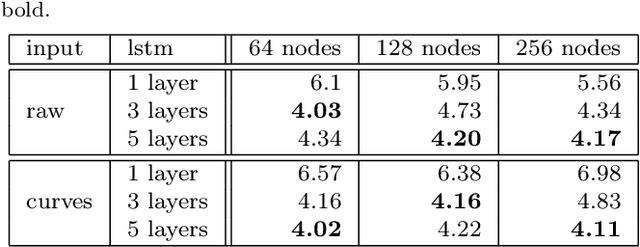
We describe an online handwriting system that is able to support 102 languages using a deep neural network architecture. This new system has completely replaced our previous Segment-and-Decode-based system and reduced the error rate by 20%-40% relative for most languages. Further, we report new state-of-the-art results on IAM-OnDB for both the open and closed dataset setting. The system combines methods from sequence recognition with a new input encoding using B\'ezier curves. This leads to up to 10x faster recognition times compared to our previous system. Through a series of experiments we determine the optimal configuration of our models and report the results of our setup on a number of additional public datasets.
Predicted Variables in Programming
Oct 01, 2018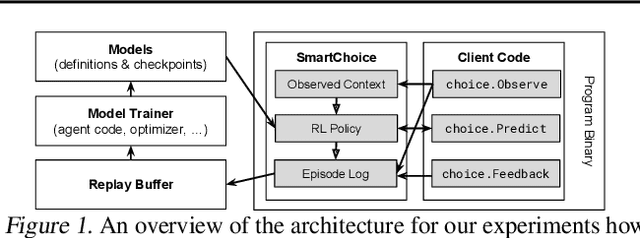
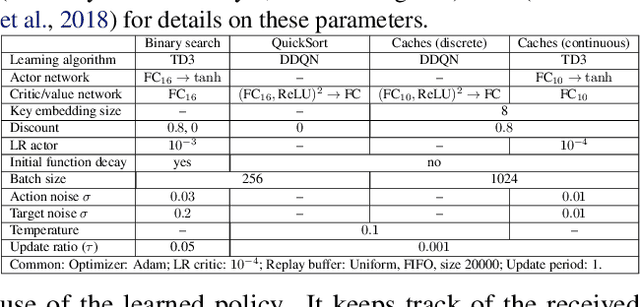
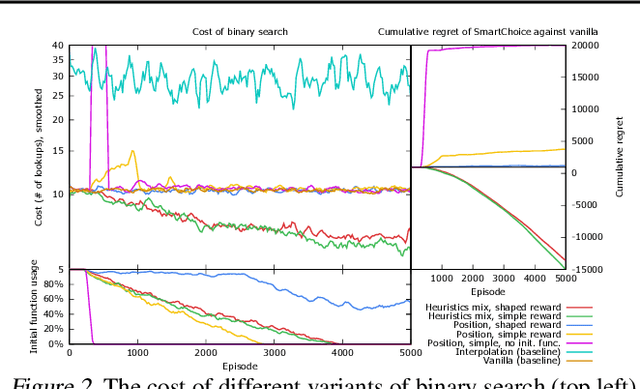
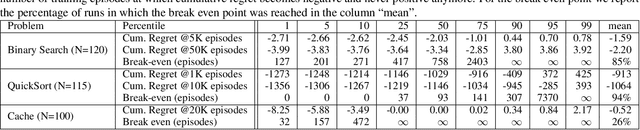
We present Predicted Variables (PVars), an approach to making machine learning (ML) a first class citizen in programming languages. There is a growing divide in approaches to building systems: using human experts (e.g. programming) on the one hand, and using behavior learned from data (e.g. ML) on the other hand. PVars aim to make ML in programming as easy as `if' statements and with that hybridize ML with programming. We leverage the existing concept of variables and create a new type, a predicted variable. PVars are akin to native variables with one important distinction: PVars determine their value using ML when evaluated. We describe PVars and their interface, how they can be used in programming, and demonstrate the feasibility of our approach on three algorithmic problems: binary search, Quicksort, and caches. We show experimentally that PVars are able to improve over the commonly used heuristics and lead to a better performance than the original algorithms. As opposed to previous work applying ML to algorithmic problems, PVars have the advantage that they can be used within the existing frameworks and do not require the existing domain knowledge to be replaced. PVars allow for a seamless integration of ML into existing systems and algorithms. Our PVars implementation currently relies on standard Reinforcement Learning (RL) methods. To learn faster, PVars use the heuristic function, which they are replacing, as an initial function. We show that PVars quickly pick up the behavior of the initial function and then improve performance beyond that without ever performing substantially worse -- allowing for a safe deployment in critical applications.