 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
Dec 06, 2024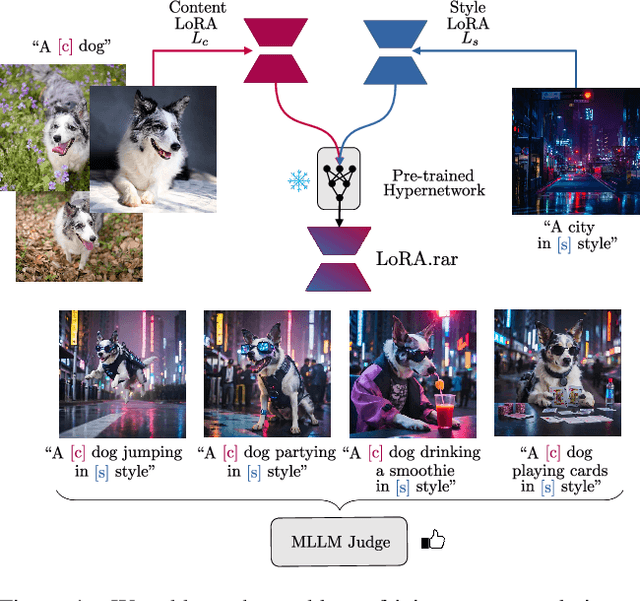
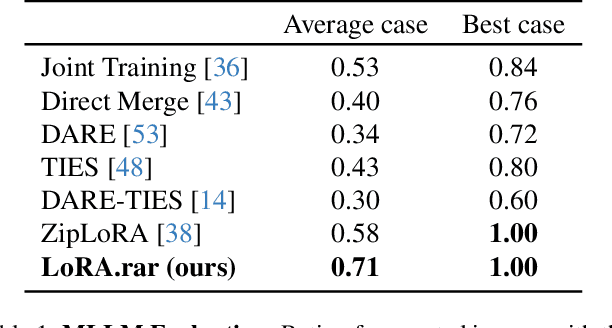
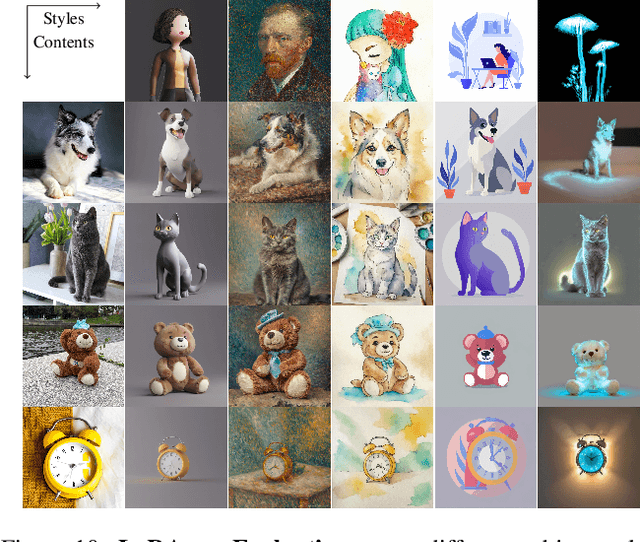
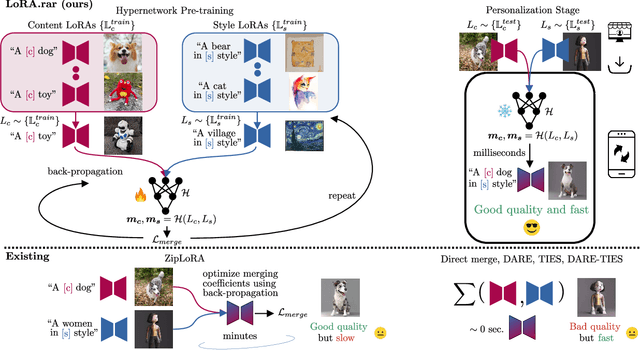
Recent advancements in image generation models have enabled personalized image creation with both user-defined subjects (content) and styles. Prior works achieved personalization by merging corresponding low-rank adaptation parameters (LoRAs) through optimization-based methods, which are computationally demanding and unsuitable for real-time use on resource-constrained devices like smartphones. To address this, we introduce LoRA$.$rar, a method that not only improves image quality but also achieves a remarkable speedup of over $4000\times$ in the merging process. LoRA$.$rar pre-trains a hypernetwork on a diverse set of content-style LoRA pairs, learning an efficient merging strategy that generalizes to new, unseen content-style pairs, enabling fast, high-quality personalization. Moreover, we identify limitations in existing evaluation metrics for content-style quality and propose a new protocol using multimodal large language models (MLLM) for more accurate assessment. Our method significantly outperforms the current state of the art in both content and style fidelity, as validated by MLLM assessments and human evaluations.
