 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyG: Effective and Efficient GraphRAG with Adaptive Graph Traversal
Apr 02, 2025GraphRAG enhances large language models (LLMs) to generate quality answers for user questions by retrieving related facts from external knowledge graphs. Existing GraphRAG methods adopt a fixed graph traversal strategy for fact retrieval but we observe that user questions come in different types and require different graph traversal strategies. As such, existing GraphRAG methods are limited in effectiveness (i.e., quality of the generated answers) and/or efficiency (i.e., response time or the number of used tokens). In this paper, we propose to classify the questions according to a complete four-class taxonomy and adaptively select the appropriate graph traversal strategy for each type of questions. Our system PolyG is essentially a query planner for GraphRAG and can handle diverse questions with an unified interface and execution engine. Compared with SOTA GraphRAG methods, PolyG achieves an overall win rate of 75% on generation quality and a speedup up to 4x on response time.
Proofread: Fixes All Errors with One Tap
Jun 06, 2024The impressive capabilities in Large Language Models (LLMs) provide a powerful approach to reimagine users' typing experience. This paper demonstrates Proofread, a novel Gboard feature powered by a server-side LLM in Gboard, enabling seamless sentence-level and paragraph-level corrections with a single tap. We describe the complete system in this paper, from data generation, metrics design to model tuning and deployment. To obtain models with sufficient quality, we implement a careful data synthetic pipeline tailored to online use cases, design multifaceted metrics, employ a two-stage tuning approach to acquire the dedicated LLM for the feature: the Supervised Fine Tuning (SFT) for foundational quality, followed by the Reinforcement Learning (RL) tuning approach for targeted refinement. Specifically, we find sequential tuning on Rewrite and proofread tasks yields the best quality in SFT stage, and propose global and direct rewards in the RL tuning stage to seek further improvement. Extensive experiments on a human-labeled golden set showed our tuned PaLM2-XS model achieved 85.56\% good ratio. We launched the feature to Pixel 8 devices by serving the model on TPU v5 in Google Cloud, with thousands of daily active users. Serving latency was significantly reduced by quantization, bucket inference, text segmentation, and speculative decoding. Our demo could be seen in \href{https://youtu.be/4ZdcuiwFU7I}{Youtube}.
DiskGNN: Bridging I/O Efficiency and Model Accuracy for Out-of-Core GNN Training
May 08, 2024



Graph neural networks (GNNs) are machine learning models specialized for graph data and widely used in many applications. To train GNNs on large graphs that exceed CPU memory, several systems store data on disk and conduct out-of-core processing. However, these systems suffer from either read amplification when reading node features that are usually smaller than a disk page or degraded model accuracy by treating the graph as disconnected partitions. To close this gap, we build a system called DiskGNN, which achieves high I/O efficiency and thus fast training without hurting model accuracy. The key technique used by DiskGNN is offline sampling, which helps decouple graph sampling from model computation. In particular, by conducting graph sampling beforehand, DiskGNN acquires the node features that will be accessed by model computation, and such information is utilized to pack the target node features contiguously on disk to avoid read amplification. Besides, \name{} also adopts designs including four-level feature store to fully utilize the memory hierarchy to cache node features and reduce disk access, batched packing to accelerate the feature packing process, and pipelined training to overlap disk access with other operations. We compare DiskGNN with Ginex and MariusGNN, which are state-of-the-art systems for out-of-core GNN training. The results show that DiskGNN can speed up the baselines by over 8x while matching their best model accuracy.
MuseGNN: Interpretable and Convergent Graph Neural Network Layers at Scale
Oct 19, 2023Among the many variants of graph neural network (GNN) architectures capable of modeling data with cross-instance relations, an important subclass involves layers designed such that the forward pass iteratively reduces a graph-regularized energy function of interest. In this way, node embeddings produced at the output layer dually serve as both predictive features for solving downstream tasks (e.g., node classification) and energy function minimizers that inherit desirable inductive biases and interpretability. However, scaling GNN architectures constructed in this way remains challenging, in part because the convergence of the forward pass may involve models with considerable depth. To tackle this limitation, we propose a sampling-based energy function and scalable GNN layers that iteratively reduce it, guided by convergence guarantees in certain settings. We also instantiate a full GNN architecture based on these designs, and the model achieves competitive accuracy and scalability when applied to the largest publicly-available node classification benchmark exceeding 1TB in size.
Towards an On-device Agent for Text Rewriting
Aug 22, 2023



