 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
May 25, 2024



Large language models (LLMs) augmented with retrieval exhibit robust performance and extensive versatility by incorporating external contexts. However, the input length grows linearly in the number of retrieved documents, causing a dramatic increase in latency. In this paper, we propose a novel paradigm named Sparse RAG, which seeks to cut computation costs through sparsity. Specifically, Sparse RAG encodes retrieved documents in parallel, which eliminates latency introduced by long-range attention of retrieved documents. Then, LLMs selectively decode the output by only attending to highly relevant caches auto-regressively, which are chosen via prompting LLMs with special control tokens. It is notable that Sparse RAG combines the assessment of each individual document and the generation of the response into a single process. The designed sparse mechanism in a RAG system can facilitate the reduction of the number of documents loaded during decoding for accelerating the inference of the RAG system. Additionally, filtering out undesirable contexts enhances the model's focus on relevant context, inherently improving its generation quality. Evaluation results of two datasets show that Sparse RAG can strike an optimal balance between generation quality and computational efficiency, demonstrating its generalizability across both short- and long-form generation tasks.
Chart-based Reasoning: Transferring Capabilities from LLMs to VLMs
Mar 19, 2024



Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of large-language models (LLMs) have seen numerous improvements. We propose a technique to transfer capabilities from LLMs to VLMs. On the recently introduced ChartQA, our method obtains state-of-the-art performance when applied on the PaLI3-5B VLM by \citet{chen2023pali3}, while also enabling much better performance on PlotQA and FigureQA. We first improve the chart representation by continuing the pre-training stage using an improved version of the chart-to-table translation task by \citet{liu2023deplot}. We then propose constructing a 20x larger dataset than the original training set. To improve general reasoning capabilities and improve numerical operations, we synthesize reasoning traces using the table representation of charts. Lastly, our model is fine-tuned using the multitask loss introduced by \citet{hsieh2023distilling}. Our variant ChartPaLI-5B outperforms even 10x larger models such as PaLIX-55B without using an upstream OCR system, while keeping inference time constant compared to the PaLI3-5B baseline. When rationales are further refined with a simple program-of-thought prompt \cite{chen2023program}, our model outperforms the recently introduced Gemini Ultra and GPT-4V.
ScreenAI: A Vision-Language Model for UI and Infographics Understanding
Feb 19, 2024



Screen user interfaces (UIs) and infographics, sharing similar visual language and design principles, play important roles in human communication and human-machine interaction. We introduce ScreenAI, a vision-language model that specializes in UI and infographics understanding. Our model improves upon the PaLI architecture with the flexible patching strategy of pix2struct and is trained on a unique mixture of datasets. At the heart of this mixture is a novel screen annotation task in which the model has to identify the type and location of UI elements. We use these text annotations to describe screens to Large Language Models and automatically generate question-answering (QA), UI navigation, and summarization training datasets at scale. We run ablation studies to demonstrate the impact of these design choices. At only 5B parameters, ScreenAI achieves new state-of-the-artresults on UI- and infographics-based tasks (Multi-page DocVQA, WebSRC, MoTIF and Widget Captioning), and new best-in-class performance on others (Chart QA, DocVQA, and InfographicVQA) compared to models of similar size. Finally, we release three new datasets: one focused on the screen annotation task and two others focused on question answering.
