 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Appeal and Reality of Recycling LoRAs with Adaptive Merging
Feb 12, 2026The widespread availability of fine-tuned LoRA modules for open pre-trained models has led to an interest in methods that can adaptively merge LoRAs to improve performance. These methods typically include some way of selecting LoRAs from a pool and tune merging coefficients based on a task-specific dataset. While adaptive merging methods have demonstrated improvements in some settings, no past work has attempted to recycle LoRAs found "in the wild" on model repositories like the Hugging Face Hub. To address this gap, we consider recycling from a pool of nearly 1,000 user-contributed LoRAs trained from the Llama 3.1 8B-Instruct language model. Our empirical study includes a range of adaptive and non-adaptive merging methods in addition to a new method designed via a wide search over the methodological design space. We demonstrate that adaptive merging methods can improve performance over the base model but provide limited benefit over training a new LoRA on the same data used to set merging coefficients. We additionally find not only that the specific choice of LoRAs to merge has little importance, but that using LoRAs with randomly initialized parameter values yields similar performance. This raises the possibility that adaptive merging from recycled LoRAs primarily works via some kind of regularization effect, rather than by enabling positive cross-task transfer. To better understand why past work has proven successful, we confirm that positive transfer is indeed possible when there are highly relevant LoRAs in the pool. We release the model checkpoints and code online.
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation
Feb 11, 2026Looped Transformers have emerged as an efficient and powerful class of models for reasoning in the language domain. Recent studies show that these models achieve strong performance on algorithmic and reasoning tasks, suggesting that looped architectures possess an inductive bias toward latent reasoning. However, prior approaches fix the number of loop iterations during training and inference, leaving open the question of whether these models can flexibly adapt their computational depth under variable compute budgets. We introduce LoopFormer, a looped Transformer trained on variable-length trajectories to enable budget-conditioned reasoning. Our core contribution is a shortcut-consistency training scheme that aligns trajectories of different lengths, ensuring that shorter loops yield informative representations while longer loops continue to refine them. LoopFormer conditions each loop on the current time and step size, enabling representations to evolve consistently across trajectories of varying length rather than drifting or stagnating. Empirically, LoopFormer demonstrates robust performance on language modeling and reasoning benchmarks even under aggressive compute constraints, while scaling gracefully with additional budget. These results show that looped Transformers are inherently suited for adaptive language modeling, opening a path toward controllable and budget-aware large language models.
FlexRank: Nested Low-Rank Knowledge Decomposition for Adaptive Model Deployment
Feb 02, 2026The growing scale of deep neural networks, encompassing large language models (LLMs) and vision transformers (ViTs), has made training from scratch prohibitively expensive and deployment increasingly costly. These models are often used as computational monoliths with fixed cost, a rigidity that does not leverage overparametrized architectures and largely hinders adaptive deployment across different cost budgets. We argue that importance-ordered nested components can be extracted from pretrained models, and selectively activated on the available computational budget. To this end, our proposed FlexRank method leverages low-rank weight decomposition with nested, importance-based consolidation to extract submodels of increasing capabilities. Our approach enables a "train-once, deploy-everywhere" paradigm that offers a graceful trade-off between cost and performance without training from scratch for each budget - advancing practical deployment of large models.
TokSuite: Measuring the Impact of Tokenizer Choice on Language Model Behavior
Dec 23, 2025Tokenizers provide the fundamental basis through which text is represented and processed by language models (LMs). Despite the importance of tokenization, its role in LM performance and behavior is poorly understood due to the challenge of measuring the impact of tokenization in isolation. To address this need, we present TokSuite, a collection of models and a benchmark that supports research into tokenization's influence on LMs. Specifically, we train fourteen models that use different tokenizers but are otherwise identical using the same architecture, dataset, training budget, and initialization. Additionally, we curate and release a new benchmark that specifically measures model performance subject to real-world perturbations that are likely to influence tokenization. Together, TokSuite allows robust decoupling of the influence of a model's tokenizer, supporting a series of novel findings that elucidate the respective benefits and shortcomings of a wide range of popular tokenizers.
