 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTrace: Lightweight Error Checking and Diagnosis for Distributed Training
Jun 10, 2025Distributed training is essential for scaling the training of large neural network models, such as large language models (LLMs), across thousands of GPUs. However, the complexity of distributed training programs makes them particularly prone to silent bugs, which do not produce explicit error signal but lead to incorrect training outcome. Effectively detecting and localizing such silent bugs in distributed training is challenging. Common debugging practice using metrics like training loss or gradient norm curves can be inefficient and ineffective. Additionally, obtaining intermediate tensor values and determining whether they are correct during silent bug localization is difficult, particularly in the context of low-precision training. To address those challenges, we design and implement TTrace, the first system capable of detecting and localizing silent bugs in distributed training. TTrace collects intermediate tensors from distributing training in a fine-grained manner and compares them against those from a trusted single-device reference implementation. To properly compare the floating-point values in the tensors, we propose novel mathematical analysis that provides a guideline for setting thresholds, enabling TTrace to distinguish bug-induced errors from floating-point round-off errors. Experimental results demonstrate that TTrace effectively detects 11 existing bugs and 3 new bugs in the widely used Megatron-LM framework, while requiring fewer than 10 lines of code change. TTrace is effective in various training recipes, including low-precision recipes involving BF16 and FP8.
PolyG: Effective and Efficient GraphRAG with Adaptive Graph Traversal
Apr 02, 2025GraphRAG enhances large language models (LLMs) to generate quality answers for user questions by retrieving related facts from external knowledge graphs. Existing GraphRAG methods adopt a fixed graph traversal strategy for fact retrieval but we observe that user questions come in different types and require different graph traversal strategies. As such, existing GraphRAG methods are limited in effectiveness (i.e., quality of the generated answers) and/or efficiency (i.e., response time or the number of used tokens). In this paper, we propose to classify the questions according to a complete four-class taxonomy and adaptively select the appropriate graph traversal strategy for each type of questions. Our system PolyG is essentially a query planner for GraphRAG and can handle diverse questions with an unified interface and execution engine. Compared with SOTA GraphRAG methods, PolyG achieves an overall win rate of 75% on generation quality and a speedup up to 4x on response time.
DiskGNN: Bridging I/O Efficiency and Model Accuracy for Out-of-Core GNN Training
May 08, 2024



Graph neural networks (GNNs) are machine learning models specialized for graph data and widely used in many applications. To train GNNs on large graphs that exceed CPU memory, several systems store data on disk and conduct out-of-core processing. However, these systems suffer from either read amplification when reading node features that are usually smaller than a disk page or degraded model accuracy by treating the graph as disconnected partitions. To close this gap, we build a system called DiskGNN, which achieves high I/O efficiency and thus fast training without hurting model accuracy. The key technique used by DiskGNN is offline sampling, which helps decouple graph sampling from model computation. In particular, by conducting graph sampling beforehand, DiskGNN acquires the node features that will be accessed by model computation, and such information is utilized to pack the target node features contiguously on disk to avoid read amplification. Besides, \name{} also adopts designs including four-level feature store to fully utilize the memory hierarchy to cache node features and reduce disk access, batched packing to accelerate the feature packing process, and pipelined training to overlap disk access with other operations. We compare DiskGNN with Ginex and MariusGNN, which are state-of-the-art systems for out-of-core GNN training. The results show that DiskGNN can speed up the baselines by over 8x while matching their best model accuracy.
MuseGNN: Interpretable and Convergent Graph Neural Network Layers at Scale
Oct 19, 2023