Large Language Models (LLMs) have demonstrated impressive capabilities for text rewriting. Nonetheless, the large sizes of these models make them impractical for on-device inference, which would otherwise allow for enhanced privacy and economical inference. Creating a smaller yet potent language model for text rewriting presents a formidable challenge because it requires balancing the need for a small size with the need to retain the emergent capabilities of the LLM, that requires costly data collection. To address the above challenge, we introduce a new instruction tuning approach for building a mobile-centric text rewriting model. Our strategies enable the generation of high quality training data without any human labeling. In addition, we propose a heuristic reinforcement learning framework which substantially enhances performance without requiring preference data. To further bridge the performance gap with the larger server-side model, we propose an effective approach that combines the mobile rewrite agent with the server model using a cascade. To tailor the text rewriting tasks to mobile scenarios, we introduce MessageRewriteEval, a benchmark that focuses on text rewriting for messages through natural language instructions. Through empirical experiments, we demonstrate that our on-device model surpasses the current state-of-the-art LLMs in text rewriting while maintaining a significantly reduced model size. Notably, we show that our proposed cascading approach improves model performance.
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020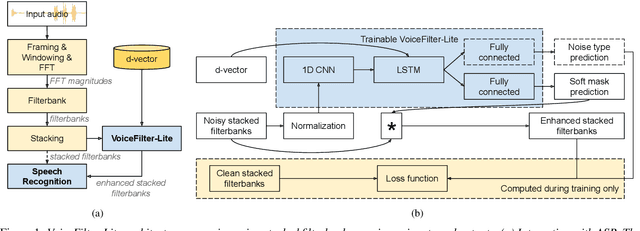

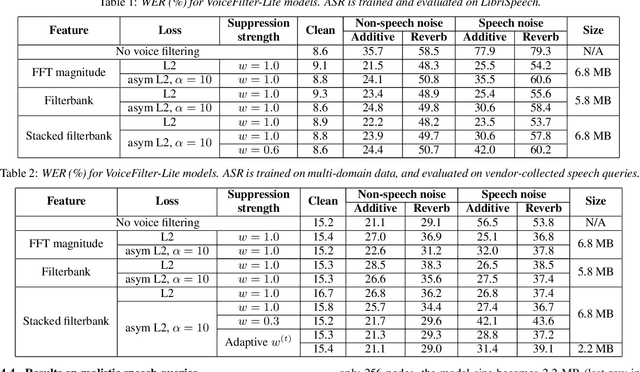
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices
Apr 14, 2020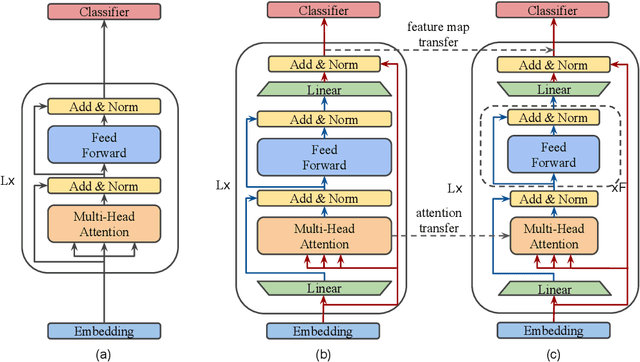
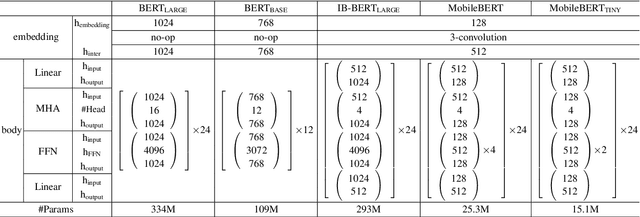
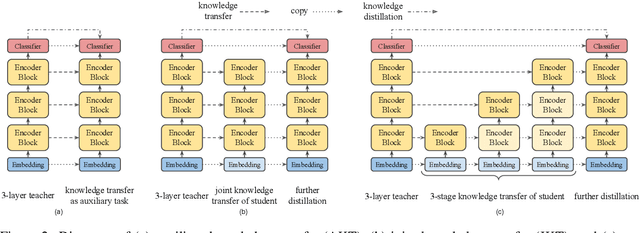
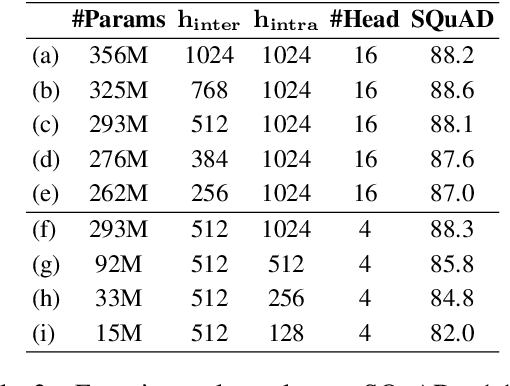
Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot be deployed to resource-limited mobile devices. In this paper, we propose MobileBERT for compressing and accelerating the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks. To train MobileBERT, we first train a specially designed teacher model, an inverted-bottleneck incorporated BERT_LARGE model. Then, we conduct knowledge transfer from this teacher to MobileBERT. Empirical studies show that MobileBERT is 4.3x smaller and 5.5x faster than BERT_BASE while achieving competitive results on well-known benchmarks. On the natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7 (0.6 lower than BERT_BASE), and 62 ms latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of 90.0/79.2 (1.5/2.1 higher than BERT_BASE).