Efficient Model Editing with Task-Localized Sparse Fine-tuning
Apr 03, 2025Task arithmetic has emerged as a promising approach for editing models by representing task-specific knowledge as composable task vectors. However, existing methods rely on network linearization to derive task vectors, leading to computational bottlenecks during training and inference. Moreover, linearization alone does not ensure weight disentanglement, the key property that enables conflict-free composition of task vectors. To address this, we propose TaLoS which allows to build sparse task vectors with minimal interference without requiring explicit linearization and sharing information across tasks. We find that pre-trained models contain a subset of parameters with consistently low gradient sensitivity across tasks, and that sparsely updating only these parameters allows for promoting weight disentanglement during fine-tuning. Our experiments prove that TaLoS improves training and inference efficiency while outperforming current methods in task addition and negation. By enabling modular parameter editing, our approach fosters practical deployment of adaptable foundation models in real-world applications.
Interaction-Aware Gaussian Weighting for Clustered Federated Learning
Feb 05, 2025



Federated Learning (FL) emerged as a decentralized paradigm to train models while preserving privacy. However, conventional FL struggles with data heterogeneity and class imbalance, which degrade model performance. Clustered FL balances personalization and decentralized training by grouping clients with analogous data distributions, enabling improved accuracy while adhering to privacy constraints. This approach effectively mitigates the adverse impact of heterogeneity in FL. In this work, we propose a novel clustered FL method, FedGWC (Federated Gaussian Weighting Clustering), which groups clients based on their data distribution, allowing training of a more robust and personalized model on the identified clusters. FedGWC identifies homogeneous clusters by transforming individual empirical losses to model client interactions with a Gaussian reward mechanism. Additionally, we introduce the Wasserstein Adjusted Score, a new clustering metric for FL to evaluate cluster cohesion with respect to the individual class distribution. Our experiments on benchmark datasets show that FedGWC outperforms existing FL algorithms in cluster quality and classification accuracy, validating the efficacy of our approach.
Beyond Local Sharpness: Communication-Efficient Global Sharpness-aware Minimization for Federated Learning
Dec 04, 2024



Federated learning (FL) enables collaborative model training with privacy preservation. Data heterogeneity across edge devices (clients) can cause models to converge to sharp minima, negatively impacting generalization and robustness. Recent approaches use client-side sharpness-aware minimization (SAM) to encourage flatter minima, but the discrepancy between local and global loss landscapes often undermines their effectiveness, as optimizing for local sharpness does not ensure global flatness. This work introduces FedGloSS (Federated Global Server-side Sharpness), a novel FL approach that prioritizes the optimization of global sharpness on the server, using SAM. To reduce communication overhead, FedGloSS cleverly approximates sharpness using the previous global gradient, eliminating the need for additional client communication. Our extensive evaluations demonstrate that FedGloSS consistently reaches flatter minima and better performance compared to state-of-the-art FL methods across various federated vision benchmarks.
Finding Lottery Tickets in Vision Models via Data-driven Spectral Foresight Pruning
Jun 03, 2024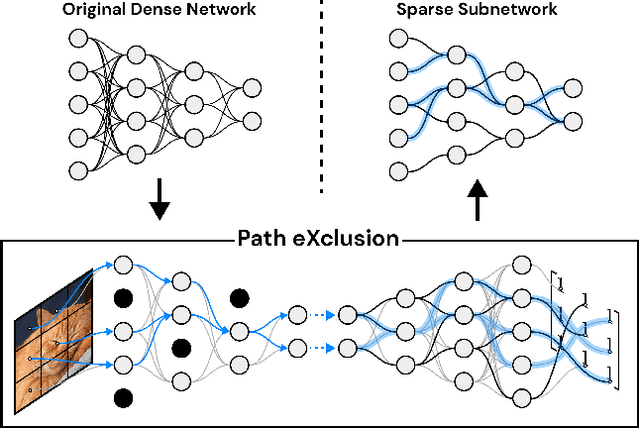
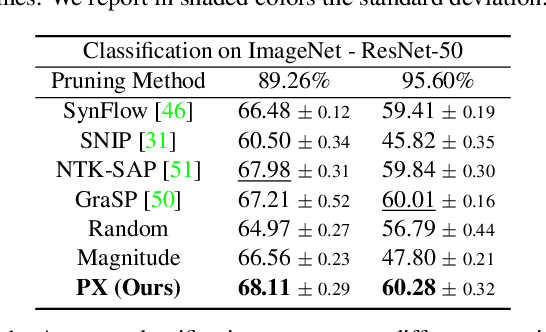
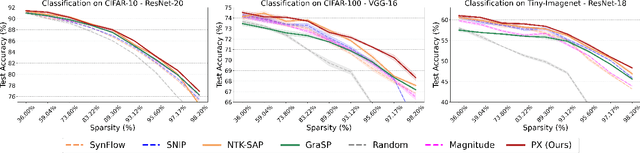
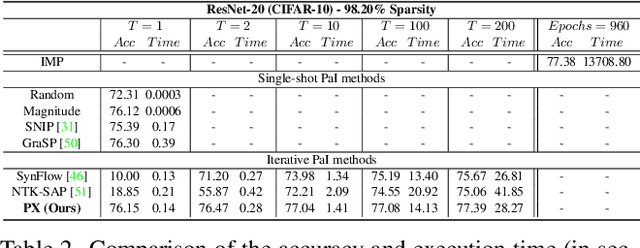
