 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit&Splat: Zero-Shot Panoptic Segmentation via Explicit Instance Modeling and 3D Gaussian Splatting
Feb 01, 20263D Gaussian Splatting (GS) enables fast and high-quality scene reconstruction, but it lacks an object-consistent and semantically aware structure. We propose Split&Splat, a framework for panoptic scene reconstruction using 3DGS. Our approach explicitly models object instances. It first propagates instance masks across views using depth, thus producing view-consistent 2D masks. Each object is then reconstructed independently and merged back into the scene while refining its boundaries. Finally, instance-level semantic descriptors are embedded in the reconstructed objects, supporting various applications, including panoptic segmentation, object retrieval, and 3D editing. Unlike existing methods, Split&Splat tackles the problem by first segmenting the scene and then reconstructing each object individually. This design naturally supports downstream tasks and allows Split&Splat to achieve state-of-the-art performance on the ScanNetv2 segmentation benchmark.
MultimodalStudio: A Heterogeneous Sensor Dataset and Framework for Neural Rendering across Multiple Imaging Modalities
Mar 25, 2025



Neural Radiance Fields (NeRF) have shown impressive performances in the rendering of 3D scenes from arbitrary viewpoints. While RGB images are widely preferred for training volume rendering models, the interest in other radiance modalities is also growing. However, the capability of the underlying implicit neural models to learn and transfer information across heterogeneous imaging modalities has seldom been explored, mostly due to the limited training data availability. For this purpose, we present MultimodalStudio (MMS): it encompasses MMS-DATA and MMS-FW. MMS-DATA is a multimodal multi-view dataset containing 32 scenes acquired with 5 different imaging modalities: RGB, monochrome, near-infrared, polarization and multispectral. MMS-FW is a novel modular multimodal NeRF framework designed to handle multimodal raw data and able to support an arbitrary number of multi-channel devices. Through extensive experiments, we demonstrate that MMS-FW trained on MMS-DATA can transfer information between different imaging modalities and produce higher quality renderings than using single modalities alone. We publicly release the dataset and the framework, to promote the research on multimodal volume rendering and beyond.
From Open-Vocabulary to Vocabulary-Free Semantic Segmentation
Feb 17, 2025Open-vocabulary semantic segmentation enables models to identify novel object categories beyond their training data. While this flexibility represents a significant advancement, current approaches still rely on manually specified class names as input, creating an inherent bottleneck in real-world applications. This work proposes a Vocabulary-Free Semantic Segmentation pipeline, eliminating the need for predefined class vocabularies. Specifically, we address the chicken-and-egg problem where users need knowledge of all potential objects within a scene to identify them, yet the purpose of segmentation is often to discover these objects. The proposed approach leverages Vision-Language Models to automatically recognize objects and generate appropriate class names, aiming to solve the challenge of class specification and naming quality. Through extensive experiments on several public datasets, we highlight the crucial role of the text encoder in model performance, particularly when the image text classes are paired with generated descriptions. Despite the challenges introduced by the sensitivity of the segmentation text encoder to false negatives within the class tagging process, which adds complexity to the task, we demonstrate that our fully automated pipeline significantly enhances vocabulary-free segmentation accuracy across diverse real-world scenarios.
LoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
Dec 06, 2024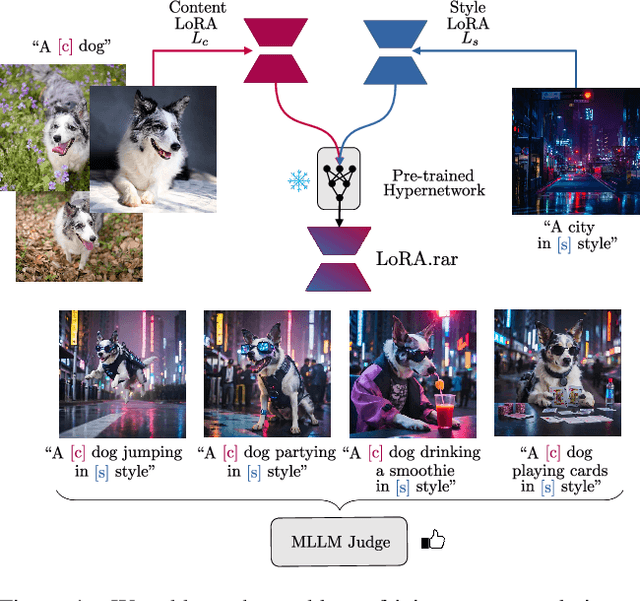
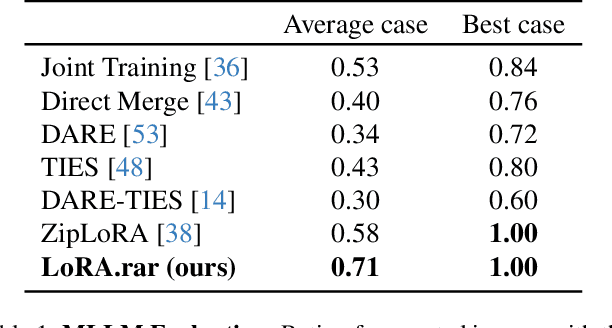
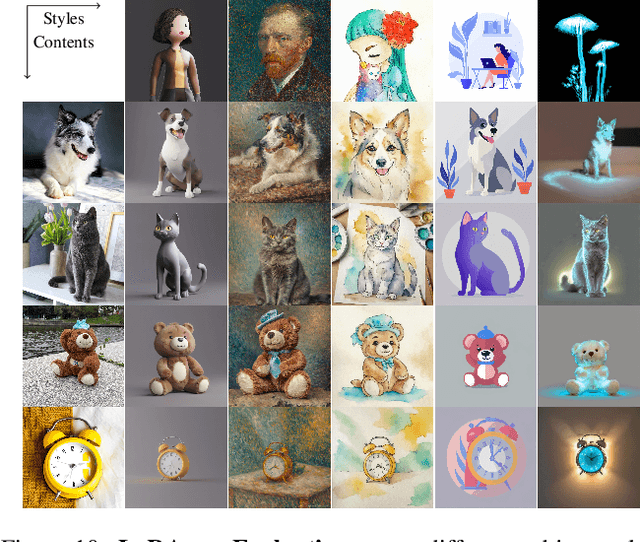
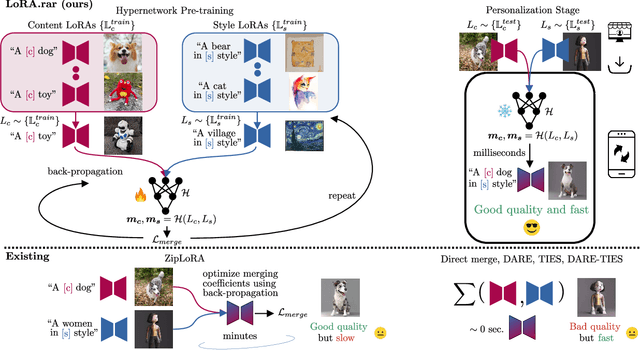
Recent advancements in image generation models have enabled personalized image creation with both user-defined subjects (content) and styles. Prior works achieved personalization by merging corresponding low-rank adaptation parameters (LoRAs) through optimization-based methods, which are computationally demanding and unsuitable for real-time use on resource-constrained devices like smartphones. To address this, we introduce LoRA$.$rar, a method that not only improves image quality but also achieves a remarkable speedup of over $4000\times$ in the merging process. LoRA$.$rar pre-trains a hypernetwork on a diverse set of content-style LoRA pairs, learning an efficient merging strategy that generalizes to new, unseen content-style pairs, enabling fast, high-quality personalization. Moreover, we identify limitations in existing evaluation metrics for content-style quality and propose a new protocol using multimodal large language models (MLLM) for more accurate assessment. Our method significantly outperforms the current state of the art in both content and style fidelity, as validated by MLLM assessments and human evaluations.
Learning from the Web: Language Drives Weakly-Supervised Incremental Learning for Semantic Segmentation
Jul 18, 2024



