 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalFormer360: a transformer-based saliency estimation model for 360-degree videos
Feb 04, 2026Saliency estimation has received growing attention in recent years due to its importance in a wide range of applications. In the context of 360-degree video, it has been particularly valuable for tasks such as viewport prediction and immersive content optimization. In this paper, we propose SalFormer360, a novel saliency estimation model for 360-degree videos built on a transformer-based architecture. Our approach is based on the combination of an existing encoder architecture, SegFormer, and a custom decoder. The SegFormer model was originally developed for 2D segmentation tasks, and it has been fine-tuned to adapt it to 360-degree content. To further enhance prediction accuracy in our model, we incorporated Viewing Center Bias to reflect user attention in 360-degree environments. Extensive experiments on the three largest benchmark datasets for saliency estimation demonstrate that SalFormer360 outperforms existing state-of-the-art methods. In terms of Pearson Correlation Coefficient, our model achieves 8.4% higher performance on Sport360, 2.5% on PVS-HM, and 18.6% on VR-EyeTracking compared to previous state-of-the-art.
Split&Splat: Zero-Shot Panoptic Segmentation via Explicit Instance Modeling and 3D Gaussian Splatting
Feb 01, 20263D Gaussian Splatting (GS) enables fast and high-quality scene reconstruction, but it lacks an object-consistent and semantically aware structure. We propose Split&Splat, a framework for panoptic scene reconstruction using 3DGS. Our approach explicitly models object instances. It first propagates instance masks across views using depth, thus producing view-consistent 2D masks. Each object is then reconstructed independently and merged back into the scene while refining its boundaries. Finally, instance-level semantic descriptors are embedded in the reconstructed objects, supporting various applications, including panoptic segmentation, object retrieval, and 3D editing. Unlike existing methods, Split&Splat tackles the problem by first segmenting the scene and then reconstructing each object individually. This design naturally supports downstream tasks and allows Split&Splat to achieve state-of-the-art performance on the ScanNetv2 segmentation benchmark.
MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
Sep 17, 2025We introduce MOCHA (Multi-modal Objects-aware Cross-arcHitecture Alignment), a knowledge distillation approach that transfers region-level multimodal semantics from a large vision-language teacher (e.g., LLaVa) into a lightweight vision-only object detector student (e.g., YOLO). A translation module maps student features into a joint space, where the training of the student and translator is guided by a dual-objective loss that enforces both local alignment and global relational consistency. Unlike prior approaches focused on dense or global alignment, MOCHA operates at the object level, enabling efficient transfer of semantics without modifying the teacher or requiring textual input at inference. We validate our method across four personalized detection benchmarks under few-shot regimes. Results show consistent gains over baselines, with a +10.1 average score improvement. Despite its compact architecture, MOCHA reaches performance on par with larger multimodal models, proving its suitability for real-world deployment.
Cross-Architecture Auxiliary Feature Space Translation for Efficient Few-Shot Personalized Object Detection
Jul 01, 2024Recent years have seen object detection robotic systems deployed in several personal devices (e.g., home robots and appliances). This has highlighted a challenge in their design, i.e., they cannot efficiently update their knowledge to distinguish between general classes and user-specific instances (e.g., a dog vs. user's dog). We refer to this challenging task as Instance-level Personalized Object Detection (IPOD). The personalization task requires many samples for model tuning and optimization in a centralized server, raising privacy concerns. An alternative is provided by approaches based on recent large-scale Foundation Models, but their compute costs preclude on-device applications. In our work we tackle both problems at the same time, designing a Few-Shot IPOD strategy called AuXFT. We introduce a conditional coarse-to-fine few-shot learner to refine the coarse predictions made by an efficient object detector, showing that using an off-the-shelf model leads to poor personalization due to neural collapse. Therefore, we introduce a Translator block that generates an auxiliary feature space where features generated by a self-supervised model (e.g., DINOv2) are distilled without impacting the performance of the detector. We validate AuXFT on three publicly available datasets and one in-house benchmark designed for the IPOD task, achieving remarkable gains in all considered scenarios with excellent time-complexity trade-off: AuXFT reaches a performance of 80% its upper bound at just 32% of the inference time, 13% of VRAM and 19% of the model size.
When Cars meet Drones: Hyperbolic Federated Learning for Source-Free Domain Adaptation in Adverse Weather
Mar 20, 2024