Recent advances in neural network pruning have shown how it is possible to reduce the computational costs and memory demands of deep learning models before training. We focus on this framework and propose a new pruning at initialization algorithm that leverages the Neural Tangent Kernel (NTK) theory to align the training dynamics of the sparse network with that of the dense one. Specifically, we show how the usually neglected data-dependent component in the NTK's spectrum can be taken into account by providing an analytical upper bound to the NTK's trace obtained by decomposing neural networks into individual paths. This leads to our Path eXclusion (PX), a foresight pruning method designed to preserve the parameters that mostly influence the NTK's trace. PX is able to find lottery tickets (i.e. good paths) even at high sparsity levels and largely reduces the need for additional training. When applied to pre-trained models it extracts subnetworks directly usable for several downstream tasks, resulting in performance comparable to those of the dense counterpart but with substantial cost and computational savings. Code available at: https://github.com/iurada/px-ntk-pruning
Accelerating Heterogeneous Federated Learning with Closed-form Classifiers
Jun 03, 2024Federated Learning (FL) methods often struggle in highly statistically heterogeneous settings. Indeed, non-IID data distributions cause client drift and biased local solutions, particularly pronounced in the final classification layer, negatively impacting convergence speed and accuracy. To address this issue, we introduce Federated Recursive Ridge Regression (Fed3R). Our method fits a Ridge Regression classifier computed in closed form leveraging pre-trained features. Fed3R is immune to statistical heterogeneity and is invariant to the sampling order of the clients. Therefore, it proves particularly effective in cross-device scenarios. Furthermore, it is fast and efficient in terms of communication and computation costs, requiring up to two orders of magnitude fewer resources than the competitors. Finally, we propose to leverage the Fed3R parameters as an initialization for a softmax classifier and subsequently fine-tune the model using any FL algorithm (Fed3R with Fine-Tuning, Fed3R+FT). Our findings also indicate that maintaining a fixed classifier aids in stabilizing the training and learning more discriminative features in cross-device settings. Official website: https://fed-3r.github.io/.
PEM: Prototype-based Efficient MaskFormer for Image Segmentation
Mar 01, 2024



Recent transformer-based architectures have shown impressive results in the field of image segmentation. Thanks to their flexibility, they obtain outstanding performance in multiple segmentation tasks, such as semantic and panoptic, under a single unified framework. To achieve such impressive performance, these architectures employ intensive operations and require substantial computational resources, which are often not available, especially on edge devices. To fill this gap, we propose Prototype-based Efficient MaskFormer (PEM), an efficient transformer-based architecture that can operate in multiple segmentation tasks. PEM proposes a novel prototype-based cross-attention which leverages the redundancy of visual features to restrict the computation and improve the efficiency without harming the performance. In addition, PEM introduces an efficient multi-scale feature pyramid network, capable of extracting features that have high semantic content in an efficient way, thanks to the combination of deformable convolutions and context-based self-modulation. We benchmark the proposed PEM architecture on two tasks, semantic and panoptic segmentation, evaluated on two different datasets, Cityscapes and ADE20K. PEM demonstrates outstanding performance on every task and dataset, outperforming task-specific architectures while being comparable and even better than computationally-expensive baselines.