 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodalStudio: A Heterogeneous Sensor Dataset and Framework for Neural Rendering across Multiple Imaging Modalities
Mar 25, 2025



Neural Radiance Fields (NeRF) have shown impressive performances in the rendering of 3D scenes from arbitrary viewpoints. While RGB images are widely preferred for training volume rendering models, the interest in other radiance modalities is also growing. However, the capability of the underlying implicit neural models to learn and transfer information across heterogeneous imaging modalities has seldom been explored, mostly due to the limited training data availability. For this purpose, we present MultimodalStudio (MMS): it encompasses MMS-DATA and MMS-FW. MMS-DATA is a multimodal multi-view dataset containing 32 scenes acquired with 5 different imaging modalities: RGB, monochrome, near-infrared, polarization and multispectral. MMS-FW is a novel modular multimodal NeRF framework designed to handle multimodal raw data and able to support an arbitrary number of multi-channel devices. Through extensive experiments, we demonstrate that MMS-FW trained on MMS-DATA can transfer information between different imaging modalities and produce higher quality renderings than using single modalities alone. We publicly release the dataset and the framework, to promote the research on multimodal volume rendering and beyond.
NIGHT -- Non-Line-of-Sight Imaging from Indirect Time of Flight Data
Mar 28, 2024



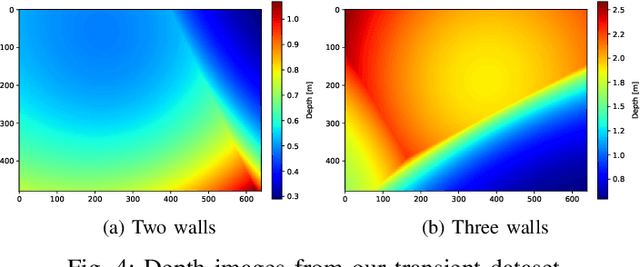
The acquisition of objects outside the Line-of-Sight of cameras is a very intriguing but also extremely challenging research topic. Recent works showed the feasibility of this idea exploiting transient imaging data produced by custom direct Time of Flight sensors. In this paper, for the first time, we tackle this problem using only data from an off-the-shelf indirect Time of Flight sensor without any further hardware requirement. We introduced a Deep Learning model able to re-frame the surfaces where light bounces happen as a virtual mirror. This modeling makes the task easier to handle and also facilitates the construction of annotated training data. From the obtained data it is possible to retrieve the depth information of the hidden scene. We also provide a first-in-its-kind synthetic dataset for the task and demonstrate the feasibility of the proposed idea over it.
Exploiting Multiple Priors for Neural 3D Indoor Reconstruction
Sep 13, 2023Neural implicit modeling permits to achieve impressive 3D reconstruction results on small objects, while it exhibits significant limitations in large indoor scenes. In this work, we propose a novel neural implicit modeling method that leverages multiple regularization strategies to achieve better reconstructions of large indoor environments, while relying only on images. A sparse but accurate depth prior is used to anchor the scene to the initial model. A dense but less accurate depth prior is also introduced, flexible enough to still let the model diverge from it to improve the estimated geometry. Then, a novel self-supervised strategy to regularize the estimated surface normals is presented. Finally, a learnable exposure compensation scheme permits to cope with challenging lighting conditions. Experimental results show that our approach produces state-of-the-art 3D reconstructions in challenging indoor scenarios.