Fusion-Eval: Integrating Evaluators with LLMs
Nov 15, 2023
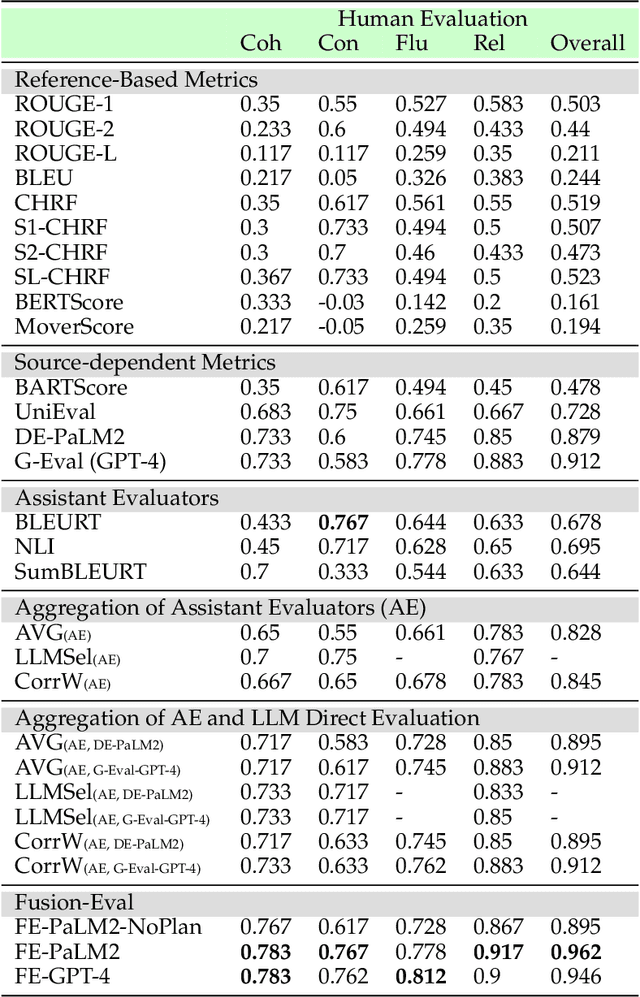
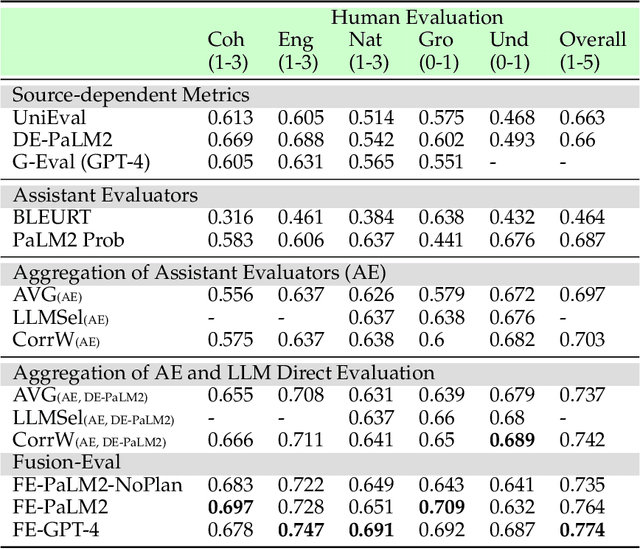
Evaluating Large Language Models (LLMs) is a complex task, especially considering the intricacies of natural language understanding and the expectations for high-level reasoning. Traditional evaluations typically lean on human-based, model-based, or automatic-metrics-based paradigms, each with its own advantages and shortcomings. We introduce "Fusion-Eval", a system that employs LLMs not solely for direct evaluations, but to skillfully integrate insights from diverse evaluators. This gives Fusion-Eval flexibility, enabling it to work effectively across diverse tasks and make optimal use of multiple references. In testing on the SummEval dataset, Fusion-Eval achieved a Spearman correlation of 0.96, outperforming other evaluators. The success of Fusion-Eval underscores the potential of LLMs to produce evaluations that closely align human perspectives, setting a new standard in the field of LLM evaluation.
SiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023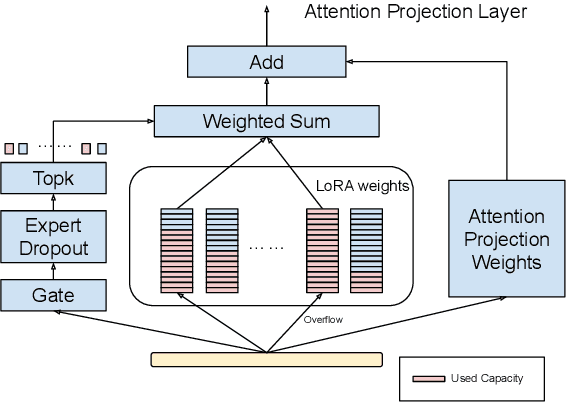



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
Cappy: Outperforming and Boosting Large Multi-Task LMs with a Small Scorer
Nov 12, 2023Large language models (LLMs) such as T0, FLAN, and OPT-IML, excel in multi-tasking under a unified instruction-following paradigm, where they also exhibit remarkable generalization abilities to unseen tasks. Despite their impressive performance, these LLMs, with sizes ranging from several billion to hundreds of billions of parameters, demand substantial computational resources, making their training and inference expensive and inefficient. Furthermore, adapting these models to downstream applications, particularly complex tasks, is often unfeasible due to the extensive hardware requirements for finetuning, even when utilizing parameter-efficient approaches such as prompt tuning. Additionally, the most powerful multi-task LLMs, such as OPT-IML-175B and FLAN-PaLM-540B, are not publicly accessible, severely limiting their customization potential. To address these challenges, we introduce a pretrained small scorer, Cappy, designed to enhance the performance and efficiency of multi-task LLMs. With merely 360 million parameters, Cappy functions either independently on classification tasks or serve as an auxiliary component for LLMs, boosting their performance. Moreover, Cappy enables efficiently integrating downstream supervision without requiring LLM finetuning nor the access to their parameters. Our experiments demonstrate that, when working independently on 11 language understanding tasks from PromptSource, Cappy outperforms LLMs that are several orders of magnitude larger. Besides, on 45 complex tasks from BIG-Bench, Cappy boosts the performance of the advanced multi-task LLM, FLAN-T5, by a large margin. Furthermore, Cappy is flexible to cooperate with other LLM adaptations, including finetuning and in-context learning, offering additional performance enhancement.
Redco: A Lightweight Tool to Automate Distributed Training of LLMs on Any GPU/TPUs
Oct 25, 2023The recent progress of AI can be largely attributed to large language models (LLMs). However, their escalating memory requirements introduce challenges for machine learning (ML) researchers and engineers. Addressing this requires developers to partition a large model to distribute it across multiple GPUs or TPUs. This necessitates considerable coding and intricate configuration efforts with existing model parallel tools, such as Megatron-LM, DeepSpeed, and Alpa. These tools require users' expertise in machine learning systems (MLSys), creating a bottleneck in LLM development, particularly for developers without MLSys background. In this work, we present Redco, a lightweight and user-friendly tool crafted to automate distributed training and inference for LLMs, as well as to simplify ML pipeline development. The design of Redco emphasizes two key aspects. Firstly, to automate model parallism, our study identifies two straightforward rules to generate tensor parallel strategies for any given LLM. Integrating these rules into Redco facilitates effortless distributed LLM training and inference, eliminating the need of additional coding or complex configurations. We demonstrate the effectiveness by applying Redco on a set of LLM architectures, such as GPT-J, LLaMA, T5, and OPT, up to the size of 66B. Secondly, we propose a mechanism that allows for the customization of diverse ML pipelines through the definition of merely three functions, eliminating redundant and formulaic code like multi-host related processing. This mechanism proves adaptable across a spectrum of ML algorithms, from foundational language modeling to complex algorithms like meta-learning and reinforcement learning. Consequently, Redco implementations exhibit much fewer code lines compared to their official counterparts.