Current weakly-supervised incremental learning for semantic segmentation (WILSS) approaches only consider replacing pixel-level annotations with image-level labels, while the training images are still from well-designed datasets. In this work, we argue that widely available web images can also be considered for the learning of new classes. To achieve this, firstly we introduce a strategy to select web images which are similar to previously seen examples in the latent space using a Fourier-based domain discriminator. Then, an effective caption-driven reharsal strategy is proposed to preserve previously learnt classes. To our knowledge, this is the first work to rely solely on web images for both the learning of new concepts and the preservation of the already learned ones in WILSS. Experimental results show that the proposed approach can reach state-of-the-art performances without using manually selected and annotated data in the incremental steps.
Cross-Architecture Auxiliary Feature Space Translation for Efficient Few-Shot Personalized Object Detection
Jul 01, 2024Recent years have seen object detection robotic systems deployed in several personal devices (e.g., home robots and appliances). This has highlighted a challenge in their design, i.e., they cannot efficiently update their knowledge to distinguish between general classes and user-specific instances (e.g., a dog vs. user's dog). We refer to this challenging task as Instance-level Personalized Object Detection (IPOD). The personalization task requires many samples for model tuning and optimization in a centralized server, raising privacy concerns. An alternative is provided by approaches based on recent large-scale Foundation Models, but their compute costs preclude on-device applications. In our work we tackle both problems at the same time, designing a Few-Shot IPOD strategy called AuXFT. We introduce a conditional coarse-to-fine few-shot learner to refine the coarse predictions made by an efficient object detector, showing that using an off-the-shelf model leads to poor personalization due to neural collapse. Therefore, we introduce a Translator block that generates an auxiliary feature space where features generated by a self-supervised model (e.g., DINOv2) are distilled without impacting the performance of the detector. We validate AuXFT on three publicly available datasets and one in-house benchmark designed for the IPOD task, achieving remarkable gains in all considered scenarios with excellent time-complexity trade-off: AuXFT reaches a performance of 80% its upper bound at just 32% of the inference time, 13% of VRAM and 19% of the model size.
NIGHT -- Non-Line-of-Sight Imaging from Indirect Time of Flight Data
Mar 28, 2024



