 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Training via Spectral Clipping
Mar 15, 2026While spectral-based optimizers like Muon operate directly on the spectrum of updates, standard adaptive methods such as AdamW do not account for the global spectral structure of weights and gradients, leaving them vulnerable to two empirical issues in large language model (LLM) training: (i) the optimizer updates can have large spectral norms, potentially destabilizing training and degrading generalization; (ii) stochastic gradient noise can exhibit sparse spectral spikes, with a few dominant singular values much larger than the rest. We propose SPECTRA, a general framework addressing these by (i) post-spectral clipping of updates to enforce spectral-norm constraints; (ii) optional pre-spectral clipping of gradients to suppress spectral noise spikes. We prove that post-clipping constitutes a Composite Frank-Wolfe method with spectral-norm constraints and weight regularization, recovering Frobenius and $\ell_{\infty}$-norm regularization with SGD-based and sign-based methods. We further analyze how pre-clipping mitigates sparse spectral spikes. We propose efficient soft spectral clipping via Newton-Schulz iterations, avoiding expensive SVD. Experiments on LLM pretraining show SPECTRA uniformly improves validation loss for various optimizers, including AdamW, Signum, and AdEMAMix, with the best-performing variants achieving state-of-the-art results. Models trained with SPECTRA exhibit smaller weight norms, confirming the link between spectral clipping and regularization.
Exploiting Similarity for Computation and Communication-Efficient Decentralized Optimization
Jun 06, 2025Reducing communication complexity is critical for efficient decentralized optimization. The proximal decentralized optimization (PDO) framework is particularly appealing, as methods within this framework can exploit functional similarity among nodes to reduce communication rounds. Specifically, when local functions at different nodes are similar, these methods achieve faster convergence with fewer communication steps. However, existing PDO methods often require highly accurate solutions to subproblems associated with the proximal operator, resulting in significant computational overhead. In this work, we propose the Stabilized Proximal Decentralized Optimization (SPDO) method, which achieves state-of-the-art communication and computational complexities within the PDO framework. Additionally, we refine the analysis of existing PDO methods by relaxing subproblem accuracy requirements and leveraging average functional similarity. Experimental results demonstrate that SPDO significantly outperforms existing methods.
Stabilized Proximal-Point Methods for Federated Optimization
Jul 09, 2024In developing efficient optimization algorithms, it is crucial to account for communication constraints -- a significant challenge in modern federated learning settings. The best-known communication complexity among non-accelerated algorithms is achieved by DANE, a distributed proximal-point algorithm that solves local subproblems in each iteration and that can exploit second-order similarity among individual functions. However, to achieve such communication efficiency, the accuracy requirement for solving the local subproblems is slightly sub-optimal. Inspired by the hybrid projection-proximal point method, in this work, we i) propose a novel distributed algorithm S-DANE. This method adopts a more stabilized prox-center in the proximal step compared with DANE, and matches its deterministic communication complexity. Moreover, the accuracy condition of the subproblem is milder, leading to enhanced local computation efficiency. Furthermore, it supports partial client participation and arbitrary stochastic local solvers, making it more attractive in practice. We further ii) accelerate S-DANE, and show that the resulting algorithm achieves the best-known communication complexity among all existing methods for distributed convex optimization, with the same improved local computation efficiency as S-DANE.
Federated Optimization with Doubly Regularized Drift Correction
Apr 12, 2024Federated learning is a distributed optimization paradigm that allows training machine learning models across decentralized devices while keeping the data localized. The standard method, FedAvg, suffers from client drift which can hamper performance and increase communication costs over centralized methods. Previous works proposed various strategies to mitigate drift, yet none have shown uniformly improved communication-computation trade-offs over vanilla gradient descent. In this work, we revisit DANE, an established method in distributed optimization. We show that (i) DANE can achieve the desired communication reduction under Hessian similarity constraints. Furthermore, (ii) we present an extension, DANE+, which supports arbitrary inexact local solvers and has more freedom to choose how to aggregate the local updates. We propose (iii) a novel method, FedRed, which has improved local computational complexity and retains the same communication complexity compared to DANE/DANE+. This is achieved by using doubly regularized drift correction.