When Cars meet Drones: Hyperbolic Federated Learning for Source-Free Domain Adaptation in Adverse Weather
Mar 20, 2024



In Federated Learning (FL), multiple clients collaboratively train a global model without sharing private data. In semantic segmentation, the Federated source Free Domain Adaptation (FFreeDA) setting is of particular interest, where clients undergo unsupervised training after supervised pretraining at the server side. While few recent works address FL for autonomous vehicles, intrinsic real-world challenges such as the presence of adverse weather conditions and the existence of different autonomous agents are still unexplored. To bridge this gap, we address both problems and introduce a new federated semantic segmentation setting where both car and drone clients co-exist and collaborate. Specifically, we propose a novel approach for this setting which exploits a batch-norm weather-aware strategy to dynamically adapt the model to the different weather conditions, while hyperbolic space prototypes are used to align the heterogeneous client representations. Finally, we introduce FLYAWARE, the first semantic segmentation dataset with adverse weather data for aerial vehicles.
Source-Free Domain Adaptation for RGB-D Semantic Segmentation with Vision Transformers
May 23, 2023With the increasing availability of depth sensors, multimodal frameworks that combine color information with depth data are attracting increasing interest. In the challenging task of semantic segmentation, depth maps allow to distinguish between similarly colored objects at different depths and provide useful geometric cues. On the other side, ground truth data for semantic segmentation is burdensome to be provided and thus domain adaptation is another significant research area. Specifically, we address the challenging source-free domain adaptation setting where the adaptation is performed without reusing source data. We propose MISFIT: MultImodal Source-Free Information fusion Transformer, a depth-aware framework which injects depth information into a segmentation module based on vision transformers at multiple stages, namely at the input, feature and output levels. Color and depth style transfer helps early-stage domain alignment while re-wiring self-attention between modalities creates mixed features allowing the extraction of better semantic content. Furthermore, a depth-based entropy minimization strategy is also proposed to adaptively weight regions at different distances. Our framework, which is also the first approach using vision transformers for source-free semantic segmentation, shows noticeable performance improvements with respect to standard strategies.
Asynchronous Federated Continual Learning
Apr 07, 2023The standard class-incremental continual learning setting assumes a set of tasks seen one after the other in a fixed and predefined order. This is not very realistic in federated learning environments where each client works independently in an asynchronous manner getting data for the different tasks in time-frames and orders totally uncorrelated with the other ones. We introduce a novel federated learning setting (AFCL) where the continual learning of multiple tasks happens at each client with different orderings and in asynchronous time slots. We tackle this novel task using prototype-based learning, a representation loss, fractal pre-training, and a modified aggregation policy. Our approach, called FedSpace, effectively tackles this task as shown by the results on the CIFAR-100 dataset using 3 different federated splits with 50, 100, and 500 clients, respectively. The code and federated splits are available at https://github.com/LTTM/FedSpace.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022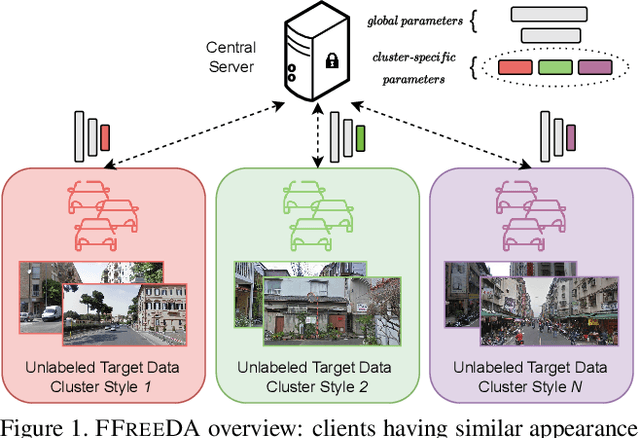
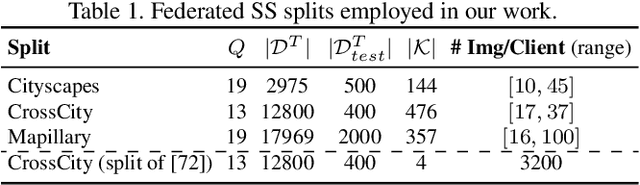
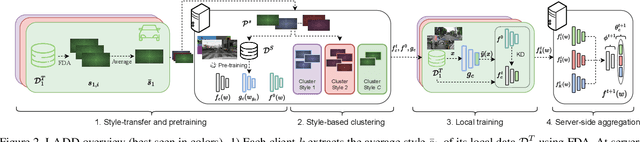
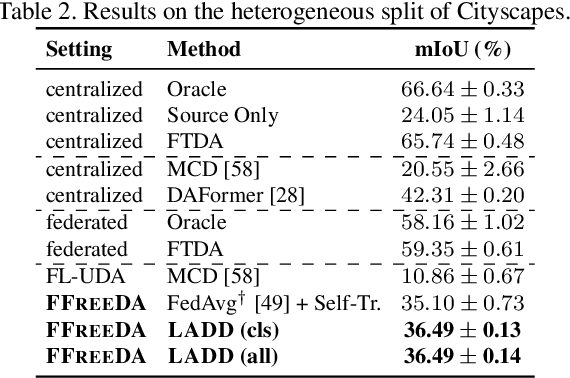
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.
