 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelet Scattering Transform and Fourier Representation for Offline Detection of Malicious Clients in Federated Learning
Jun 11, 2025Federated Learning (FL) enables the training of machine learning models across decentralized clients while preserving data privacy. However, the presence of anomalous or corrupted clients - such as those with faulty sensors or non representative data distributions - can significantly degrade model performance. Detecting such clients without accessing raw data remains a key challenge. We propose WAFFLE (Wavelet and Fourier representations for Federated Learning) a detection algorithm that labels malicious clients {\it before training}, using locally computed compressed representations derived from either the Wavelet Scattering Transform (WST) or the Fourier Transform. Both approaches provide low-dimensional, task-agnostic embeddings suitable for unsupervised client separation. A lightweight detector, trained on a distillated public dataset, performs the labeling with minimal communication and computational overhead. While both transforms enable effective detection, WST offers theoretical advantages, such as non-invertibility and stability to local deformations, that make it particularly well-suited to federated scenarios. Experiments on benchmark datasets show that our method improves detection accuracy and downstream classification performance compared to existing FL anomaly detection algorithms, validating its effectiveness as a pre-training alternative to online detection strategies.
Interaction-Aware Gaussian Weighting for Clustered Federated Learning
Feb 05, 2025



Federated Learning (FL) emerged as a decentralized paradigm to train models while preserving privacy. However, conventional FL struggles with data heterogeneity and class imbalance, which degrade model performance. Clustered FL balances personalization and decentralized training by grouping clients with analogous data distributions, enabling improved accuracy while adhering to privacy constraints. This approach effectively mitigates the adverse impact of heterogeneity in FL. In this work, we propose a novel clustered FL method, FedGWC (Federated Gaussian Weighting Clustering), which groups clients based on their data distribution, allowing training of a more robust and personalized model on the identified clusters. FedGWC identifies homogeneous clusters by transforming individual empirical losses to model client interactions with a Gaussian reward mechanism. Additionally, we introduce the Wasserstein Adjusted Score, a new clustering metric for FL to evaluate cluster cohesion with respect to the individual class distribution. Our experiments on benchmark datasets show that FedGWC outperforms existing FL algorithms in cluster quality and classification accuracy, validating the efficacy of our approach.
Wavelet Scattering Transform for Bioacustics: Application to Watkins Marine Mammal Sound Database
Feb 20, 2024

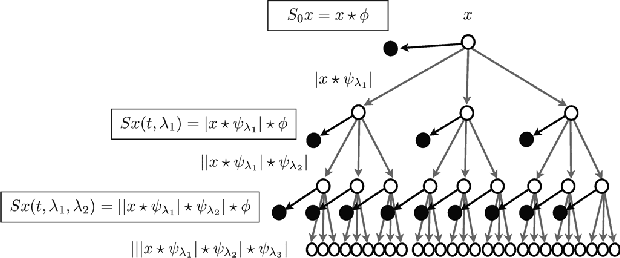

Marine mammal communication is a complex field, hindered by the diversity of vocalizations and environmental factors. The Watkins Marine Mammal Sound Database (WMMD) is an extensive labeled dataset used in machine learning applications. However, the methods for data preparation, preprocessing, and classification found in the literature are quite disparate. This study first focuses on a brief review of the state-of-the-art benchmarks on the dataset, with an emphasis on clarifying data preparation and preprocessing methods. Subsequently, we propose the application of the Wavelet Scattering Transform (WST) in place of standard methods based on the Short-Time Fourier Transform (STFT). The study also tackles a classification task using an ad-hoc deep architecture with residual layers. We outperform the existing classification architecture by $6\%$ in accuracy using WST and $8\%$ using Mel spectrogram preprocessing, effectively reducing by half the number of misclassified samples, and reaching a top accuracy of $96\%$.