Among the many variants of graph neural network (GNN) architectures capable of modeling data with cross-instance relations, an important subclass involves layers designed such that the forward pass iteratively reduces a graph-regularized energy function of interest. In this way, node embeddings produced at the output layer dually serve as both predictive features for solving downstream tasks (e.g., node classification) and energy function minimizers that inherit desirable inductive biases and interpretability. However, scaling GNN architectures constructed in this way remains challenging, in part because the convergence of the forward pass may involve models with considerable depth. To tackle this limitation, we propose a sampling-based energy function and scalable GNN layers that iteratively reduce it, guided by convergence guarantees in certain settings. We also instantiate a full GNN architecture based on these designs, and the model achieves competitive accuracy and scalability when applied to the largest publicly-available node classification benchmark exceeding 1TB in size.
Simplifying and Empowering Transformers for Large-Graph Representations
Jun 19, 2023Learning representations on large-sized graphs is a long-standing challenge due to the inter-dependence nature involved in massive data points. Transformers, as an emerging class of foundation encoders for graph-structured data, have shown promising performance on small graphs due to its global attention capable of capturing all-pair influence beyond neighboring nodes. Even so, existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated models by stacking deep multi-head attentions. In this paper, we critically demonstrate that even using a one-layer attention can bring up surprisingly competitive performance across node property prediction benchmarks where node numbers range from thousand-level to billion-level. This encourages us to rethink the design philosophy for Transformers on large graphs, where the global attention is a computation overhead hindering the scalability. We frame the proposed scheme as Simplified Graph Transformers (SGFormer), which is empowered by a simple attention model that can efficiently propagate information among arbitrary nodes in one layer. SGFormer requires none of positional encodings, feature/graph pre-processing or augmented loss. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M and yields up to 141x inference acceleration over SOTA Transformers on medium-sized graphs. Beyond current results, we believe the proposed methodology alone enlightens a new technical path of independent interest for building Transformers on large graphs.
Efficient Halftoning via Deep Reinforcement Learning
Apr 24, 2023



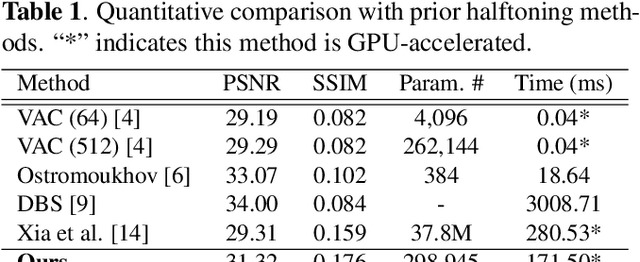
Halftoning aims to reproduce a continuous-tone image with pixels whose intensities are constrained to two discrete levels. This technique has been deployed on every printer, and the majority of them adopt fast methods (e.g., ordered dithering, error diffusion) that fail to render structural details, which determine halftone's quality. Other prior methods of pursuing visual pleasure by searching for the optimal halftone solution, on the contrary, suffer from their high computational cost. In this paper, we propose a fast and structure-aware halftoning method via a data-driven approach. Specifically, we formulate halftoning as a reinforcement learning problem, in which each binary pixel's value is regarded as an action chosen by a virtual agent with a shared fully convolutional neural network (CNN) policy. In the offline phase, an effective gradient estimator is utilized to train the agents in producing high-quality halftones in one action step. Then, halftones can be generated online by one fast CNN inference. Besides, we propose a novel anisotropy suppressing loss function, which brings the desirable blue-noise property. Finally, we find that optimizing SSIM could result in holes in flat areas, which can be avoided by weighting the metric with the contone's contrast map. Experiments show that our framework can effectively train a light-weight CNN, which is 15x faster than previous structure-aware methods, to generate blue-noise halftones with satisfactory visual quality. We also present a prototype of deep multitoning to demonstrate the extensibility of our method.
ReFresh: Reducing Memory Access from Exploiting Stable Historical Embeddings for Graph Neural Network Training
Jan 19, 2023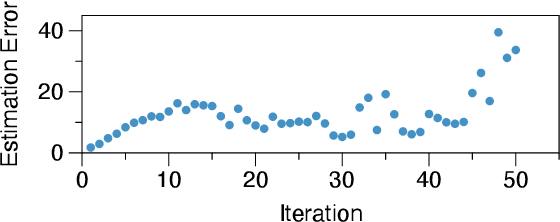