In Federated Learning (FL), multiple clients collaboratively train a global model without sharing private data. In semantic segmentation, the Federated source Free Domain Adaptation (FFreeDA) setting is of particular interest, where clients undergo unsupervised training after supervised pretraining at the server side. While few recent works address FL for autonomous vehicles, intrinsic real-world challenges such as the presence of adverse weather conditions and the existence of different autonomous agents are still unexplored. To bridge this gap, we address both problems and introduce a new federated semantic segmentation setting where both car and drone clients co-exist and collaborate. Specifically, we propose a novel approach for this setting which exploits a batch-norm weather-aware strategy to dynamically adapt the model to the different weather conditions, while hyperbolic space prototypes are used to align the heterogeneous client representations. Finally, we introduce FLYAWARE, the first semantic segmentation dataset with adverse weather data for aerial vehicles.
A Modular System for Enhanced Robustness of Multimedia Understanding Networks via Deep Parametric Estimation
Feb 29, 2024In multimedia understanding tasks, corrupted samples pose a critical challenge, because when fed to machine learning models they lead to performance degradation. In the past, three groups of approaches have been proposed to handle noisy data: i) enhancer and denoiser modules to improve the quality of the noisy data, ii) data augmentation approaches, and iii) domain adaptation strategies. All the aforementioned approaches come with drawbacks that limit their applicability; the first has high computational costs and requires pairs of clean-corrupted data for training, while the others only allow deployment of the same task/network they were trained on (\ie, when upstream and downstream task/network are the same). In this paper, we propose SyMPIE to solve these shortcomings. To this end, we design a small, modular, and efficient (just 2GFLOPs to process a Full HD image) system to enhance input data for robust downstream multimedia understanding with minimal computational cost. Our SyMPIE is pre-trained on an upstream task/network that should not match the downstream ones and does not need paired clean-corrupted samples. Our key insight is that most input corruptions found in real-world tasks can be modeled through global operations on color channels of images or spatial filters with small kernels. We validate our approach on multiple datasets and tasks, such as image classification (on ImageNetC, ImageNetC-Bar, VizWiz, and a newly proposed mixed corruption benchmark named ImageNetC-mixed) and semantic segmentation (on Cityscapes, ACDC, and DarkZurich) with consistent improvements of about 5\% relative accuracy gain across the board. The code of our approach and the new ImageNetC-mixed benchmark will be made available upon publication.
RECALL+: Adversarial Web-based Replay for Continual Learning in Semantic Segmentation
Sep 19, 2023Catastrophic forgetting of previous knowledge is a critical issue in continual learning typically handled through various regularization strategies. However, existing methods struggle especially when several incremental steps are performed. In this paper, we extend our previous approach (RECALL) and tackle forgetting by exploiting unsupervised web-crawled data to retrieve examples of old classes from online databases. Differently from the original approach that did not perform any evaluation of the web data, here we introduce two novel approaches based on adversarial learning and adaptive thresholding to select from web data only samples strongly resembling the statistics of the no longer available training ones. Furthermore, we improved the pseudo-labeling scheme to achieve a more accurate labeling of web data that also consider classes being learned in the current step. Experimental results show that this enhanced approach achieves remarkable results, especially when multiple incremental learning steps are performed.
SynDrone -- Multi-modal UAV Dataset for Urban Scenarios
Aug 21, 2023



The development of computer vision algorithms for Unmanned Aerial Vehicles (UAVs) imagery heavily relies on the availability of annotated high-resolution aerial data. However, the scarcity of large-scale real datasets with pixel-level annotations poses a significant challenge to researchers as the limited number of images in existing datasets hinders the effectiveness of deep learning models that require a large amount of training data. In this paper, we propose a multimodal synthetic dataset containing both images and 3D data taken at multiple flying heights to address these limitations. In addition to object-level annotations, the provided data also include pixel-level labeling in 28 classes, enabling exploration of the potential advantages in tasks like semantic segmentation. In total, our dataset contains 72k labeled samples that allow for effective training of deep architectures showing promising results in synthetic-to-real adaptation. The dataset will be made publicly available to support the development of novel computer vision methods targeting UAV applications.
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Aug 09, 2023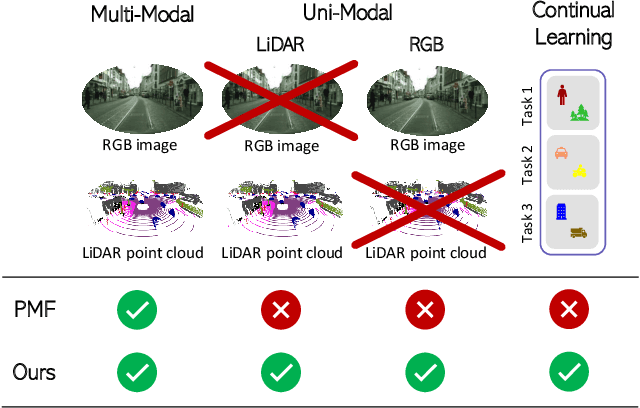

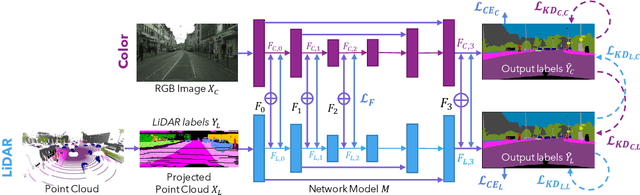

State-of-the-art multimodal semantic segmentation approaches combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. Regrettably, this strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions (night-time, rain, fog, etc.) that make the acquired information unreliable. Moreover, these architectures tend to fail in continual learning scenarios. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly-coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. This makes our model reliable even in safety-critical settings, as is the case of autonomous driving. We evaluate our approach on the SemanticKITTI dataset, comparing it with our closest competitor. We also introduce an ad-hoc continual learning scheme and show results in a class-incremental continual learning scenario that prove the effectiveness of the approach also in this setting.
DepthFormer: Multimodal Positional Encodings and Cross-Input Attention for Transformer-Based Segmentation Networks
Nov 08, 2022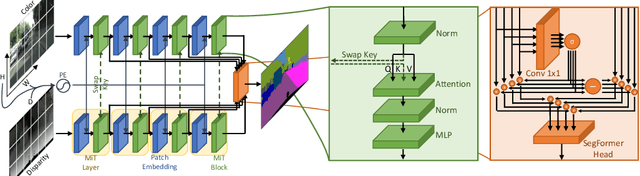


Most approaches for semantic segmentation use only information from color cameras to parse the scenes, yet recent advancements show that using depth data allows to further improve performances. In this work, we focus on transformer-based deep learning architectures, that have achieved state-of-the-art performances on the segmentation task, and we propose to employ depth information by embedding it in the positional encoding. Effectively, we extend the network to multimodal data without adding any parameters and in a natural way that makes use of the strength of transformers' self-attention modules. We also investigate the idea of performing cross-modality operations inside the attention module, swapping the key inputs between the depth and color branches. Our approach consistently improves performances on the Cityscapes benchmark.