A Low Memory Footprint Quantized Neural Network for Depth Completion of Very Sparse Time-of-Flight Depth Maps
May 25, 2022
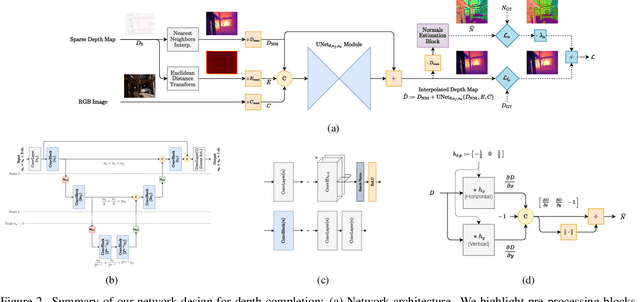
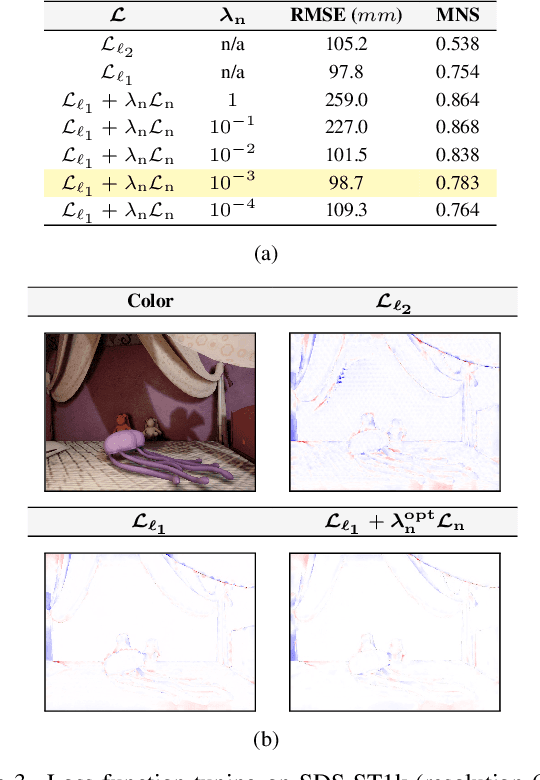
Sparse active illumination enables precise time-of-flight depth sensing as it maximizes signal-to-noise ratio for low power budgets. However, depth completion is required to produce dense depth maps for 3D perception. We address this task with realistic illumination and sensor resolution constraints by simulating ToF datasets for indoor 3D perception with challenging sparsity levels. We propose a quantized convolutional encoder-decoder network for this task. Our model achieves optimal depth map quality by means of input pre-processing and carefully tuned training with a geometry-preserving loss function. We also achieve low memory footprint for weights and activations by means of mixed precision quantization-at-training techniques. The resulting quantized models are comparable to the state of the art in terms of quality, but they require very low GPU times and achieve up to 14-fold memory size reduction for the weights w.r.t. their floating point counterpart with minimal impact on quality metrics.
Lightweight Deep Learning Architecture for MPI Correction and Transient Reconstruction
Nov 29, 2021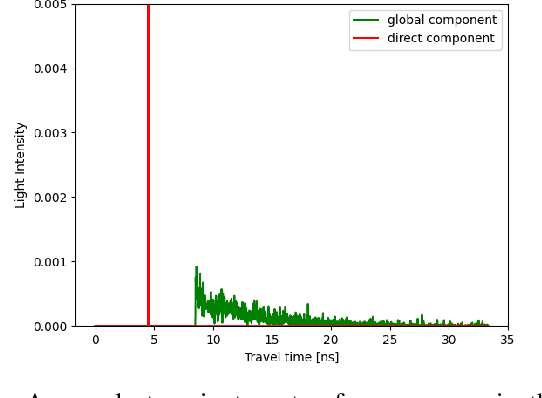
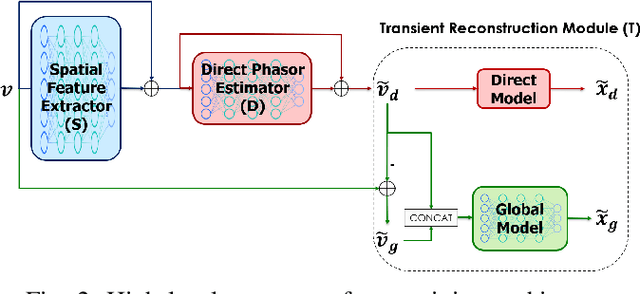
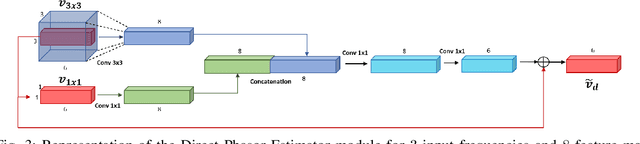
Indirect Time-of-Flight cameras (iToF) are low-cost devices that provide depth images at an interactive frame rate. However, they are affected by different error sources, with the spotlight taken by Multi-Path Interference (MPI), a key challenge for this technology. Common data-driven approaches tend to focus on a direct estimation of the output depth values, ignoring the underlying transient propagation of the light in the scene. In this work instead, we propose a very compact architecture, leveraging on the direct-global subdivision of transient information for the removal of MPI and for the reconstruction of the transient information itself. The proposed model reaches state-of-the-art MPI correction performances both on synthetic and real data and proves to be very competitive also at extreme levels of noise; at the same time, it also makes a step towards reconstructing transient information from multi-frequency iToF data.