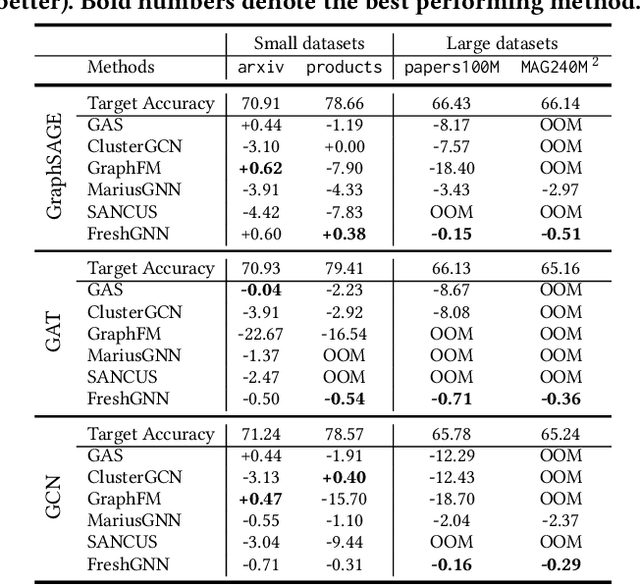
A key performance bottleneck when training graph neural network (GNN) models on large, real-world graphs is loading node features onto a GPU. Due to limited GPU memory, expensive data movement is necessary to facilitate the storage of these features on alternative devices with slower access (e.g. CPU memory). Moreover, the irregularity of graph structures contributes to poor data locality which further exacerbates the problem. Consequently, existing frameworks capable of efficiently training large GNN models usually incur a significant accuracy degradation because of the inevitable shortcuts involved. To address these limitations, we instead propose ReFresh, a general-purpose GNN mini-batch training framework that leverages a historical cache for storing and reusing GNN node embeddings instead of re-computing them through fetching raw features at every iteration. Critical to its success, the corresponding cache policy is designed, using a combination of gradient-based and staleness criteria, to selectively screen those embeddings which are relatively stable and can be cached, from those that need to be re-computed to reduce estimation errors and subsequent downstream accuracy loss. When paired with complementary system enhancements to support this selective historical cache, ReFresh is able to accelerate the training speed on large graph datasets such as ogbn-papers100M and MAG240M by 4.6x up to 23.6x and reduce the memory access by 64.5% (85.7% higher than a raw feature cache), with less than 1% influence on test accuracy.
Halftoning with Multi-Agent Deep Reinforcement Learning
Jul 23, 2022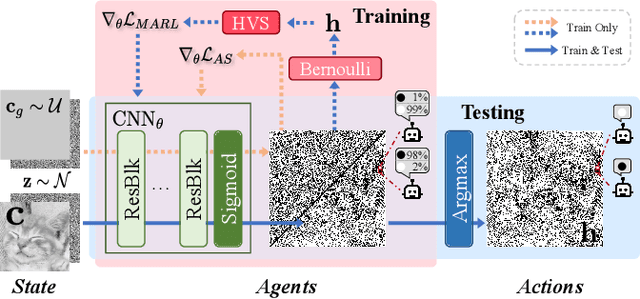
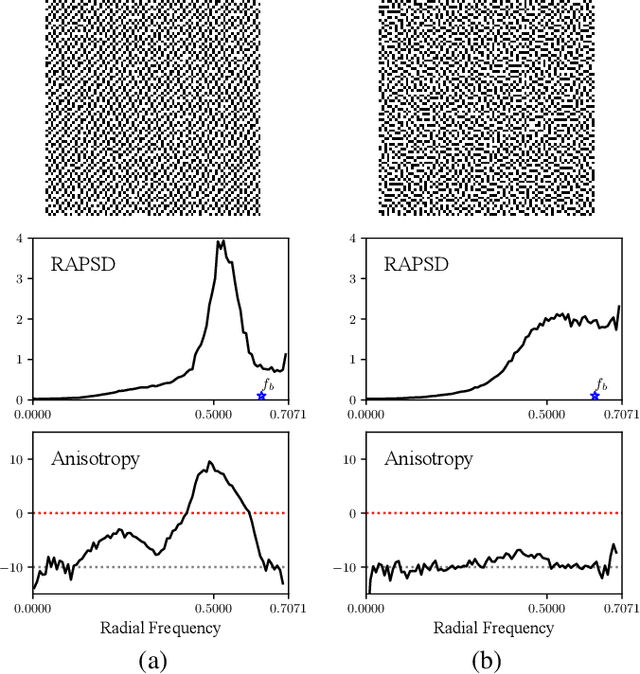

Deep neural networks have recently succeeded in digital halftoning using vanilla convolutional layers with high parallelism. However, existing deep methods fail to generate halftones with a satisfying blue-noise property and require complex training schemes. In this paper, we propose a halftoning method based on multi-agent deep reinforcement learning, called HALFTONERS, which learns a shared policy to generate high-quality halftone images. Specifically, we view the decision of each binary pixel value as an action of a virtual agent, whose policy is trained by a low-variance policy gradient. Moreover, the blue-noise property is achieved by a novel anisotropy suppressing loss function. Experiments show that our halftoning method produces high-quality halftones while staying relatively fast.