Towards an On-device Agent for Text Rewriting
Aug 22, 2023



Large Language Models (LLMs) have demonstrated impressive capabilities for text rewriting. Nonetheless, the large sizes of these models make them impractical for on-device inference, which would otherwise allow for enhanced privacy and economical inference. Creating a smaller yet potent language model for text rewriting presents a formidable challenge because it requires balancing the need for a small size with the need to retain the emergent capabilities of the LLM, that requires costly data collection. To address the above challenge, we introduce a new instruction tuning approach for building a mobile-centric text rewriting model. Our strategies enable the generation of high quality training data without any human labeling. In addition, we propose a heuristic reinforcement learning framework which substantially enhances performance without requiring preference data. To further bridge the performance gap with the larger server-side model, we propose an effective approach that combines the mobile rewrite agent with the server model using a cascade. To tailor the text rewriting tasks to mobile scenarios, we introduce MessageRewriteEval, a benchmark that focuses on text rewriting for messages through natural language instructions. Through empirical experiments, we demonstrate that our on-device model surpasses the current state-of-the-art LLMs in text rewriting while maintaining a significantly reduced model size. Notably, we show that our proposed cascading approach improves model performance.
RewriteLM: An Instruction-Tuned Large Language Model for Text Rewriting
May 25, 2023



Large Language Models (LLMs) have demonstrated impressive zero-shot capabilities in long-form text generation tasks expressed through natural language instructions. However, user expectations for long-form text rewriting is high, and unintended rewrites (''hallucinations'') produced by the model can negatively impact its overall performance. Existing evaluation benchmarks primarily focus on limited rewriting styles and sentence-level rewriting rather than long-form open-ended rewriting.We introduce OpenRewriteEval, a novel benchmark that covers a wide variety of rewriting types expressed through natural language instructions. It is specifically designed to facilitate the evaluation of open-ended rewriting of long-form texts. In addition, we propose a strong baseline model, RewriteLM, an instruction-tuned large language model for long-form text rewriting. We develop new strategies that facilitate the generation of diverse instructions and preference data with minimal human intervention. We conduct empirical experiments and demonstrate that our model outperforms the current state-of-the-art LLMs in text rewriting. Specifically, it excels in preserving the essential content and meaning of the source text, minimizing the generation of ''hallucinated'' content, while showcasing the ability to generate rewrites with diverse wording and structures.
DETR++: Taming Your Multi-Scale Detection Transformer
Jun 07, 2022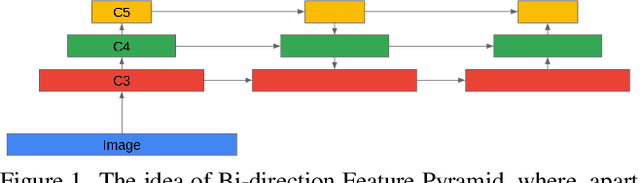
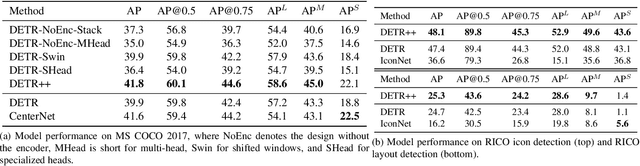
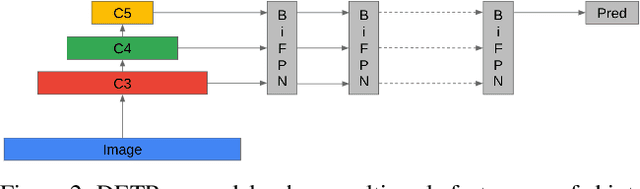
Convolutional Neural Networks (CNN) have dominated the field of detection ever since the success of AlexNet in ImageNet classification [12]. With the sweeping reform of Transformers [27] in natural language processing, Carion et al. [2] introduce the Transformer-based detection method, i.e., DETR. However, due to the quadratic complexity in the self-attention mechanism in the Transformer, DETR is never able to incorporate multi-scale features as performed in existing CNN-based detectors, leading to inferior results in small object detection. To mitigate this issue and further improve performance of DETR, in this work, we investigate different methods to incorporate multi-scale features and find that a Bi-directional Feature Pyramid (BiFPN) works best with DETR in further raising the detection precision. With this discovery, we propose DETR++, a new architecture that improves detection results by 1.9% AP on MS COCO 2017, 11.5% AP on RICO icon detection, and 9.1% AP on RICO layout extraction over existing baselines.