Adaptive SGD with Polyak stepsize and Line-search: Robust Convergence and Variance Reduction
Aug 21, 2023The recently proposed stochastic Polyak stepsize (SPS) and stochastic line-search (SLS) for SGD have shown remarkable effectiveness when training over-parameterized models. However, in non-interpolation settings, both algorithms only guarantee convergence to a neighborhood of a solution which may result in a worse output than the initial guess. While artificially decreasing the adaptive stepsize has been proposed to address this issue (Orvieto et al. [2022]), this approach results in slower convergence rates for convex and over-parameterized models. In this work, we make two contributions: Firstly, we propose two new variants of SPS and SLS, called AdaSPS and AdaSLS, which guarantee convergence in non-interpolation settings and maintain sub-linear and linear convergence rates for convex and strongly convex functions when training over-parameterized models. AdaSLS requires no knowledge of problem-dependent parameters, and AdaSPS requires only a lower bound of the optimal function value as input. Secondly, we equip AdaSPS and AdaSLS with a novel variance reduction technique and obtain algorithms that require $\smash{\widetilde{\mathcal{O}}}(n+1/\epsilon)$ gradient evaluations to achieve an $\mathcal{O}(\epsilon)$-suboptimality for convex functions, which improves upon the slower $\mathcal{O}(1/\epsilon^2)$ rates of AdaSPS and AdaSLS without variance reduction in the non-interpolation regimes. Moreover, our result matches the fast rates of AdaSVRG but removes the inner-outer-loop structure, which is easier to implement and analyze. Finally, numerical experiments on synthetic and real datasets validate our theory and demonstrate the effectiveness and robustness of our algorithms.
Efficient Halftoning via Deep Reinforcement Learning
Apr 24, 2023



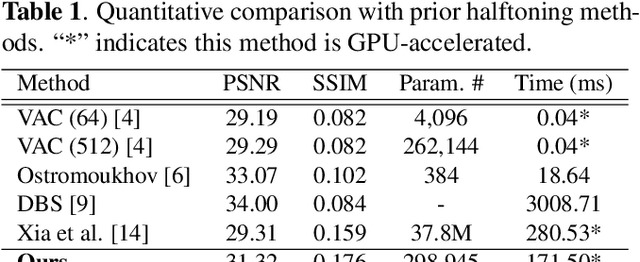
Halftoning aims to reproduce a continuous-tone image with pixels whose intensities are constrained to two discrete levels. This technique has been deployed on every printer, and the majority of them adopt fast methods (e.g., ordered dithering, error diffusion) that fail to render structural details, which determine halftone's quality. Other prior methods of pursuing visual pleasure by searching for the optimal halftone solution, on the contrary, suffer from their high computational cost. In this paper, we propose a fast and structure-aware halftoning method via a data-driven approach. Specifically, we formulate halftoning as a reinforcement learning problem, in which each binary pixel's value is regarded as an action chosen by a virtual agent with a shared fully convolutional neural network (CNN) policy. In the offline phase, an effective gradient estimator is utilized to train the agents in producing high-quality halftones in one action step. Then, halftones can be generated online by one fast CNN inference. Besides, we propose a novel anisotropy suppressing loss function, which brings the desirable blue-noise property. Finally, we find that optimizing SSIM could result in holes in flat areas, which can be avoided by weighting the metric with the contone's contrast map. Experiments show that our framework can effectively train a light-weight CNN, which is 15x faster than previous structure-aware methods, to generate blue-noise halftones with satisfactory visual quality. We also present a prototype of deep multitoning to demonstrate the extensibility of our method.