Unsupervised Domain Adaptation for Mobile Semantic Segmentation based on Cycle Consistency and Feature Alignment
Jan 14, 2020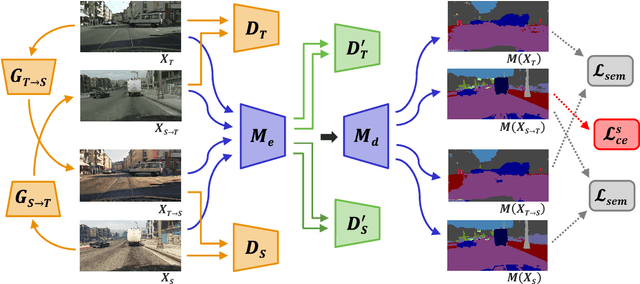


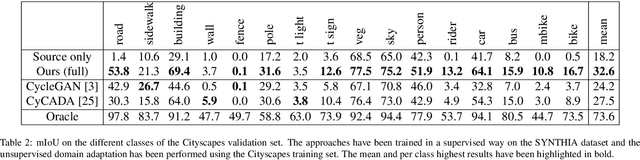
The supervised training of deep networks for semantic segmentation requires a huge amount of labeled real world data. To solve this issue, a commonly exploited workaround is to use synthetic data for training, but deep networks show a critical performance drop when analyzing data with slightly different statistical properties with respect to the training set. In this work, we propose a novel Unsupervised Domain Adaptation (UDA) strategy to address the domain shift issue between real world and synthetic representations. An adversarial model, based on the cycle consistency framework, performs the mapping between the synthetic and real domain. The data is then fed to a MobileNet-v2 architecture that performs the semantic segmentation task. An additional couple of discriminators, working at the feature level of the MobileNet-v2, allows to better align the features of the two domain distributions and to further improve the performance. Finally, the consistency of the semantic maps is exploited. After an initial supervised training on synthetic data, the whole UDA architecture is trained end-to-end considering all its components at once. Experimental results show how the proposed strategy is able to obtain impressive performance in adapting a segmentation network trained on synthetic data to real world scenarios. The usage of the lightweight MobileNet-v2 architecture allows its deployment on devices with limited computational resources as the ones employed in autonomous vehicles.
Adversarial Learning and Self-Teaching Techniques for Domain Adaptation in Semantic Segmentation
Sep 02, 2019


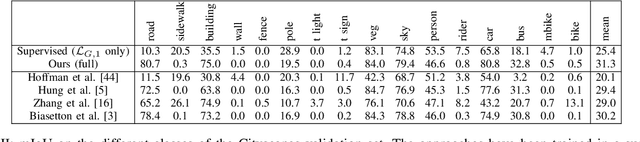
Deep learning techniques have been widely used in autonomous driving systems for the semantic understanding of urban scenes, however they need a huge amount of labeled data for training, which is difficult and expensive to acquire. A recently proposed workaround is to train deep networks using synthetic data, however the domain shift between real world and synthetic representations limits the performance. In this work a novel unsupervised domain adaptation strategy is introduced to solve this issue. The proposed learning strategy is driven by three components: a standard supervised learning loss on labeled synthetic data, an adversarial learning module that exploits both labeled synthetic data and unlabeled real data and finally a self-teaching strategy exploiting unlabeled data. The last component exploits a region growing framework guided by the segmentation confidence. Furthermore, we weighted this component on the basis of the class frequencies to enhance the performance on less common classes. Experimental results prove the effectiveness of the proposed strategy in adapting a segmentation network trained on synthetic datasets, like GTA5 and SYNTHIA, to real world datasets like Cityscapes and Mapillary.