The acquisition of objects outside the Line-of-Sight of cameras is a very intriguing but also extremely challenging research topic. Recent works showed the feasibility of this idea exploiting transient imaging data produced by custom direct Time of Flight sensors. In this paper, for the first time, we tackle this problem using only data from an off-the-shelf indirect Time of Flight sensor without any further hardware requirement. We introduced a Deep Learning model able to re-frame the surfaces where light bounces happen as a virtual mirror. This modeling makes the task easier to handle and also facilitates the construction of annotated training data. From the obtained data it is possible to retrieve the depth information of the hidden scene. We also provide a first-in-its-kind synthetic dataset for the task and demonstrate the feasibility of the proposed idea over it.
When Cars meet Drones: Hyperbolic Federated Learning for Source-Free Domain Adaptation in Adverse Weather
Mar 20, 2024



In Federated Learning (FL), multiple clients collaboratively train a global model without sharing private data. In semantic segmentation, the Federated source Free Domain Adaptation (FFreeDA) setting is of particular interest, where clients undergo unsupervised training after supervised pretraining at the server side. While few recent works address FL for autonomous vehicles, intrinsic real-world challenges such as the presence of adverse weather conditions and the existence of different autonomous agents are still unexplored. To bridge this gap, we address both problems and introduce a new federated semantic segmentation setting where both car and drone clients co-exist and collaborate. Specifically, we propose a novel approach for this setting which exploits a batch-norm weather-aware strategy to dynamically adapt the model to the different weather conditions, while hyperbolic space prototypes are used to align the heterogeneous client representations. Finally, we introduce FLYAWARE, the first semantic segmentation dataset with adverse weather data for aerial vehicles.
A Modular System for Enhanced Robustness of Multimedia Understanding Networks via Deep Parametric Estimation
Feb 29, 2024In multimedia understanding tasks, corrupted samples pose a critical challenge, because when fed to machine learning models they lead to performance degradation. In the past, three groups of approaches have been proposed to handle noisy data: i) enhancer and denoiser modules to improve the quality of the noisy data, ii) data augmentation approaches, and iii) domain adaptation strategies. All the aforementioned approaches come with drawbacks that limit their applicability; the first has high computational costs and requires pairs of clean-corrupted data for training, while the others only allow deployment of the same task/network they were trained on (\ie, when upstream and downstream task/network are the same). In this paper, we propose SyMPIE to solve these shortcomings. To this end, we design a small, modular, and efficient (just 2GFLOPs to process a Full HD image) system to enhance input data for robust downstream multimedia understanding with minimal computational cost. Our SyMPIE is pre-trained on an upstream task/network that should not match the downstream ones and does not need paired clean-corrupted samples. Our key insight is that most input corruptions found in real-world tasks can be modeled through global operations on color channels of images or spatial filters with small kernels. We validate our approach on multiple datasets and tasks, such as image classification (on ImageNetC, ImageNetC-Bar, VizWiz, and a newly proposed mixed corruption benchmark named ImageNetC-mixed) and semantic segmentation (on Cityscapes, ACDC, and DarkZurich) with consistent improvements of about 5\% relative accuracy gain across the board. The code of our approach and the new ImageNetC-mixed benchmark will be made available upon publication.
ALERT-Transformer: Bridging Asynchronous and Synchronous Machine Learning for Real-Time Event-based Spatio-Temporal Data
Feb 08, 2024



We seek to enable classic processing of continuous ultra-sparse spatiotemporal data generated by event-based sensors with dense machine learning models. We propose a novel hybrid pipeline composed of asynchronous sensing and synchronous processing that combines several ideas: (1) an embedding based on PointNet models -- the ALERT module -- that can continuously integrate new and dismiss old events thanks to a leakage mechanism, (2) a flexible readout of the embedded data that allows to feed any downstream model with always up-to-date features at any sampling rate, (3) exploiting the input sparsity in a patch-based approach inspired by Vision Transformer to optimize the efficiency of the method. These embeddings are then processed by a transformer model trained for object and gesture recognition. Using this approach, we achieve performances at the state-of-the-art with a lower latency than competitors. We also demonstrate that our asynchronous model can operate at any desired sampling rate.