Halftoning with Multi-Agent Deep Reinforcement Learning
Jul 23, 2022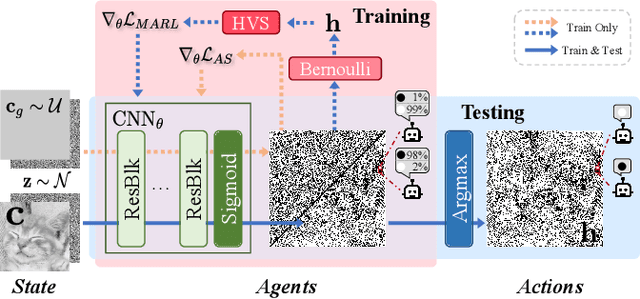
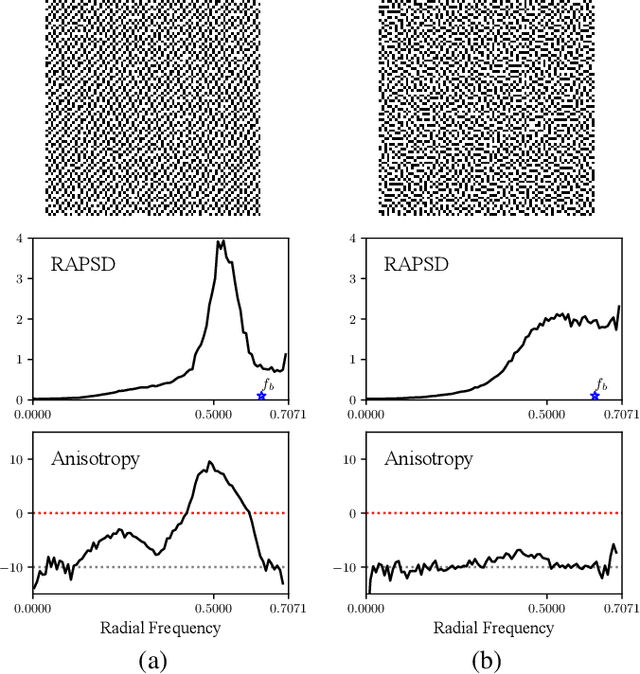

Deep neural networks have recently succeeded in digital halftoning using vanilla convolutional layers with high parallelism. However, existing deep methods fail to generate halftones with a satisfying blue-noise property and require complex training schemes. In this paper, we propose a halftoning method based on multi-agent deep reinforcement learning, called HALFTONERS, which learns a shared policy to generate high-quality halftone images. Specifically, we view the decision of each binary pixel value as an action of a virtual agent, whose policy is trained by a low-variance policy gradient. Moreover, the blue-noise property is achieved by a novel anisotropy suppressing loss function. Experiments show that our halftoning method produces high-quality halftones while staying relatively fast.
A Low Memory Footprint Quantized Neural Network for Depth Completion of Very Sparse Time-of-Flight Depth Maps
May 25, 2022
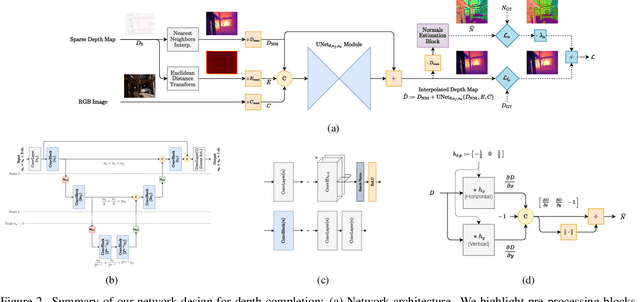
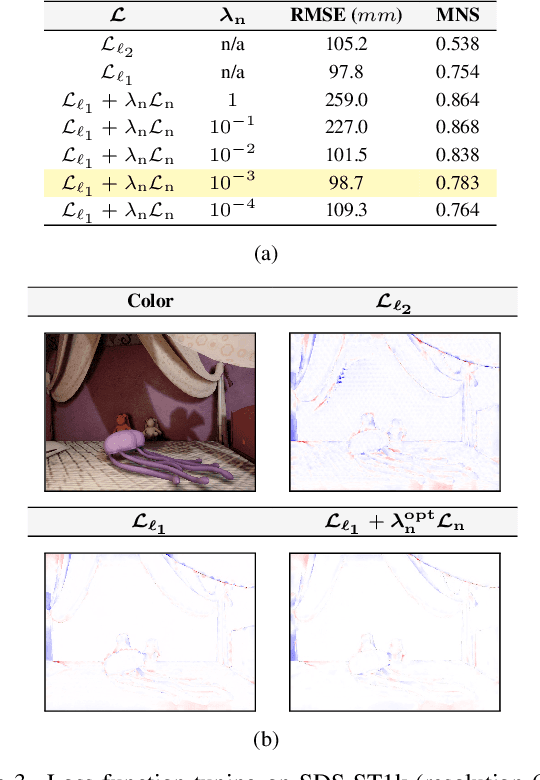
Sparse active illumination enables precise time-of-flight depth sensing as it maximizes signal-to-noise ratio for low power budgets. However, depth completion is required to produce dense depth maps for 3D perception. We address this task with realistic illumination and sensor resolution constraints by simulating ToF datasets for indoor 3D perception with challenging sparsity levels. We propose a quantized convolutional encoder-decoder network for this task. Our model achieves optimal depth map quality by means of input pre-processing and carefully tuned training with a geometry-preserving loss function. We also achieve low memory footprint for weights and activations by means of mixed precision quantization-at-training techniques. The resulting quantized models are comparable to the state of the art in terms of quality, but they require very low GPU times and achieve up to 14-fold memory size reduction for the weights w.r.t. their floating point counterpart with minimal impact on quality metrics.