Continual Coarse-to-Fine Domain Adaptation in Semantic Segmentation
Jan 18, 2022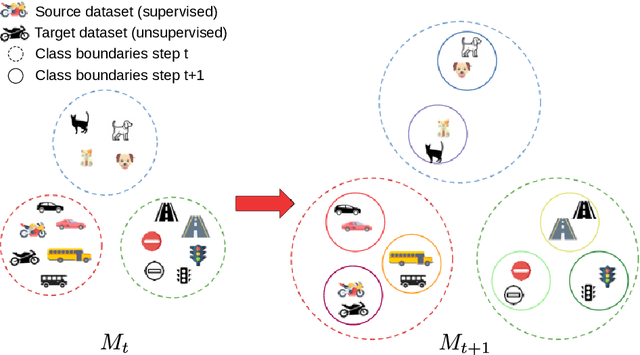
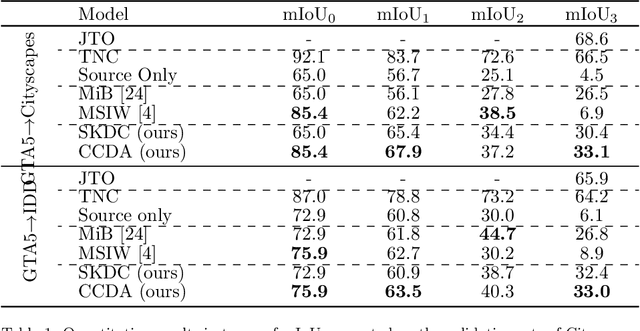
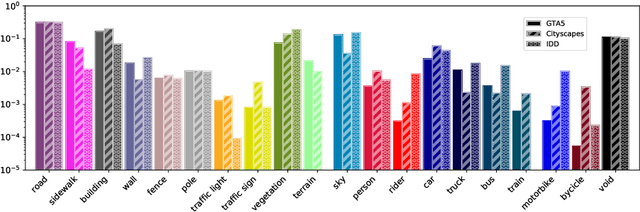
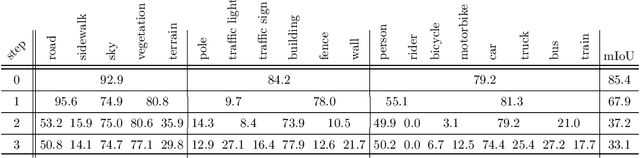
Deep neural networks are typically trained in a single shot for a specific task and data distribution, but in real world settings both the task and the domain of application can change. The problem becomes even more challenging in dense predictive tasks, such as semantic segmentation, and furthermore most approaches tackle the two problems separately. In this paper we introduce the novel task of coarse-to-fine learning of semantic segmentation architectures in presence of domain shift. We consider subsequent learning stages progressively refining the task at the semantic level; i.e., the finer set of semantic labels at each learning step is hierarchically derived from the coarser set of the previous step. We propose a new approach (CCDA) to tackle this scenario. First, we employ the maximum squares loss to align source and target domains and, at the same time, to balance the gradients between well-classified and harder samples. Second, we introduce a novel coarse-to-fine knowledge distillation constraint to transfer network capabilities acquired on a coarser set of labels to a set of finer labels. Finally, we design a coarse-to-fine weight initialization rule to spread the importance from each coarse class to the respective finer classes. To evaluate our approach, we design two benchmarks where source knowledge is extracted from the GTA5 dataset and it is transferred to either the Cityscapes or the IDD datasets, and we show how it outperforms the main competitors.